深入理解 Taier:MR on Yarn 的实现原理
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解 Taier:MR on Yarn 的实现原理相关的知识,希望对你有一定的参考价值。
我们今天常说的大数据技术,它的理论基础来自于2003年 Google 发表的三篇论文,《The Google File System》、《MapReduce: Simplified Data Processing on Large Clusters》、《Bigtable: A Distributed Storage System for Structured Data》。这三篇论文分别对应后来出现的 HDFS,MapReduce, HBase。
在大数据的发展历史上,还有一个名字是无论如何都绕不开的,那就是 Doug Cutting。Doug是 Apache Lucene、Nutch、Hadoop、Avro 项目的创始人,2006 年 Docu Cutting 开源了 Hadoop,名字取自于他儿子的玩具小象 Hadoop。
那么就从 Hadoop 起,我们开始本文的分享。
Taier & Yarn
Hadoop
新生事物的成长往往是螺旋上升的,Hadoop 也是如此。Hadoop 1.0 是指 MapReduce + HDFS,其中 MapReduce 是一个离线处理框架,由编程模型(新旧API)、运行时环境(JobTracker 和 TaskTracker)和数据处理引擎(MapTask和ReduceTask)三部分组成。早期的 MapReduce 非常臃肿,有着很明显的缺点,JobTracker 有单点故障问题、框架设计只能执行 MapReduce 任务,不能跑 Storm,Flink 等计算框架的任务。

之后迎来的 Hadoop 2.0 是指 MapReduce + HDFS + Yarn,其中 YARN 是一个资源管理系统,负责集群资源管理和调度, MapReduce 则是运行在 YARN 上的离线处理框架。Hadoop 2.0 很好地解决了单点问题,它将 JobTracker 中的资源管理和作业控制分开,分别由 ResourceManager 负责所有应用程序的资源分配,ApplicationMaster 负责管理一个应用程序。并且解决了扩展问题,包括针对 Hadoop 1.0 中的 MapReduce 在扩展性和多框架支持等方面的不足。

MapReduce 2.0
MapReduce 1.0的工作机制中,角色主要包括客户端,Jobtracker,Tasktracker。Jobtracker 主要是协调作业的运行,而 Tasktracker 是负责运行作业划分之后的任务。网上关于 MR 1.0 的内容很多,这里就不再过多赘述,流程图如下:
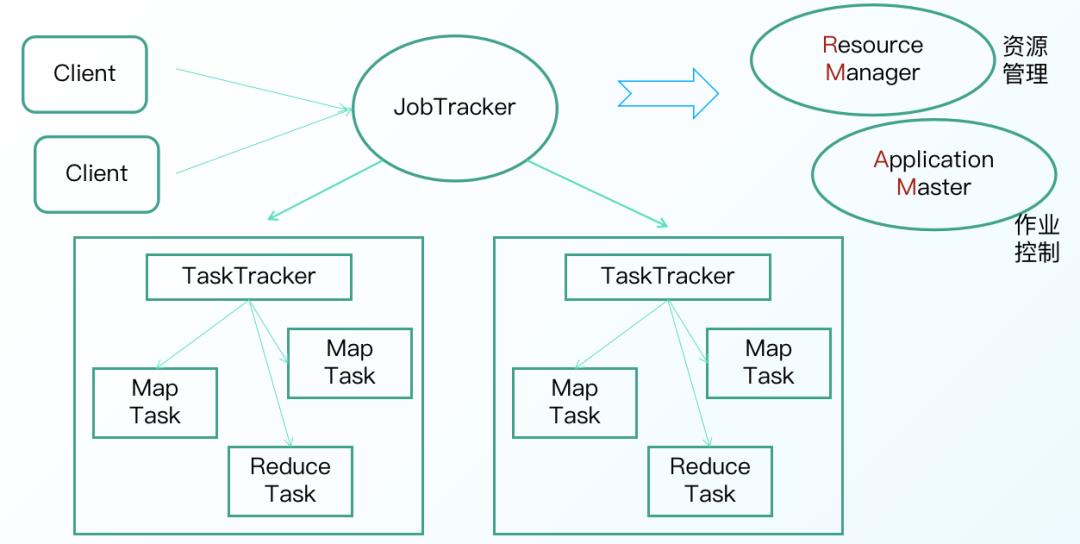
到了 MapReduce 2.0,核心思想则是将 MR 1.0 中 JobTracker 的资源管理和任务调度两个功能分开,分别由 ResourceManager 和 ApplicationMaster 进程实现。
MR 2.0 的工作流程主要分为以下6个执行过程(请将图片和文字对照起来看):
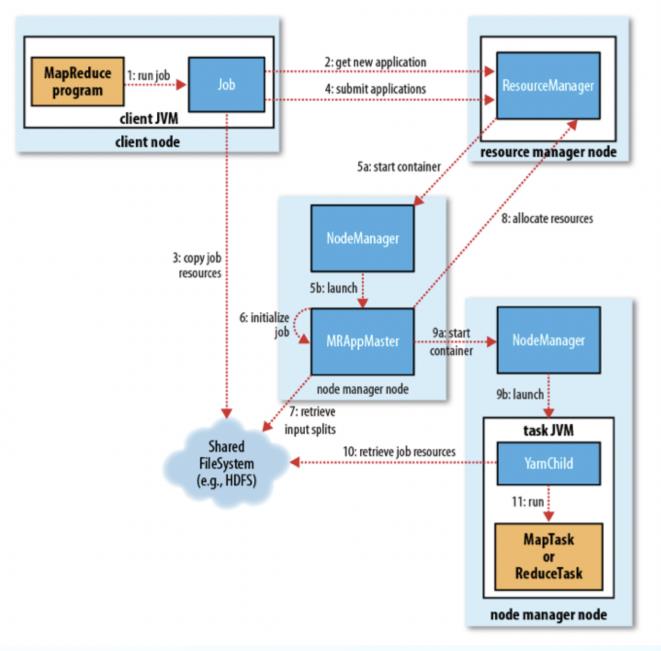
一、作业的提交
1)客户端向 ResourceManager 请求一个新的作业ID,ResourceManager 收到后,回应一个 ApplicationID,见第2步
2)计算作业的输入分片,将运行作业所需要的资源(包括jar文件、配置文件和计算得到的输入分片)复制到一个(HDFS),见第3步
3)告知 ResourceManager 作业准备执行,并且调用 submitApplication() 提交作业,见第4步
二、作业的初始化
- ResourceManager收到对其 submitApplication() 方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其初始化,然后为该其分配一个 contain 容器,见第5步
5)并与对应的 NodeManager 通信,见第5a步;要求它在 Contain 中启动 ApplicationMaster ,见第5b步
-
ApplicationMaster 启动后,会对作业进行初始化,并保持作业的追踪,见第6步
-
ApplicationMaster 从 HDFS 中共享资源,接受客户端计算的输入分片为每个分片,见第7步
三、任务的分配
- ApplicationMaster 向 ResourceManager 注册,这样就可以直接通过 RM 查看应用的运行状态,然后为所有的 map 和 reduce 任务获取资源,见第8步
四、任务的执行
- ApplicationMaster 申请到资源后,与 NodeManager 进行交互,要求它在 Contain 容器中启动执行任务,见第9a、9b步
五、进度和状态的更新
10)各个任务通过 RPC 协议 umbilical 接口向 ApplicationMaster 汇报自己的状态和进度,方便 ApplicationMaster 随时掌握各个任务的运行状态,用户也可以向 ApplicationMaster 查询运行状态
六、作业的完成
11)应用完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己
手写一个 Yarn 程序
如果想要将一个新的应用程序运行在 YARN 之上,通常需要编写两个组件:客户端和 ApplicationMaster。
· 客户端编写需要注意:客户端通常只需与 ResourceManager 交互,期间涉及到多个数据结构和一个 RPC 协议。
· ApplicationMaster 编写需要注意:ApplicationMaster 需要与 ResoureManager 和 NodeManager 交互,以申请资源和启动 Container,期间涉及到多个数据结构和两个 RPC 协议。
手写一个 YARN Application 程序对理解 YARN 的运行原理非常有帮助,熟悉 Spark 、Flink 计算组件的同学也可以参考 Spark on Yarn、Flink on Yarn 的源代码。
Taier&Yarn
洋洋洒洒,回过头来,现在来给大家介绍一下 Taier 和 Yarn 之间的关系。
Taier 作为一站式大数据任务调度引擎,是数栈数据中台整体架构的重要枢纽,负责调度日常庞大的任务量。它旨在降低ETL开发成本,提高大数据平台稳定性,让大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
为了更好地实现让数据开发人员关注业务的目标,Taier 主要在控制台中展示了 Hadoop Yarn的相关信息。分为以下3点:Yarn 配置管理、Yarn 资源管理、任务 on Yarn 的相关配置。
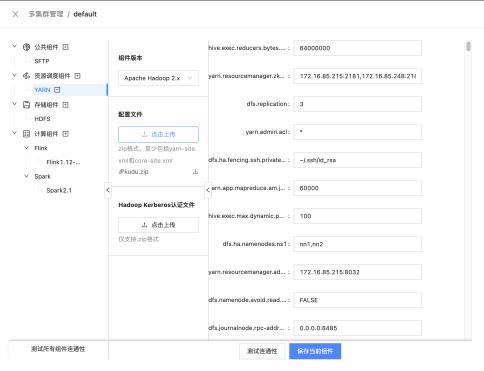
下面为大家展示一下 Taier 中 Yarn 相关的页面:
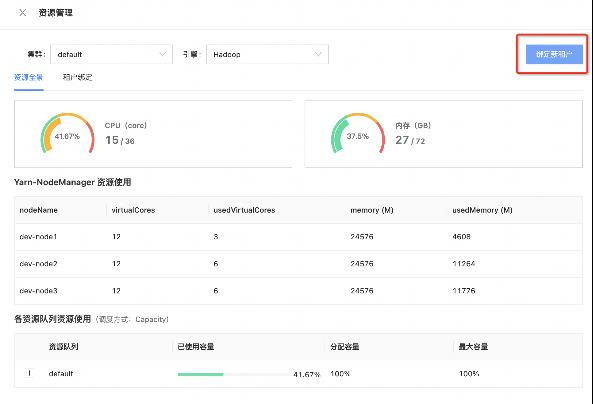
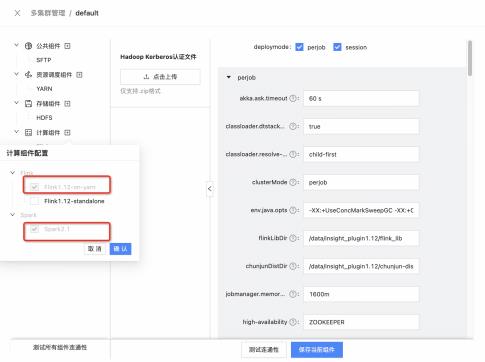
实现原理
前情提要全部讲完,下面为大家重点介绍下 Taier 怎么实现 MR on Yarn 的计算。
Taier 目前支持22种任务类型,支持在 Yarn 上运行的任务有 python、shell、数据同步、实时采集、Flink Jar、Flink SQL、Spark SQL 和 Hadoop MR 等等。
实现原理
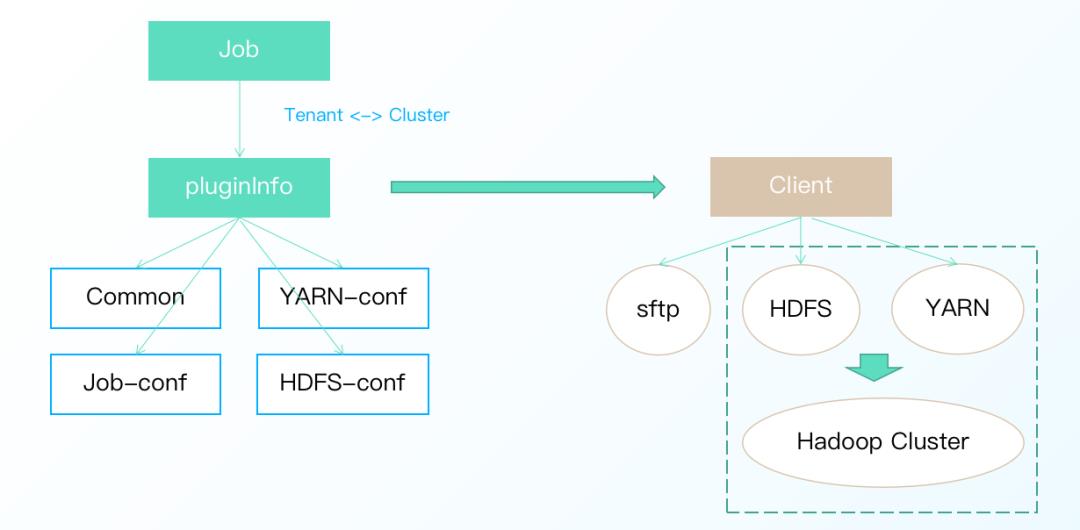
以 MR on Yarn 任务为例,其实现原理主要有2个关键步骤:
· 组装任务运行时的相关信息生成 pluginInfo,信息包含任务相关配置、YARN 配置、HDFS 配置和公共配置。
· 根据 pluginInfo 实例化相应的任务提交客户端,客户端负责向 YARN 提交任务,实现了 Taier 与计算集群的解耦、保证节点无侵入。
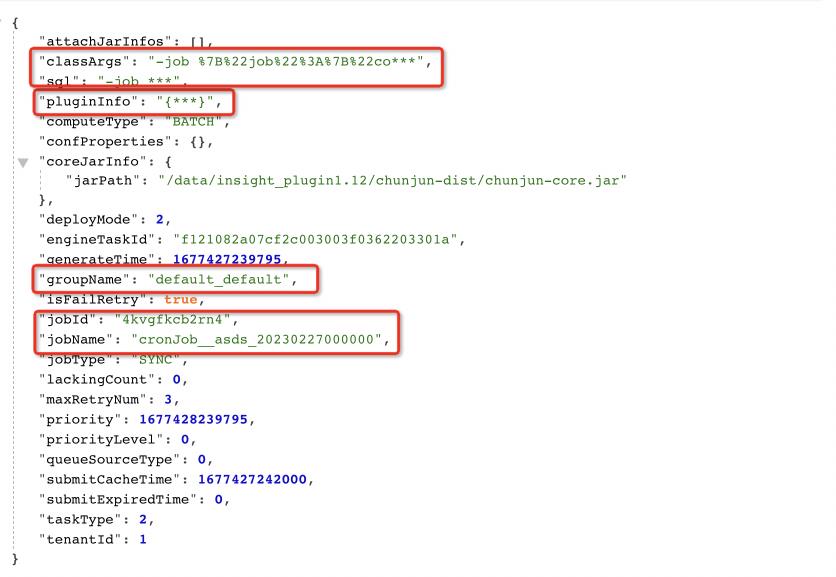
下图是目前已经在 Taier 上运行的 Flink 任务的一些参数,包括 groupName、jobID 等:
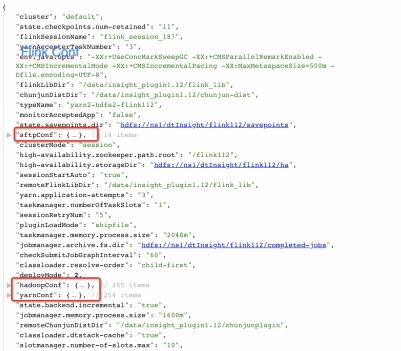
执行原理
以 MR on Yarn 任务为例,其执行原理可以分为以下3个阶段:

● 准备阶段
· 对普通的 Hadoop MR 任务进行改造,修改 MR 代码的 Main 方法
· 编译修改后的 Hadoop MR 任务,并通过 Taier 的资源上传功能将 Jar 进行上传,目标选择 HDFS
· 配置 Haddoop MR 任务的任务参数
● 运行阶段
· Taier 的 worker-plugin 主要负责任务提交相关工作,其中 hadoop 插件会负责 MR 任务的相关处理
· 实例化 HadoopClient,并下载准备阶段上传的 MR 任务对应的 Jar(注意这里是一个任务的生命周期,为了保障任务的无状态,所以每次运行都会重新下载一次)
· 通过 MapReduceTemplate ,加载 Jar 并构建 MR 任务的类加载器
· 通过类加载器实获取 Class 类对象,并调用类对象的 Main 方法,传入 Configuration、args 等参数
· 返回 JobId
● 运维阶段
· 处理 JobId 并转化为 ApplicationId
· 实例化 YarnClient,获取 MR on Yarn 的相关信息,包括运行状态、日志、停止 Application
Taier 中的 Hadoop 插件
Hadoop MR 的任务在 Taier 中的实现是基于 Hadoop 的插件,在里面实现了相关的类,其中比较主要的包括:
· HadoopClient: 实现任务提交运行的相关接口(init、judgeSlots、processSubmitJobWithType、beforeSubmitFunc、afterSubmitFunc、getJobStatus、getJobLog、cancelJob)
· MapReduceTemplate:封装 MR 任务及其重要参数、方法,实例化 PackagedProgram
· PackagedProgram:MR 任务提交前的处理实现
这一部分相关的代码可以在 PR 中的上下文看到,也可以下载 Taier 插件看到关键类所做的事件,如何相互配合实现 MR 任务往 Yarn 上进行提交。
相关PR:
https://github.com/DTStack/Taier/pull/983
案例演示
案例演示的部分,大家直接观看视频,会得到最直观清楚的讲解,本文就不再进行赘述。
视频链接:
https://www.bilibili.com/video/BV1ag4y1n7bT/?spm_id_from=333.999.0.0


视频课程&PPT获取
视频课程:
https://www.bilibili.com/video/BV1ag4y1n7bT/?spm_id_from=333.999.0.0
课件获取:
关注公众号 “数栈研习社” ,后台私信 “Taier” 获得直播课件
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
以上是关于深入理解 Taier:MR on Yarn 的实现原理的主要内容,如果未能解决你的问题,请参考以下文章