Python爬虫第一课 Python爬虫环境与爬虫简介
Posted 笔触狂放
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫第一课 Python爬虫环境与爬虫简介相关的知识,希望对你有一定的参考价值。
1.1 认识爬虫
网络爬虫作为收集互联网数据的一种常用工具,近年来随着互联网的发展而快速崛起。使用网络爬虫爬取网络数据首先需要了解网络爬虫的概念和主要分类,各类爬虫的系统结构,运作方式,常用的爬取策略,以及主要的应用场景,同时,出于版权和数据安全的考虑,还需要了解目前有关爬虫应用的合法性及爬取网站时需要遵守的协议。
网络爬虫也被称为网络蜘蛛,网络机器人,是一个自动下载网页的计算机程序或者自动化脚本。网络爬虫就像一只蜘蛛一样在互联网上爬行,它以Url访问网络地址作为起点,沿着地址的请求路线进行爬行,下载每一个Url所指向请求的网址,分析页面内容的Url并记录下每个已经爬行过的Url,如此反复,知道Url队列为空或者满足设定的终止条件位置,最终达到遍历Web的目的,爬取想要的内容。
网络爬虫按照其系统结构和运作原理,大致可以分为4种:通用网络爬虫,聚焦网络爬虫,增量式网络爬虫,深层网络爬虫。
1.通用网络爬虫:该类爬虫比较适合为搜索引擎搜索广泛的主题,常用的爬取策略可分为深度优先策略和广度优先策略。
2.聚焦网络爬虫:根据指定目标来爬取数据,大致分为4种:基于内容评价的爬取策略,基于链接结果评价的爬取策略,基于增强学习的爬取策略,基于语境图的爬取策略
3.增量式网络爬虫:只对已下载网页采取增量式更新或者爬取新产生的及已经发生变化的网页。没有变化的网页不进行爬取,能有效的减少时间和存储空间上的浪费,但该算法的复杂度和实现难度更高。常用方法分为统一更新法,个体更新法,基于分类的更新法。
4.深层网络爬虫:Web页面分为表层页面和深层页面,表层页面是指以超链接可以访问的静态页面,深层页面是指通过表单提交数据后才能访问的页面,例如登录成功后才能看到的页面,但现实社会中几乎所有的网站深层页面比表层页面多几百倍。深度网络爬虫爬取数据过程中,最重要的部分就是表单填写,包含两种类型:基于领域知识的表单填写,基于网页结构分析的表单填写。
爬虫的合法性与robot.txt协议:在网站允许的情况下,将爬取的数据用于个人使用或者科学研究,但个人隐私数据以及明确禁止他人访问的数据是不允许爬取,触犯法律,当爬取网站数据的时候需要遵守网站所有者的robot.txt协议。
1.2 认识反爬虫
网站所有者并不欢迎爬虫,往往会针对爬虫做出限制措施。爬虫制作者需要了解网站所有者反爬虫的原因和想要通过爬虫达成的目的,并针对网站常用的爬虫检测方法和反爬虫手段,制定相应的爬取策略来规避网站的检测和限制。
网站所有者从所有网站来访者中识别出爬虫并对其做出相应处理(通常为封禁IP)的过程称为反爬虫。对于网站所有者而言,爬虫并不是一个受欢迎的客人。爬虫会消耗大量的服务器资源,影响服务器的稳定性,增加运营的网络成本。
1. 通过User-Agent校验反爬
浏览器在发送请求的时候,会附带一部分浏览器及当前系统环境的参数给服务器,服务器会通过User-Agent的值来区分不同的浏览器。

2. 通过访问频度反爬
普通用户通过浏览器访问网站的速度相对爬虫而言要慢的多,所以不少网站会利用这一点对访问频度设定一个阈值,如果一个IP单位时间内访问频度超过了预设的阈值,将会对该IP做出访问限制。
通常需要经过验证码验证后才能继续正常访问,严重的甚至会禁止该IP访问网站一段时间。

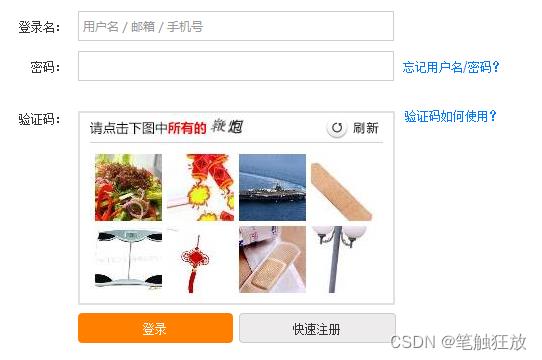
3. 通过验证码校验反爬
有部分网站不论访问频度如何,一定要来访者输入验证码才能继续操作。例如12306网站,不管是登陆还是购票,全部需要验证验证码,与访问频度无关。
4. 通过变换网页结构反爬
一些社交网站常常会更换网页结构,而爬虫大部分情况下都需要通过网页结构来解析需要的数据,所以这种做法也能起到反爬虫的作用。在网页结构变换后,爬虫往往无法在原本的网页位置找到原本需要的内容。

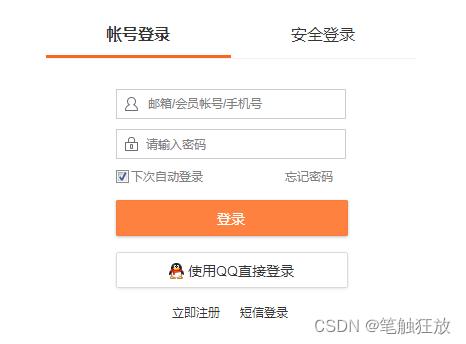
5. 通过账号权限反爬
部分网站需要登录才能继续操作,这部分网站虽然并不是为了反爬虫才要求登录操作,但确实起到了反爬虫的作用。
例如微博查看评论就需要登录账号。
爬取策略制定
针对之前介绍的常见的反爬虫手段,可以制定对应的爬取策略如下。
发送模拟User-Agent:通过发送模拟User-Agent来通过检验,将要发送至网站服务器的请求的User-Agent值伪装成一般用户登录网站时使用的User-Agent值。
调整访问频度:通过备用IP测试网站的访问频率阈值,然后设置访问频率比阈值略低。这种方法既能保证爬取的稳定性,又能使效率又不至于过于低下。
通过验证码校验:使用IP代理,更换爬虫IP;通过算法识别验证码;使用cookie绕过验证码。
应对网站结构变化:只爬取一次时,在其网站结构调整之前,将需要的数据全部爬取下来;使用脚本对网站结构进行监测,结构变化时,发出告警并及时停止爬虫。
通过账号权限限制:通过模拟登录的方法进行规避,往往也需要通过验证码检验。
通过代理IP规避:通过代理进行IP更换可有效规避网站检测,需注意公用IP代理池是 网站重点监测对象。
1.3 配置Python爬虫环境
目前Python有着形形色色的爬虫相关库,按照库的功能,整理如下。
| 类型 | 库名 | 简介 |
|---|---|---|
| 通用 | urllib | Python内置的HTTP请求库,提供一系列用于操作URL的功能 |
| requests | 基于urllib,采用Apache2 Licensed开源协议的HTTP库 | |
| urllib 3 | 提供很多Python标准库里所没有的重要特性:线程安全,连接池,客户端SSL/TLS验证,文件分部编码上传,协助处理重复请求和HTTP重定位,支持压缩编码,支持HTTP和SOCKS代理,100%测试覆盖率 | |
| 框架 | scrapy | 一个为了爬取网站数据,提取结构性数据而编写的应用框架 |
| HTML/XML**解析器** | lxml | C语言编写高效html/XML处理库。支持XPath |
| BeautifulSoup 4 | 纯Python实现的HTML/XML处理库,效率相对较低 |
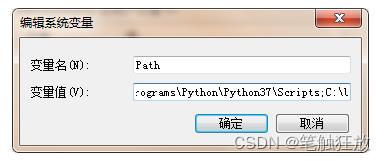
记住在使用pip下载安装第三方库时,一定需要将python安装路径下的Scripts目录添加至环境变量中
小结
本章对爬虫及反爬虫进行了一个基本概述,同时简要介绍了Python爬虫环境,对本章内容做小结如下。
爬虫是一种可以自动下载网页的脚本或计算机工具,可大致分为4种运作原理,用于个人或学术研究的爬虫通常是合法的。
反爬虫为网站针对爬虫进行检测和限制的过程,爬虫需针对反爬虫手段制定对应的爬取策略。
Python常用的爬虫库包含urllib、requests、urllib 3、scrapy、lxml和BeautifulSoup 4等库,通常需要配套数据库用于存储爬取的数据。
以上是关于Python爬虫第一课 Python爬虫环境与爬虫简介的主要内容,如果未能解决你的问题,请参考以下文章