机器学习:算法与应用 by XDU 2022冬季课程笔记1:线性回归与逻辑回归
Posted spongiaaa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习:算法与应用 by XDU 2022冬季课程笔记1:线性回归与逻辑回归相关的知识,希望对你有一定的参考价值。
机器学习:[算法与应用 by XDU 2022冬季课程笔记集合]
文章目录
1.回顾与总览
上节课程概括了整个机器学习算法流程,以及算法中最重要的三个方面:

本节课程也基本按照这三个方面展开叙述。包括线性模型与线性回归的算法流程,两种线性回归变体(Ridge与Lasso),以及基本的逻辑回归模型及其解法。
2.线性模型与线性回归(Linear Regression)
-
线性模型的基本形式:
f(x)=βTx + b(对应上面的重点1)
此处β与x均为d维向量,x=[x1,x2…xd]被称作一个特征向量,每个特征向量有d个特征维度。这d个x(即一个特征向量x)对应着一个标签y,多个特征向量构成我们的数据集X(是个矩阵,多个向量构成的嘛),x(i)表示矩阵中第i个特征向量,y(i)表示该特征向量对应的标签。 -
线性回归训练流程
若共有n个特征向量,线性模型的训练流程就是根据已有的数据集x(1),x(2)…x(n)以及他们对应的标签y(1),y(2)…y(n)拟合出一个模型f(x),这个模型可以预测新输入的无标签的特征向量xnew所对应的标签 y ^ \\hat y y^。我们选取一个损失函数(对应上面的重点2)作为最小化目标,通过最小化方法(对应上面的重点3)使得模型参数与现有数据集X的拟合程度最高,即获取最优模型。 -
损失函数与求解算法
- 模型有关的参数设置如图所示
- 损失函数选取RSS方差和,也就是将数据集X中的每个特征向量x代入模型,将求解到的 y ^ \\hat y y^(即模型的预测结果)与特征向量实际的标签y取平方差。
- 求解算法选取梯度下降法,这是机器学习中最常用的一种优化方法,网上有很多详细的介绍,在此不展开赘述。梯度下降的作用是调整模型的参数,使在数据集上的损失函数达到最小值。在此仅了解作用并不影响后续课程的理解。(损失函数的自变量是模型的参数β,数据集和标签已经确定了嘛)

-
由于线性模型的损失函数比较简单,可以直接求出解析解(即函数取最小值时对应的自变量β),由于设计矩阵与向量,推导需要一定线性代数基础,下面是我的推导过程。


-
解的物理意义
argmin RSS(β)指的是当RSS最小时取得的 β 值 β*
由于XT(Xβ-y)=0,也就是y- y ^ \\hat y y^(这是个向量)和z1…zd(这也是个向量)张成的空间垂直3。
z的定义如下:
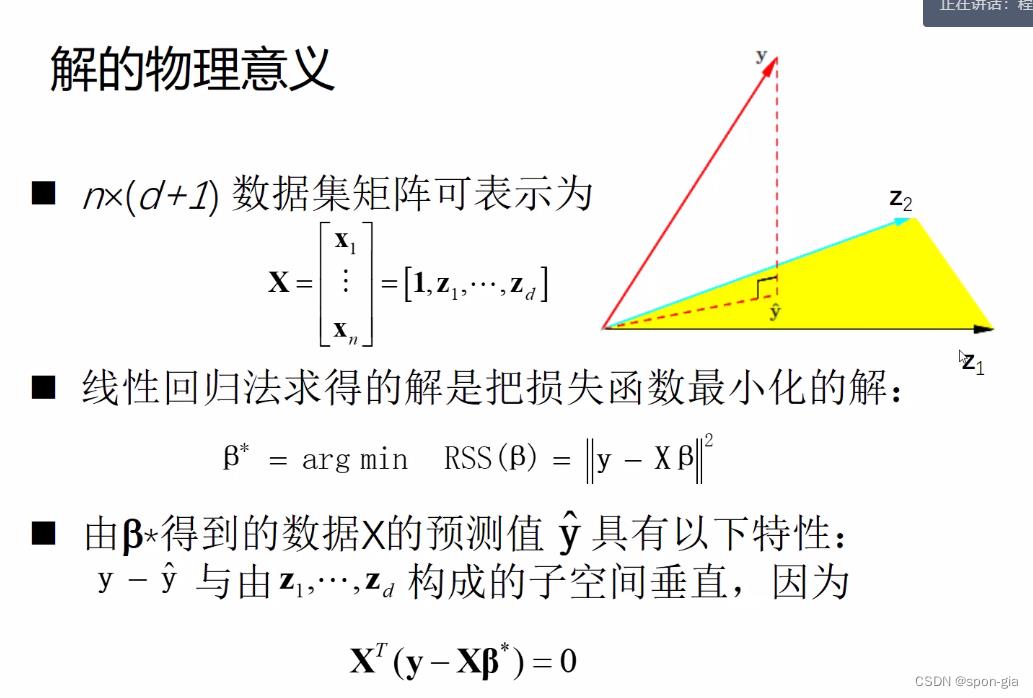
当上式中的z1…zn关联性很强的时候,ZZT为退化矩阵,模型对微小的扰动反应很大,容易产生过拟合4现象。因此,引入两种线性回归变种解决这个问题。
(严谨的数学证明涉及矩阵退化、秩运算云云,我实在没有能力完全看懂,如果有对线性代数掌握较深的同学可以分享)
分享一个过拟合的例子,蓝色的线是过拟合的模型。(来自吴恩达Coursera:machine learning):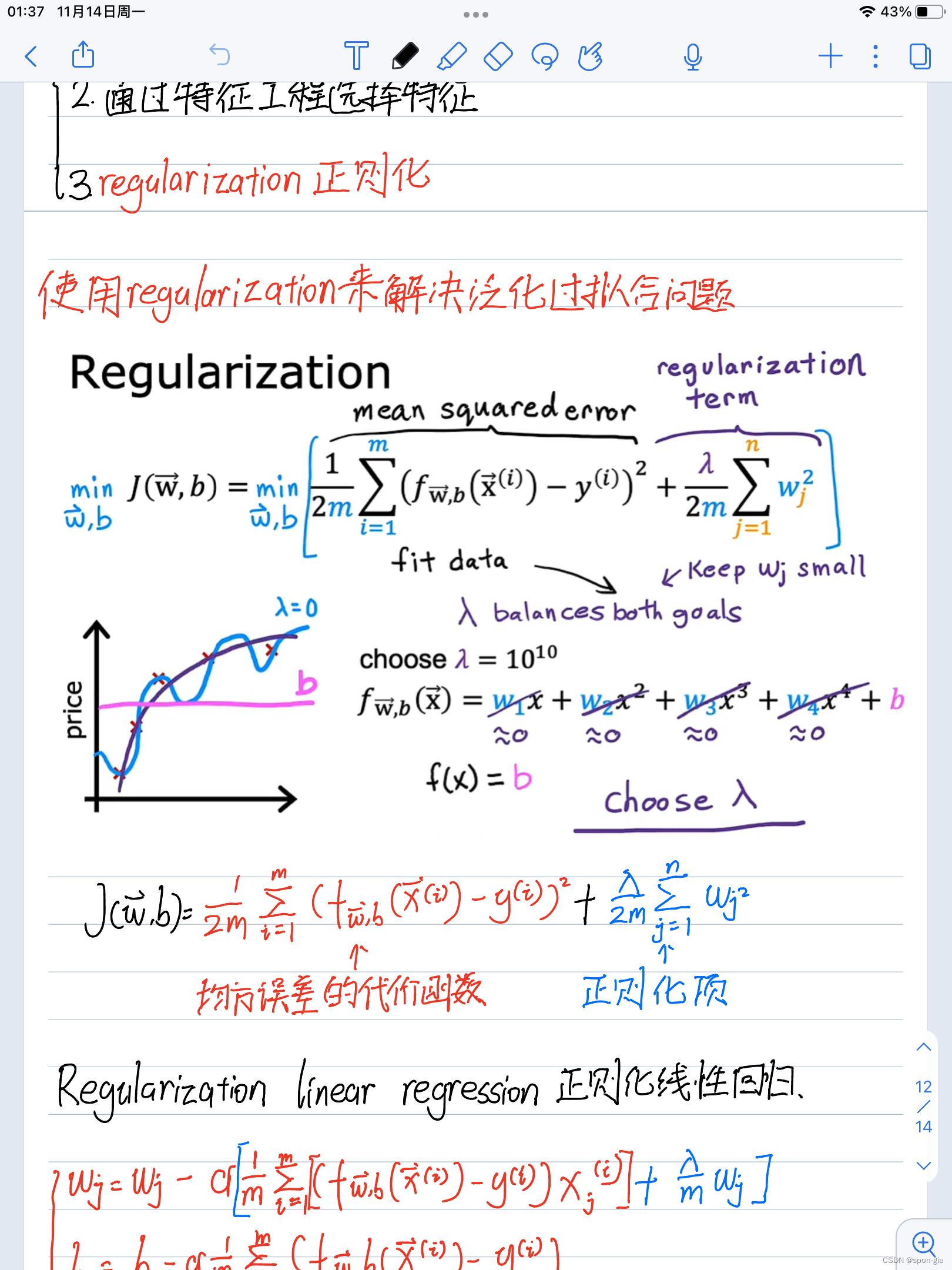
- Ridge线性回归(L2正则化)
岭线性回归模型与原模型的区别是多了一个正则化项λβTβ。
对这个公式的直观感知就是损失函数加上了模型参数的平方和 ∑ i = 1 d \\sum_i=1^d ∑i=1dwi²,即最小化目标包含了模型的参数,从而达到权值衰减(weight decay)的目的,来规避过拟合。
新的损失函数求导过程与之前类似,此处不再赘述

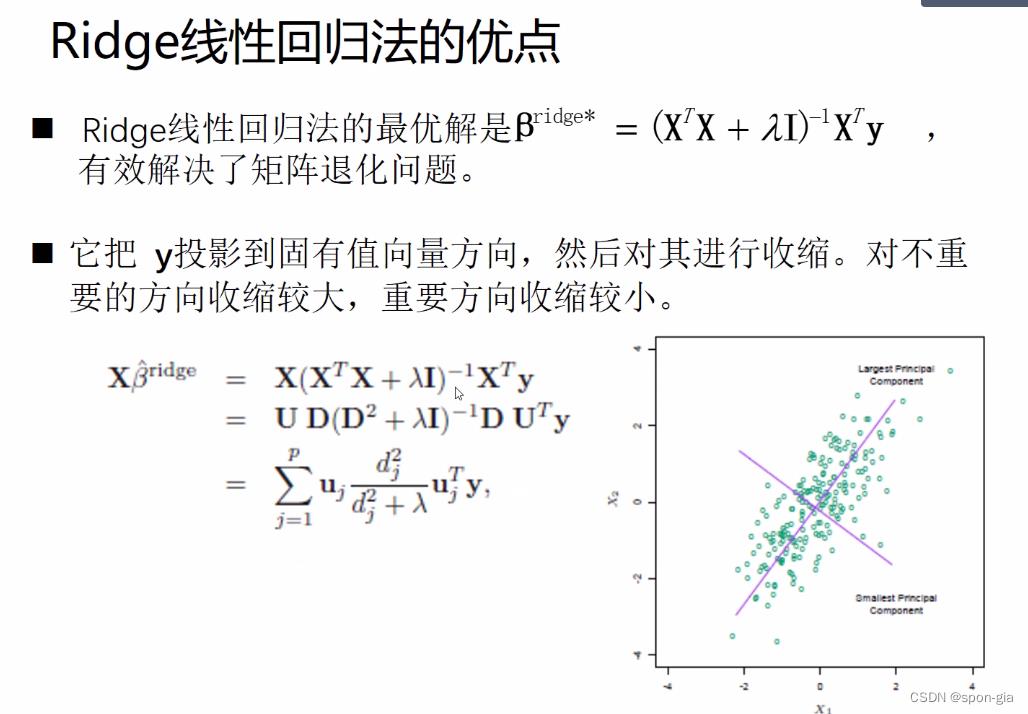
ridge线性回归法防止矩阵退化的严格证明涉及SVD奇异值分解,矩阵退化,正定矩阵云云,我的线代真的很差………这里给一个等高线的解释。
等高线表示的是损失函数的取值,同一条等高线上损失函数的取值相等。下图右边表示ridge线性回归,其损失函数左项和正则化项的梯度下降目的地不同,达到防止过拟合的效果。
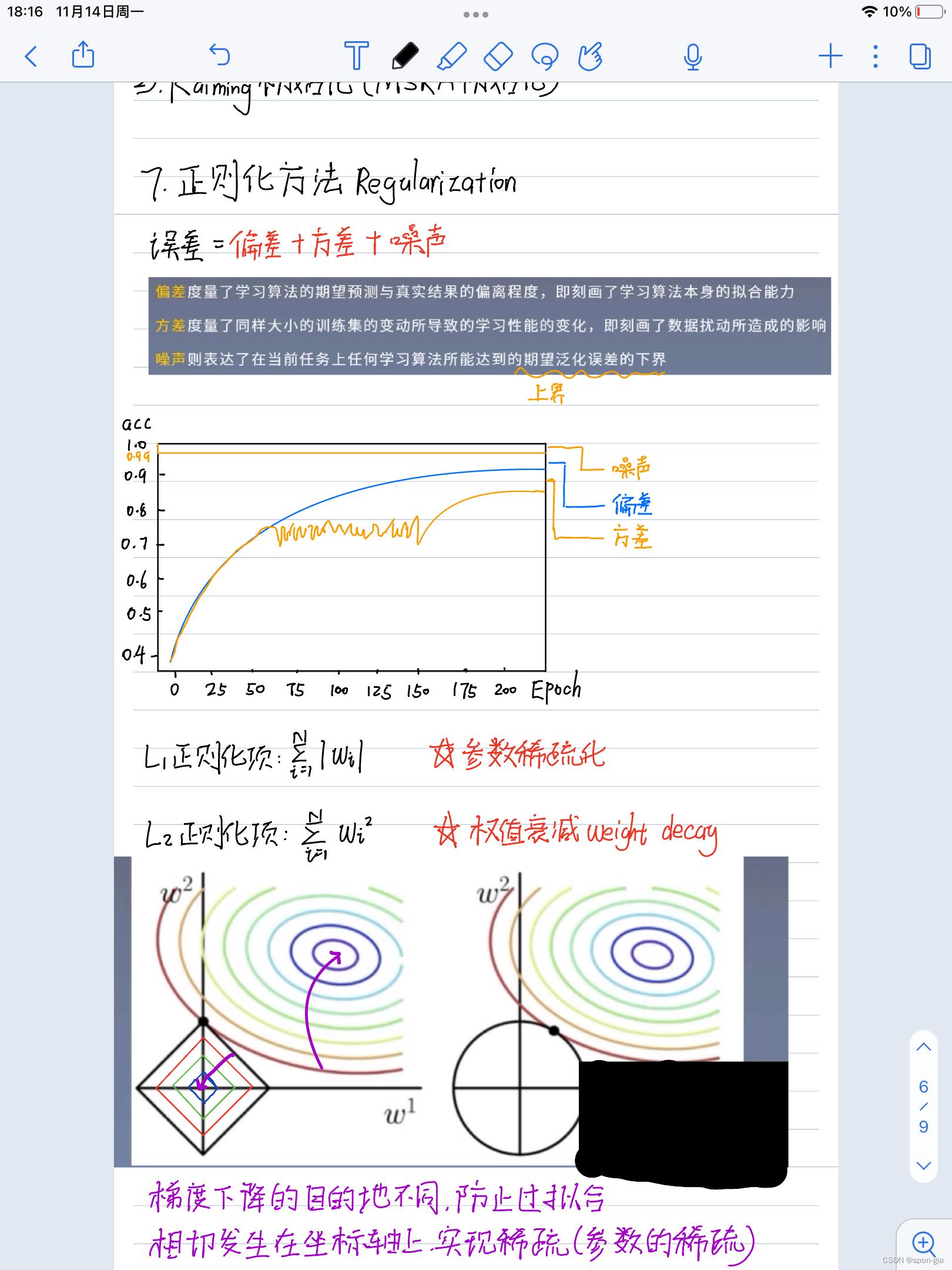
7.Lasso线性回归(L1正则化)
Lasso线性回归与原模型的区别是多了一个正则化项λ|β|
对这个公式的直观感知就是损失函数加上了模型参数的绝对值和
∑
i
=
1
d
\\sum_i=1^d
∑i=1d|wi|,这样正则化后的损失函数不存在解析解,其求解过程需要QP二次规划算法5。
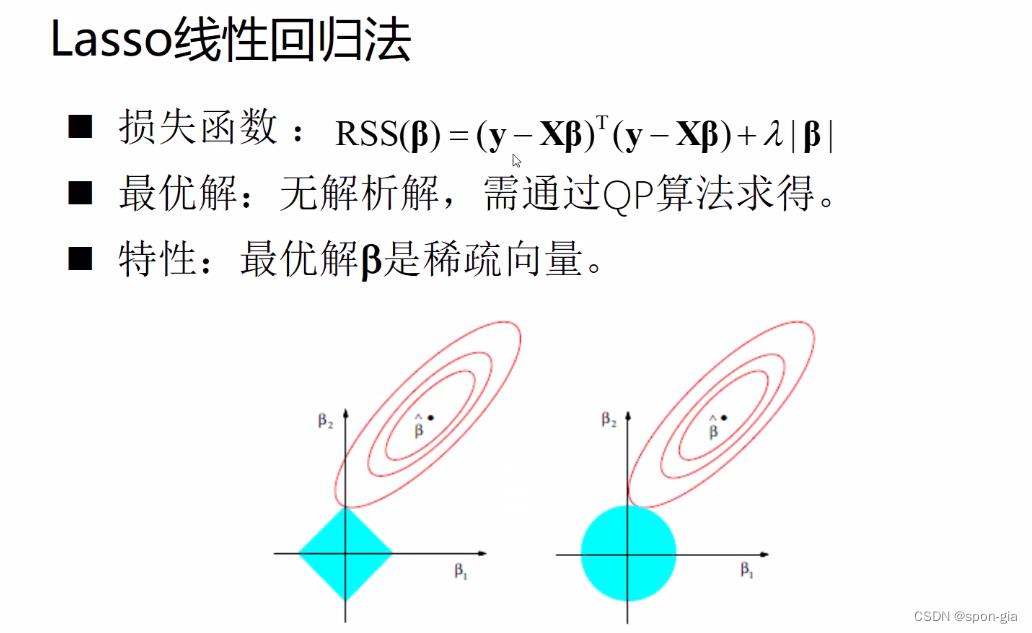
上图左侧是Lasso线性回归模型损失函数的等高线图,在左项与正则化项相切处取得损失函数的最小值,这个相切处一般是坐标轴上的点,达到了参数置零的效果,从而实现参数稀疏化,从而实现正则化防止过拟合。(为啥稀疏向量可以防止过拟合我也不懂)
- 基于线性回归的分类器
使用独热编码表示一个特征向量的分类,则全体训练集的Y变成一个矩阵,使用上述线性回归模型可以求得解析解B*=(XTX)-1XTY。对于待遇测的新数据x,代入模型后求得预测向量 y ^ \\hat y y^,该向量的最大值对应的K即为模型输出的分类结果。
该分类器的缺点有两个:- RSS损失函数并不适用于分类算法;
- 该分类器只能解决线性可分问题。

3.逻辑回归(Logistic Regression)分类器
-
对于K类分类目标,每一类都有一个对应的线性模型,他们的参数分别是βk0(对应线性模型中的b)和βk(对应线性模型中的向量参数β)
把待预测的特征向量x输入每一类分类器,得出的数据就是这个x属于这一类的概率。(未归一化)

-
下一步要做的事情是使输出满足概率形式,即求和为1的形式。使用上节课讲过的softmax进行变换,下面给出我的softmax笔记:


可以发现这两个变化是相同的,都是将所有模型输出结果取指数后求和作为分母(老师的笔记中最后一类的模型输出是log1=0,取指数即e0=1,因此分母有个1),分子是这一类模型的输出结果取指数,这种操作可以将输出转化为概率形式。 -
二项逻辑回归模型
就是当分类项数只有两项(K=2)时的特殊情况,右边的函数是sigmoid函数,相当于将线性回归模型的输出当做自变量放入sigmoid中激活,使得总逻辑回归模型的输出是sigmoid的形式。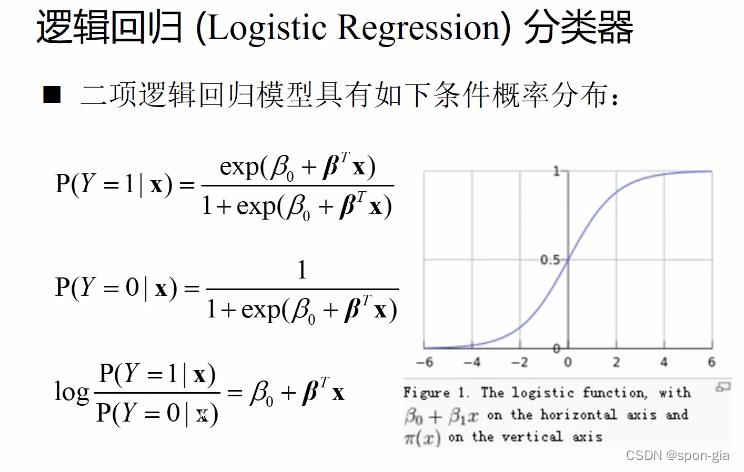
-
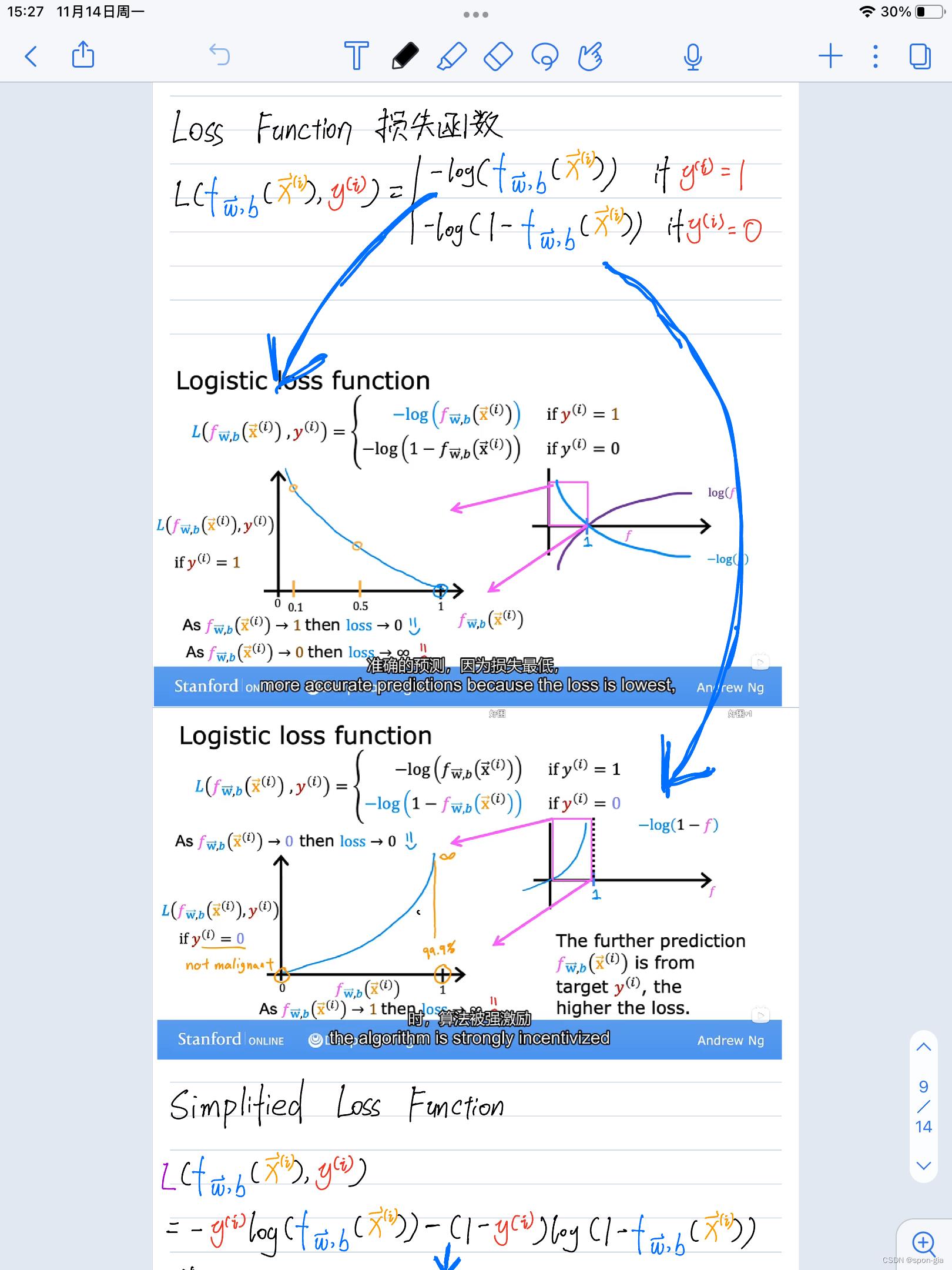
逻辑回归模型的损失函数
选用对数似然函数作为逻辑回归模型的损失函数,如下所示。
这里应该是要以最大化似然函数(?不确定)作为目标,我的概率论学的很差……

下面贴出我的二项逻辑回归损失函数笔记
先看最下面的simplified loss funcion部分,与老师给出的二项逻辑回归损失函数仅差一个负号,对于该损失函数的解释和由来在上面。
-
优化算法:牛顿迭代法
机器学习优化方法的主流派系就是梯度下降法和牛顿迭代法,网上有很多介绍,在此不展开赘述。

4.总结
机器学习课程内容繁杂,需要较扎实的线性代数与统计学基础。同学们可以关注宏观的课程整体逻辑与大致的实现流程,对于一些复杂算法可以先知其然,了解它的作用和条件等,课后再深入其原理的学习。
以上是关于机器学习:算法与应用 by XDU 2022冬季课程笔记1:线性回归与逻辑回归的主要内容,如果未能解决你的问题,请参考以下文章
从零开始CS224W-图机器学习-2021冬季学习笔记13.2:Community Structure in Networks——BigCLAM算法
2021-2022年度第三届全国大学生算法设计与编程挑战赛(冬季赛)-正式赛 部分题解
2021-2022年度第三届全国大学生算法设计与编程挑战赛(冬季赛正式赛) 部分题题解