mapreduce on yarn的工作流程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce on yarn的工作流程相关的知识,希望对你有一定的参考价值。
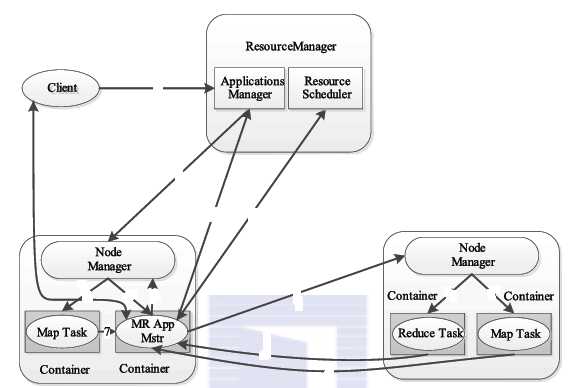
当client提交一个任务后,首先resourceManger(RM)来调度出一个container,这个container是在nodeManger(NM)运作的,
client直接和这个container所在的NM进行通信,在这个container中启动applicationMaster(AM),启动成功之后,这个AM将全权负责此次任务的进度,失败原因(在一次job中只有一个AM).
AM会计算此次任务所需的资源,然后向RM申请资源,得到一组供map/reduce task运行的container,然后协同NM一起对每个container执行一些必要的任务,在任务执行
过程中,AM会一直监视着任务的运行进度,若中间某个NM上的container中的任务失败,那么AM会重新找一台节点来运行此任务.
流程如下:
MRv2运行流程:
MR JobClient向resourceManager(RM)提交一个job
RM向Scheduler请求一个供MR AM运行的container,然后启动它
MR AM启动起来后向RM注册
MR JobClient向RM获取到MR AM相关的信息,然后直接与MR AM进行通信
MR AM计算splits并为所有的map构造资源请求
MR AM做一些必要的MR OutputCommitter的准备工作
MR AM向RM(Scheduler)发起资源请求,得到一组供map/reduce task运行的container,然后与NM一起对每一个container执行一些必要的任务,包括资源本地化等
MR AM 监视运行着的task 直到完成,当task失败时,申请新的container运行失败的task
当每个map/reduce task完成后,MR AM运行MR OutputCommitter的cleanup 代码,也就是进行一些收尾工作
当所有的map/reduce完成后,MR AM运行OutputCommitter的必要的job commit或者abort APIs
MR AM退出。
以上是关于mapreduce on yarn的工作流程的主要内容,如果未能解决你的问题,请参考以下文章
hadoop高可用+mapreduce on yarn集群搭建