Kaggle项目泰坦尼克号预测生存情况(上)-------数据预处理
Posted 风吹白杨的安妮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kaggle项目泰坦尼克号预测生存情况(上)-------数据预处理相关的知识,希望对你有一定的参考价值。
假期闲着无聊,做了一下Kaggle练手的项目--预测泰坦尼克号乘客的存活情况。对于一些函数和算法,刚开始也是懵懵懂懂的,但通过自己查资料,还是明白了许多。然后就是自己写的时候还看了下别人的做法,特别是国外的文章,写得很详细,逻辑特别清晰,还把不同算法的结果给你列出来,最后选择了最优算法。好佩服,希望自己以后也有这样的能力。我会把参考资料的网址放在需要查看的地方。train和test两个文件可以自己上Kaggle上下载,不过需要注册登录,在注册登录的时候用邮箱验证需要在谷歌浏览器里加载谷歌访问助手才能看到验证码最后才能成功注册。。。
------------------------------------
我们的整个流程如下:
①数据预处理:数据清洗、可视化、标签化
②分割训练数据
③随机森林分类器及其参数调节
④正式预测test.csv
数据预处理:数据清洗、可视化、标签化
首先,先导入需要的模块并读取数据
#导入包,读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data_train = pd.read_csv(r\'C:\\Users\\Administrator\\Desktop\\456\\train.csv\')
data_test = pd.read_csv(r\'C:\\Users\\Administrator\\Desktop\\456\\test.csv\')
导入成功后,我们来看看训练数集↓
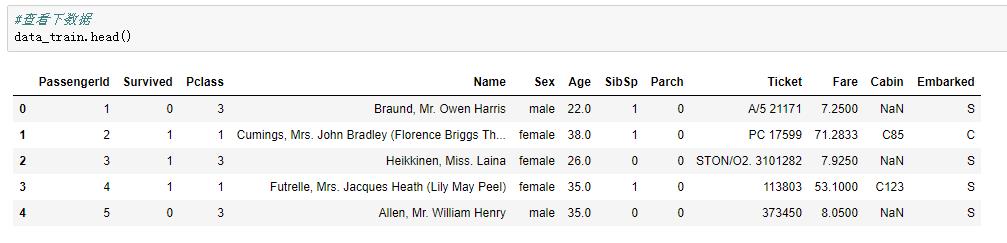
↑发现有如下特征:乘客ID,存活情况,船票级别,乘客姓名,性别,年龄,船上的兄弟姐妹以及配偶的人数,船上的父母以及子女的人数,船票编号,船票费用,所在船舱,登船的港口
查看缺失值。
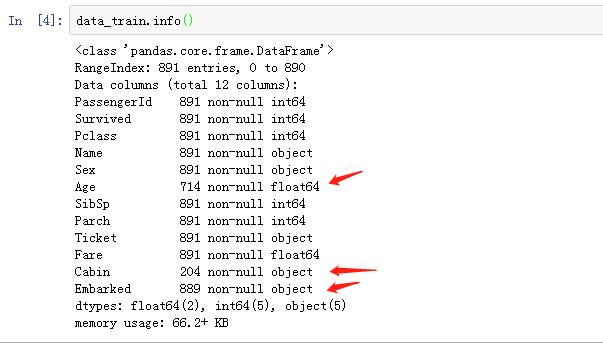
从以上,我们可以看出:
①训练集中共有891名乘客
②891名乘客中,714个乘客具有Age的信息,有177个乘客的Age缺失。
③891名乘客中,只有204个乘客具有Cabin的信息,有687个乘客的Cabin缺失。
查看数据的描述性信息
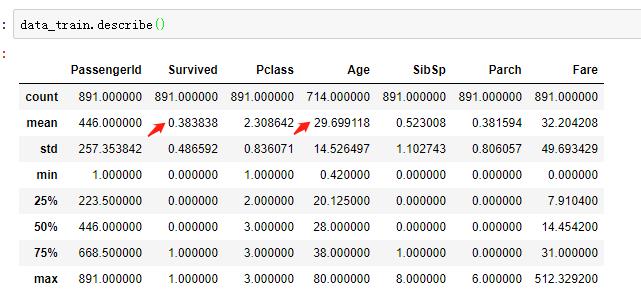
①乘客获救的概率是0.38
②乘客的平均年龄(没算缺失值)是29.7岁
来开始进行可视化
#我们要通过绘图来观察训练数集的基本情况哦,我们先从登舱口Embarked开始,来绘制二维柱状图,不同性别在不同登舱口的生存情况
sns.barplot(x=\'Embarked\',y=\'Survived\',hue=\'Sex\',data=data_train)
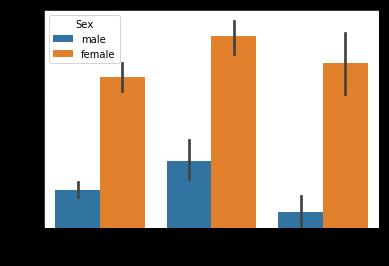
结论:
①无论在哪个港口上船,女性获救的概率远远高出男性。
②C港口上船的乘客获救较高,可能是住C港口附近的人有共同的什么特征? 但也有可能没什么关系。。先不管它。
#接着,我们用折线图从Pclass,也就是几等舱来观测下生存概率
sns.pointplot(x=\'Pclass\',y=\'Survived\',hue=\'Sex\',data=data_train,palette={\'male\':\'blue\',\'female\':\'pink\'},
marker=[\'*\',"o"],linestyle=[\'-\',\'--\'])
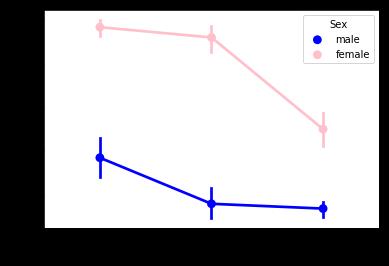
结论:
①女性的获救率依旧远远高于男性,所以说,很有可能性别Sex对Survived具有显著的影响
②随着等级舱的降低,不论是男性或女性,获救率也在降低。所以可能Pclass也对Surived有显著影响,
也就是说乘客的身份/地位/财富/背景 对乘客的获救率可能有显著影响。
除此之外,我们来看看 堂兄弟/妹,孩子/父母有几人,对是否获救的影响
SibSp_info = data_train.groupby([\'SibSp\',\'Survived\']) SibSp_df = pd.DataFrame(SibSp_info.count()[\'PassengerId\']) print(SibSp_df) Parch_info = data_train.groupby([\'Parch\',\'Survived\']) Parch_df = pd.DataFrame(Parch_info.count()[\'PassengerId\']) print(Parch_df)


①只能说,大部分的人并没有携带一家老小都来坐船玩
②我暂时看不出,SibSp、Parch对Survived的影响。先不管它吧 。。。。。。。。。。。。。。。
除了Embarked,Pclass等,我还想对年龄、Cabin的首字母(与乘客所在舱口有关)、工资这三种情况与生存情况画图分析
但现在的情况是:
①Age是连续型变量,且有些缺失值。对于缺失值的处理有如下:

所以,我的选择是第三个,把具有缺失值的作为一类别。我们可以按照我们日常生活的逻辑对年龄划区间,对年龄进行分组,再画图根据组来对乘客的Survived状况进行分析。
②Cabin是一个字母+一串数字,但我们可以它们切割了,只留字母。哎,Cabin的缺失值是贼多了,有点麻烦,我选择了上面第二种方法,依旧把它作为新的类目。用“N”代替
③船票费用也是连续变量,同样需要分组,我们把他们四分化,分为(最小值到下四分位数),(下四分位数到中位数),(中位数到上四分位数),(上四分位数到最大值)
④我觉得乘客的名字Name、船票编码Ticket对乘客的Survived情况没起到显著的作用,所以我打算删掉哦!
因此,我们要完成以上的任务哦。也就是说,我们要把原来的data_train转化成我们需要的、可以方便我们进行数据分析的表格↓
①简化年龄,就是分组
def simplify_ages(df):
#把缺失值补上,方便分组
df.Age = df.Age.fillna(-0.5)
#把Age分为不同区间,-1到0,1-5,6-12...,60以上,放到bins里,八个区间,对应的八个区间名称在group_names那
bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
group_names = [\'Unknown\', \'Baby\', \'Child\', \'Teenager\', \'Student\', \'Young Adult\', \'Adult\', \'Senior\']
#开始对数据进行离散化,pandas.cut就是这个功能
catagories = pd.cut(df.Age,bins,labels=group_names)
df.Age = catagories
return df
②简化Cabin,就是取字母
def simplify_cabin(df):
df.Cabin = df.Cabin.fillna(\'N\')
df.Cabin = df.Cabin.apply(lambda x:x[0])
return df
③简化工资,也就是分组
def simplify_fare(df):
df.Fare = df.Fare.fillna(-0.5)
bins = (-1, 0, 8, 15, 31, 1000)
group_names = [\'Unknown\', \'1_quartile\', \'2_quartile\', \'3_quartile\', \'4_quartile\']
catagories = pd.cut(df.Fare,bins,labels=group_names)
df.Fare = catagories
return df
④删除无用信息
def simplify_drop(df):
return df.drop([\'Name\',\'Ticket\',\'Embarked\'],axis=1)
⑤整合一遍,凑成新表
def transform_features(df):
df = simplify_ages(df)
df = simplify_cabin(df)
df = simplify_fare(df)
df = simplify_drop(df)
return df
⑥执行读取新表
#必须要再读取一遍原来的表,不然会报错,不仅训练集要简化,测试集也要,两者的特征名称要一致
data_train = pd.read_csv(r\'C:\\Users\\Administrator\\Desktop\\456\\train.csv\')
data_train = transform_features(data_train)
data_test = transform_features(data_test)
data_train.head()
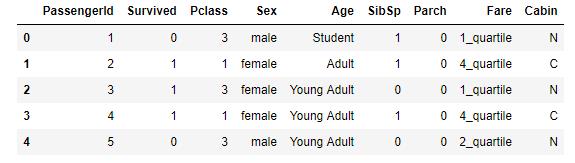
以上任务执行完毕,继续画图!
#好啦,我们根据新的表格来画图啦,先来话Age-Survived的图哦,以Sex分组
sns.barplot(x = \'Age\',y = \'Survived\',hue=\'Sex\',data = data_train)

①女性获救概率依旧高于男性,这点就不再阐述了。
②老人小孩获救率最高,中青年特别是男性,获救率是最低的。真的是很绅士了。
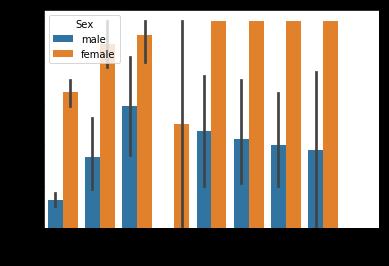
#再按Cabin-Survived画
sns.barplot(x = \'Cabin\',y = \'Survived\',hue=\'Sex\',data = data_train)
#根据舱位,其实也可以看出一些端倪哦
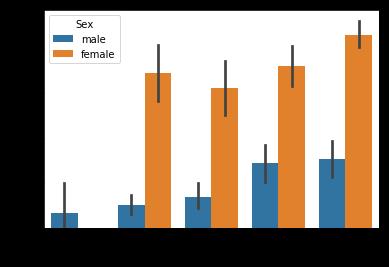
#到Fare啦
sns.barplot(x = \'Fare\',y = \'Survived\',hue=\'Sex\',data = data_train)
#果然票费越高的,存活率更高啊,
数据预处理的最后一步:标签化数据
这里我们会用到Scikit-learn中的LabelEncoder,
Scikit-learn中的LabelEncoder会将每个唯一的字符串值转换为一个数字
最后的结果会是一张数表哦
关于sklearn的学习资料在这:https://www.jianshu.com/p/cd5a929bec33 《sklearn快速入门》
这里用到了sklearn的preprocessing预处理模块
还用到pandas的concat功能,concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合
#test和train一起标签化,共生死,共沉沦 from sklearn import preprocessing def features_encode(df_train,df_test): features = [\'Sex\',\'Age\',\'Fare\',\'Cabin\'] df_combined = pd.concat([df_train[features],df_test[features]]) for feature in features: le = preprocessing.LabelEncoder() #非数字型和数字型标签值标准化 le = le.fit(df_combined[feature]) df_train = le.transform([df_train[feature]]) df_test = le.transform([df_test[feature]]) return df_train,df_test #开始代入函数 data_train,data_test = encode_features(data_train,data_test) data_train.head()
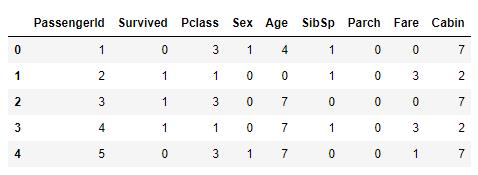
可以看到,像Age,Fare Cabin都标签化了,都是数字了
分割训练数据
首先,从标签(y)中分离出特征(X)。
X_all:所有特征减去我们想要预测的值(Survived)。也就是所有的自变量
y_all:只有我们想要预测的价值,传说中的目标变量,也就是因变量。
其次,使用Scikit-learn将这些数据随机洗牌成四个变量。 在这种情况下,训练80%的数据,然后测试其他20%。
之后,这些数据将重新组织为KFold模式,以验证训练算法的有效性。这是在第三步的,只是提前说一下
不懂的话看B站吴恩达视频的61集 10-3 Model Selection and Train_Validation_Test Sets
不过,这里还是推荐下几个网址:
https://zhuanlan.zhihu.com/p/30059442 《通俗理解决策树》
https://segmentfault.com/a/1190000011835617 《随机森林简明教程》
https://segmentfault.com/a/1190000008318983 《K-折交叉验证》
写得都很好,特别是那个《随机森林简明教程》,讲的很详细,自己再动手把相关的参数算一遍,
会大概对随机森林及其参数有个比较宏观的理解。
from sklearn.model_selection import train_test_split X_all = data_train.drop([\'Survived\', \'PassengerId\'],axis=1)#主要是乘客ID也没啥用,删就删了吧 y_all = data_train[\'Survived\'] p = 0.2 #用 百分之20作为测试集 """ 穿插一个知识点 train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和test data,形式为: X_train,X_test, y_train, y_test = cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0) """ X_train,X_test, y_train, y_test = train_test_split(X_all,y_all,test_size=p, random_state=23)
随机森林分类器及其参数调节
再次第100遍推荐:
https://segmentfault.com/a/1190000011835617 《随机森林简明教程》
不然到parameter哪里会不太理解。parameter参数的数值我是参考国外一些网站的资料写的。
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import make_scorer, accuracy_score from sklearn.model_selection import GridSearchCV #选择分类器的类型,我没试过其他的哦,因为在这个案例中,有人做过试验发现随机森林模型是最好的,所以选了它。呜呜,我下次试试其他的 clf = RandomForestClassifier() #可以通过定义树的各种参数,限制树的大小,防止出现过拟合现象哦,也可以通过剪枝来限制,但sklearn中的决策树分类器目前不支持剪枝 parameters = {\'n_estimators\': [4, 6, 9], \'max_features\': [\'log2\', \'sqrt\',\'auto\'], \'criterion\': [\'entropy\', \'gini\'], #分类标准用熵,基尼系数 \'max_depth\': [2, 3, 5, 10], \'min_samples_split\': [2, 3, 5], \'min_samples_leaf\': [1,5,8] } #以下是用于比较参数好坏的评分,使用\'make_scorer\'将\'accuracy_score\'转换为评分函数 acc_scorer = make_scorer(accuracy_score) #自动调参,GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数 #GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。 grid_obj = GridSearchCV(clf,parameters,scoring=acc_scorer) grid_obj = grid_obj.fit(X_train,y_train) #将clf设置为参数的最佳组合 clf = grid_obj.best_estimator_ #将最佳算法运用于数据中 clf.fit(X_train,y_train)

predictions = clf.predict(X_test) print(accuracy_score(y_test,predictions)) #如果把上面多执行几次,会发现这里的执行的结果都会有所不同,取决于用了parameter的哪些参数
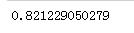
即81%左右与的预测是对的呢
用K-Fold验证
搞完上面后,我们要想想,
这个模型真的有用吗?
要不再验证下?
利用K-FOLD验证,我们会把数据分成10个桶,然后使用不同的桶作为每次迭代的测试集运行算法。
这跟放回抽样有点类似,重复放回抽个十次八次那样
简单介绍下K-Fold:
K-fold cross-validation (k-CV)是double cross-validation的延伸,作法是将dataset切成k个大小相等的subsets,
每个subset皆分别作为一次test set,其余样本则作为training set,因此一次k-CV的实验共需要建立k个models,
并计算k次test sets的平均辨识率。在实作上,k要够大才能使各回合中的training set样本数够多,一般而言k=10算是相当足够了。
下面的代码是参考国外网站的写法,让我自己写的话,一下子很难写出来,但我觉得能先理清思路是最重要的。
from sklearn.cross_validation import KFold def run_kfold(clf): kf = KFold(891,n_folds=10) outcomes = [] fold = 0 for train_index,test_index in kf: fold = fold + 1 X_train,X_test = X_all.values[train_index],X_all.values[test_index] y_train,y_test = y_all.values[train_index],y_all.values[test_index] clf.fit(X_train,y_train) predictions = clf.predict(X_test) accuracy = accuracy_score(y_test,predictions) outcomes.append(accuracy) print("Fold {0} accuracy: {1}".format(fold,accuracy)) mean_outcome = np.mean(outcomes) print("Mean Accuracy:",mean_outcome) run_kfold(clf)

经过十次的抽样,可以发现这十次的抽样都有所不同,最小的正确率达到了0.74,最大的时候达到0.865那样
平均十次下来是0.80.
正式预测test.csv
这个练手项目的要求结果是这样的:

就是要有乘客的ID,和存活情况
predictions = clf.predict(data_test.drop(\'PassengerId\',axis=1)) output = pd.DataFrame({\'Passengers\':data_test[\'PassengerId\'],\'Survived\':predictions}) output.to_csv(r\'C:\\Users\\Administrator\\Desktop\\456\\ceshi2.csv\') output.head()

然后要提交预测后的数据
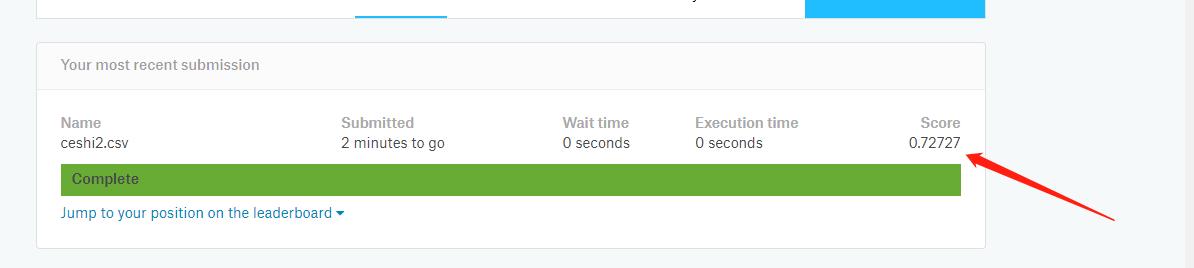
啊,正确预测了0.72的数据,额。。。没事,安慰自己是第一次提交。
总结下:
这次的试验还是很粗糙的,比如我粗暴地把缺失的数据直接列为Unknown,其实可以根据缺失值的其他信息,比如说缺失值所在的年龄类别、票价类别等,来拟合可能的缺失值。
然后国外有一篇文章写得很全,翻译后的文章收录在了这篇博客上 了:
http://www.cnblogs.com/zackstang/p/8185531.html
以上是关于Kaggle项目泰坦尼克号预测生存情况(上)-------数据预处理的主要内容,如果未能解决你的问题,请参考以下文章
Kaggle经典测试,泰坦尼克号的生存预测,机器学习实验----02
Kaggle经典测试,泰坦尼克号的生存预测,机器学习实验----02