互联网金融爬虫怎么写-第一课 p2p网贷爬虫(XPath入门)
Posted 游牧民族
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网金融爬虫怎么写-第一课 p2p网贷爬虫(XPath入门)相关的知识,希望对你有一定的参考价值。
版权声明:本文为博主原创文章,未经博主允许不得转载。
相关教程:
手把手教你写电商爬虫-第三课 实战尚妆网AJAX请求处理和内容提取
手把手教你写电商爬虫-第五课 京东商品评论爬虫 一起来对付反爬虫
工具要求:教程中主要使用到了 1、神箭手云爬虫 框架 这个是爬虫的基础,2、Chrome浏览器和Chrome的插件XpathHelper 这个用来测试Xpath写的是否正确
基础知识:本教程中主要用到了一些基础的js和xpath语法,如果对这两种语言不熟悉,可以提前先学习下,都很简单
之前写了一个电商爬虫系列的文章,简单的给大家展示了一下爬虫从入门到进阶的路径,但是作为一个永远走在时代前沿的科技工作者,我们从来都不能停止 在已有的成果上,所以带上你的chrome,拿起你的xpathhelper,打开你的神箭手,让我们再次踏上征战金融数据之旅吧。(上个系列相对难一 些,建议如果是初学者,先看这个系列的教程)

金融数据实在是价值大,维度多,来源广。我们到底从哪里入手呢?想来想去,就从前一段时间风云变幻的p2p网贷开始吧。
同样,我们教程的一致风格就是先找个软柿子,上来不能用力过猛,逐渐培养自己的信心,等真正敌人来的时候,才不至于怯场害怕。
我们先去搜索一下p2p网站,随便找几个对比一下,选中了这个沪商财富

看着这样的收益率,心动了有木有,钱包坐不住了有木有,对余额宝投出鄙夷的目光了有木有

好了,闲话不说,这个系列课程吸取上个系列课程里进度太快的教训,给大家多讲一些基础的知识,这一课就结合这个实例,重点讲讲xpath的编写和用 法。首先,大体来讲,XPath是一个相对简单的语言,甚至都不一定能称得上是一个语言,主要用处是用来标记XML的元素路径。由于html也是一种 xml,因此通常来说,在html中抽取某个元素是通过XPath来做的。XPath本身和Css有着很大的相似性,一般来说如果之前对Css有一定的了 解的话,XPath上手还是很简单的。具体的情况我在下面的课程中一边写,一边解释。
首先先确定列表页:
http://www.hushangcaifu.com/invest/main.html
http://www.hushangcaifu.com/invest/index2.html
http://www.hushangcaifu.com/invest/index3.html
基本上可以看到列表页除了第一页以外都有规律可寻,不过看到这个效果,通常我们最好精益求精一下,看下第一页是否也可以符合规律呢?
打开http://www.hushangcaifu.com/invest/index1.html 果然也是第一页,好了,很完美,总结成正则表达式:
http://www\\\\.hushangcaifu\\\\.com/invest/index\\\\d+\\\\.html
再看下详情页:
http://www.hushangcaifu.com/invest/a3939.html
http://www.hushangcaifu.com/invest/a3936.html
哈哈,小菜一碟,直接化解成正则:
http://www\\\\.hushangcaifu\\\\.com/invest/a\\\\d{4}\\\\.html
好了,最后最重要的就是提取页面元素了。我们打开详情页:
http://www.hushangcaifu.com/invest/a3870.html

一般来说,我们在我们想要提取的元素上右击,点击审查元素,得到如下结果:

首先看到yanh1147这个元素有没有整个网页唯一的class,id或者其他属性,可以看到,在这个页面中没有,那么我们就往上找,上一级的p 标签也没有,咱们再往上找,在上一级是一个<div class="product-content-top-left-top">,终于有class了,让我们祈祷这个class是唯一的 吧,ctrl+f打开搜索框,输入product-content-top-left-top,可以看到,找到了1 of 1,这个代表一共一个,这个是第一个,这就是我们希望的结果,好了,只用找到这一级既可,我们来构造整个的xpath,一般来说xpath我们并不会从最 顶层的html开始写,因为没有必要,因此我们要使用//,这个表示不知中间有多少的层级。接着我们直接把刚刚找到的这个div写上去,得到这个表达式:
//div[contains(@class,"product-content-top-left-top")]
对于class属性,我们通常会使用contains这样一个函数,防止一个元素有多个class的情况,另外因为class是一个属性,因此class前面需要加上@代表选择到该元素的一个属性。
现在我们已经选择到了我们要选择的元素的父元素的父元素,只要我们继续往下走两层既可。
//div[contains(@class,"product-content-top-left-top")]/p/span
由于我们要选择元素里的文字信息,而不是整个元素,我们需要指定是这个元素的文字:
//div[contains(@class,"product-content-top-left-top")]/p/span/text()
好了,这样我们就确定了我们爬取的借款用户的名称,我们打开xpathhelper验证一下有没有写错:
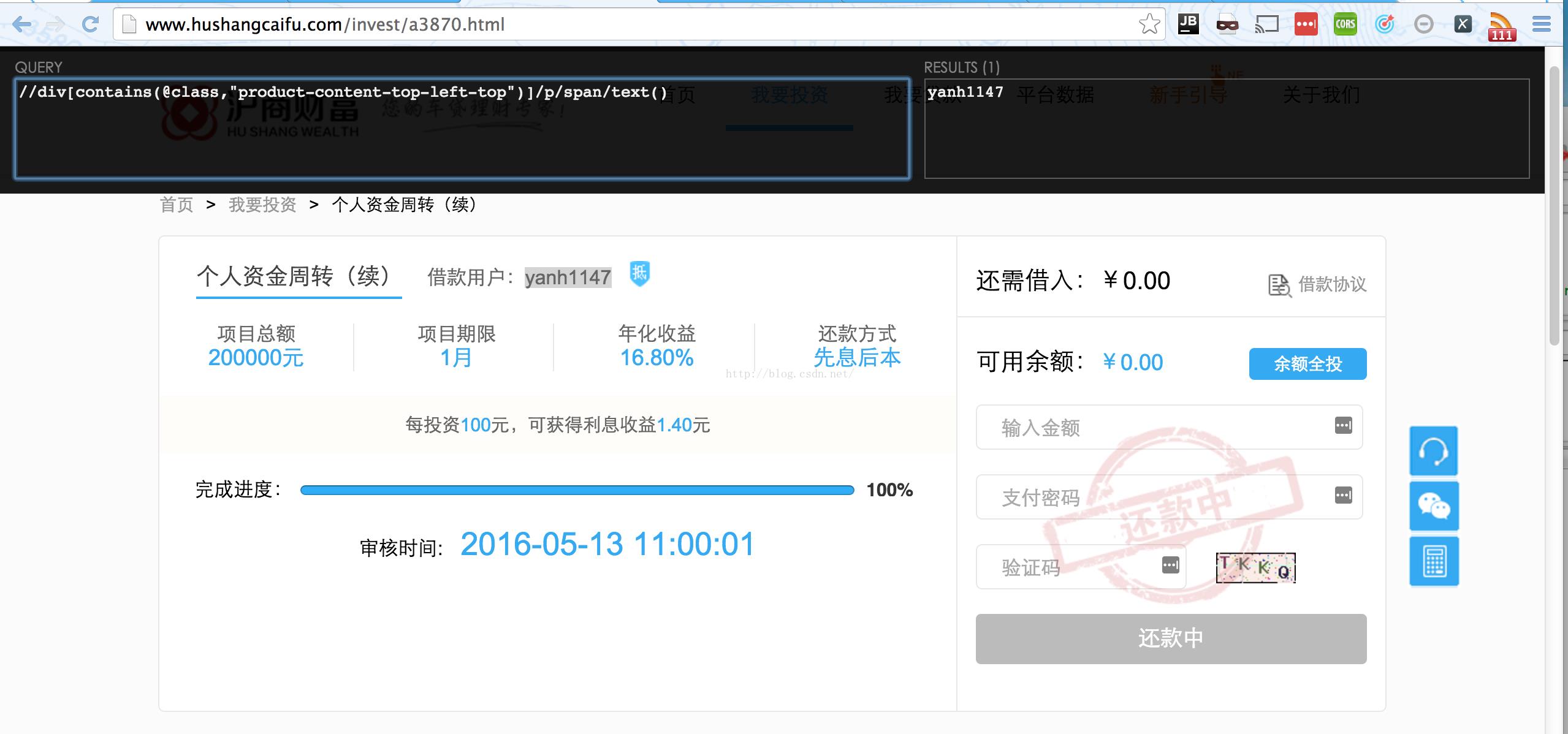
完美的结果。不过大家有的时候也需要注意,因为有的网页不代表你在一个内容页测试成功,在其他内容页也能成功,最好多测几个页面才是保险的。好了,其他的抽取项就不一一演示了,直接上最后的代码。
var configs = {
domains: ["www.hushangcaifu.com"],
scanUrls: ["http://www.hushangcaifu.com/invest/index1.html"],
contentUrlRegexes: ["http://www\\\\.hushangcaifu\\\\.com/invest/a\\\\d{4}\\\\.html"],
helperUrlRegexes: ["http://www\\\\.hushangcaifu\\\\.com/invest/index\\\\d+\\\\.html"],
fields: [
{
name: "title",
selector: "//div[contains(@class,\'product-content-top-left-top\')]/h3/text()",
required: true
},
{
name: "user_name",
selector: "//div[contains(@class,\'product-content-top-left-top\')]/p/span/text()"
},
{
name: "total_money",
selector: "//div[contains(@class,\'product-content-top-left-middle\')]/div[1]/h4/text()"
},
{
name: "project_time",
selector: "//div[contains(@class,\'product-content-top-left-middle\')]/div[2]/h4/text()"
},
{
name: "annual_return",
selector: "//div[contains(@class,\'product-content-top-left-middle\')]/div[3]/h4/text()"
},
{
name: "return_method",
selector: "//div[contains(@class,\'product-content-top-left-middle\')]/div[4]/h4/text()"
}
]
};
var crawler = new Crawler(configs);
crawler.start();
将代码粘贴到神箭手平台上既可运行。好了,看下运行结果:
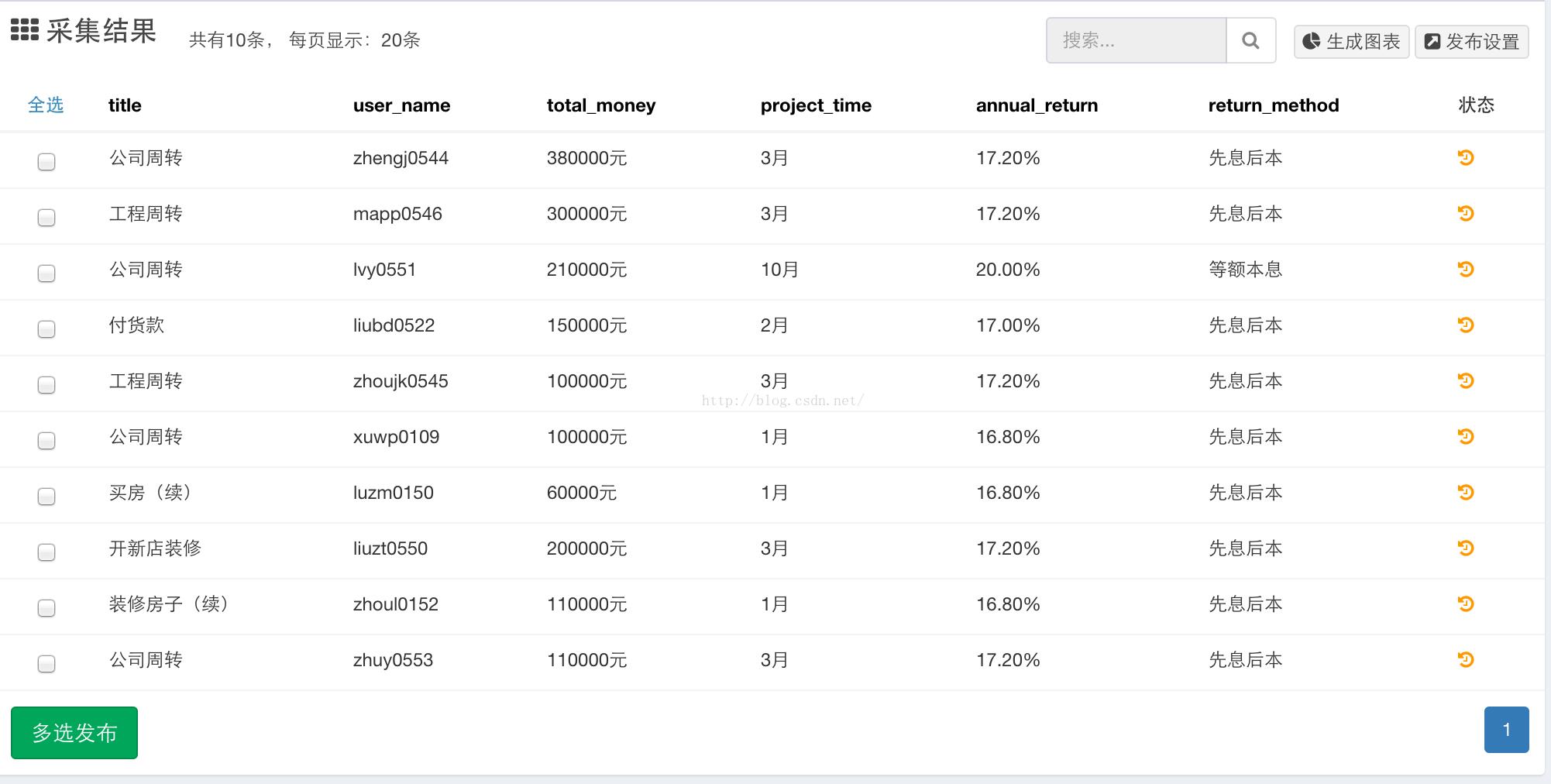
对爬虫感兴趣的童鞋可以加qq群讨论:342953471。
以上是关于互联网金融爬虫怎么写-第一课 p2p网贷爬虫(XPath入门)的主要内容,如果未能解决你的问题,请参考以下文章
互联网金融爬虫怎么写-第二课 雪球网股票爬虫(正则表达式入门)