数据结构之病毒感染检测问题
Posted 迷途纸鸢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构之病毒感染检测问题相关的知识,希望对你有一定的参考价值。
问题描述:
医学研究者最近发现了某新病毒,通过对这些病毒的分析,得知他们的DNA序列都是环状的。现在研究者已收集了大量
的病毒DNA和人的DNA数据,想快速检测出这些人是否感染了相应的病毒。为了研究方便,研究者将人的DNA和病毒DNA
均表示成由一些字母组成的字符串序列,然后检测眸中病毒DNA序列是否在患者的DNA序列中出现过,如果出现过,则
此人感染了该病毒,否则没有感染。例如,假设病毒的DNA序列为baa,患者1的DNA序列为aaabbba,则感染;患者2的
DNA序列为babbba,则未感染。(注意,恩德DNA序列式线性的,而病毒的DNA序列为环状的)。
Input:
abbab abbabaab
baa cacdvcabacsd
abc def
0 0
Output:
YES
NO
NO
BF算法(即遍历法):
1 #include "stdafx.h" 2 #include<iostream> 3 #include<cstring> 4 #include<string> 5 using namespace std; 6 7 int Index_BF(const string &str1, const string &str2, int pos) 8 { 9 10 int i = pos; 11 int j = 0; 12 int len1 = str1.size(); 13 int len2 = str2.size(); 14 while (i<len1&&j<len2) 15 { 16 if (str1[i] == str2[j]) 17 { 18 i++; 19 j++; 20 } 21 else 22 { 23 i = i - j + 1; 24 j = 0; 25 } 26 } 27 if (j >= len2) 28 return i - len2; 29 else 30 return -1; 31 } 32 33 int main() 34 { 35 int pos = 0; 36 string str1; 37 string str2; 38 while (cin >> str2 >> str1) 39 { 40 if (str1 == "0"&&str2 == "0")break; 41 int result = Index_BF(str1, str2, pos); 42 if (result != -1) 43 cout << "YES" << endl; 44 else 45 cout << "NO" << endl; 46 } 47 return 0; 48 }
KMP算法:
1 #include "stdafx.h" 2 #include<iostream> 3 #include<cstring> 4 #include<string> 5 #include<fstream> 6 using namespace std; 7 8 void get_next(string str2,int *next) 9 { 10 int i,j; 11 i=1; 12 j=0; 13 next[1]=0; 14 while(i<str2.size()) 15 { 16 if(j==0||str2[i]==str2[j]) 17 { 18 ++i; 19 ++j; 20 if(str2[i]!=str2[j]) 21 next[i]=j; 22 else 23 next[i]=next[j]; 24 } 25 else 26 j=next[j]; 27 } 28 } 29 30 int kmp(string &str1,string &str2,int pos) 31 { 32 33 int i=pos; 34 int j=0; 35 int next[255]; 36 get_next(str2,next); 37 int len1=str1.size(); 38 int len2=str2.size(); 39 while(i<len1&&j<len2) 40 { 41 if(j==0||str1[i]==str2[j]) 42 { 43 i++; 44 j++; 45 } 46 else 47 { 48 j=next[j]; 49 } 50 } 51 if(j>=len2) 52 return i-len2; 53 else 54 return -1; 55 } 56 57 int main() 58 { 59 int pos=0 ; 60 string str1; 61 string str2; 62 while(cin >>str2>>str1) 63 { 64 if(str1=="0"&&str2=="0")break; 65 int result=kmp(str1,str2,pos); 66 if(result!=-1) 67 cout<<"YES"<<endl; 68 else 69 cout<<"NO"<<endl; 70 } 71 return 0; 72 }
对于正常的字符串模式匹配,主串长度为m,子串为n,时间复杂度会到达O(m*n),而如果用KMP算法,复杂度将会减少线型时间O(m+n)。
设主串为ptr="ababaaababaa";,要比较的子串为a=“aab”;
KMP算法用到了next数组,然后利用next数组的值来提高匹配速度,我首先讲一下next数组怎么求,之后再讲匹配方式。
NEXT[]详解:
next数组详解
首先是理解KMP算法的第一个难关是next数组每个值的确定,这个问题困恼我很长时间,尤其是对照着代码一行一行分析,很容易把自己绕进去。
定义一串字符串
ptr = "ababaaababaa";
next[i](i从1开始算)代表着,除去第i个数,在一个字符串里面从第一个数到第(i-1)字符串前缀与后缀最长重复的个数。
什么是前缀?
在“aba”中,前缀就是“ab”,除去最后一个字符的剩余字符串。
同理可以理解后缀。除去第一个字符的后面全部的字符串。
在“aba”中,前缀是“ab”,后缀是“ba”,那么两者最长的子串就是“a”;
在“ababa”中,前缀是“abab”,后缀是“baba”,二者最长重复子串是“aba”;
在“abcabcdabc”中,前缀是“abcabcdab”,后缀是“bcabcdabc”,二者最长重复的子串是“abc”;
这里有一点要注意,前缀必须要从头开始算,后缀要从最后一个数开始算,中间截一段相同字符串是不行的。
再回到next[i]的定义,对于字符串ptr = "ababaaababaa";
next[1] = -1,代表着除了第一个元素,之前前缀后缀最长的重复子串,这里是空 ,即"",没有,我们记为-1,代表空。(0代表1位相同,1代表两位相同,依次累加)。
next[2] = -1,即“a”,没有前缀与后缀,故最长重复的子串是空,值为-1;
next[3] = -1,即“ab”,前缀是“a”,后缀是“b”,最长重复的子串“”;
next[4] = 1,即"aba",前缀是“ab”,后缀是“ba”,最长重复的子串“a”;next数组里面就是最长重复子串字符串的个数
next[5] = 2,即"abab",前缀是“aba”,后缀是“bab”,最长重复的子串“ab”;
next[6] = 3,即"ababa",前缀是“abab”,后缀是“baba”,最长重复的子串“aba”;
next[7] = 1,即"ababaa",前缀是“ababa”,后缀是“babaa”,最长重复的子串“a”;
next[8] = 1,即"ababaaa",前缀是“ababaa”,后缀是“babaaa”,最长重复的子串“a”;
next[9] = 2,即"ababaaab",前缀是“ababaaa”,后缀是“babaaab”,最长重复的子串“ab”;
next[10] = 3,即"ababaaaba",前缀是“ababaaab”,后缀是“babaaaba”,最长重复的子串“aba”;
next[11] = 4,即"ababaaabab",前缀是“ababaaaba”,后缀是“babaaabab”,最长重复的子串“abab”;
next[12] = 5,即"ababaaababa",前缀是“ababaaabab”,后缀是“babaaaababa”,最长重复的子串“ababa”;
还有另外一种方法,我看的有的书上写着:
这里我们定义next[1] = 0 , next[1] = 1;
再分析ptr字符串,ptr = "ababaaababaa";
跟上一个的情况类似,
next[1] = 0 ,事先定义好的
next[2] = 1 ,事先定义好的
next[3] = 1 ,最长重复的子串“”;1代表没有重复,2代表有一个字符重复。
next[4] = 2 ,最长重复的子串“a”;追偿的长度加1,即为2.
next[5] = 3 ,以下都跟之前的一样,这种方法是最长的长度再加上一就可以了。
next[6] = 4
next[7] = 2
next[8] = 2
next[9] = 3
next[10] = 4
next[11] = 5
next[12] = 6
以上是next数组的详细解释。next数组求值 是比较麻烦的,剩下的匹配方式就很简单了。
next数组用于子串身上,根据上面的原理,我们能够推出子串a=“aab”的next数组的值分别为0,1,2.(按照我说的第二种方式算的)。
首先开始计算主串与子串的字符,设置主串用i来表示,子串用j来表示,如果ptr[i]与a[i]相等,那么i与j就都加1:

prt[1]与a[1]相等,i++,j++:
用代码实现就是

ptr[2]与a[2]不相等
此时ptr[2]!=a[2],那么令j = next[j],此时j=2,那么next[j] = next[2] = 1.那么此时j就等于1.这一段判断用代码解释的话就是:
加上上面的代码进行组合:
在对两个数组进行比对时,各自的i,j取值代码:
1 <span style="font-size:18px;"> next[i] = j; 2 } 3 else 4 { 5 j = next[j]; 6 } 7 }</span>
此时将a[j]置于j此时所处的位置,即a[1]放到j=2处,因为在j=2时出现不匹配的情况。

此时再次计算是否匹配,可以看出来a[1]!=ptr[2],那么j = next[j],即此时j = next[1] = 0;
根据上面的代码,当j=0时,执行++i;++j;
此时就变为:
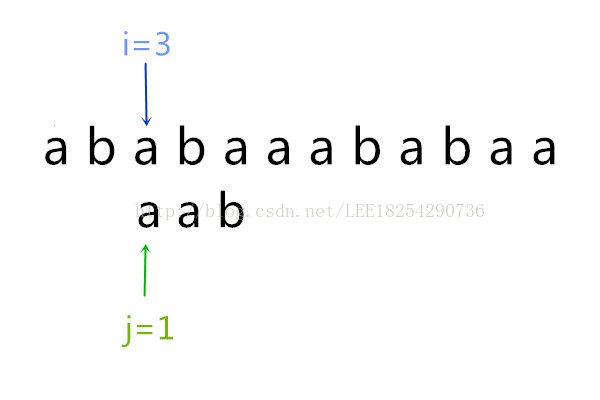
此时ptr[3] = a[1],继续向下走,下一个又不相等了,然后“aab”向后挪一位,这里不再赘述了,主要的思想已经讲明白了。到最后一直到i = 8,j=3时匹配成功,KMP算法结束。整个过程就结束了。
测试结果:

以上是关于数据结构之病毒感染检测问题的主要内容,如果未能解决你的问题,请参考以下文章
病毒感染检测 (15分) 人的DNA和病毒DNA均表示成由一些字母组成的字符串序列。然后检测某种病毒DNA序列是否在患者的DNA序列中出现过,如果出现过,则此人感染了该病毒,否则没有感染。