泰坦尼克号生存预测
Posted wyy1480
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了泰坦尼克号生存预测相关的知识,希望对你有一定的参考价值。
从Kaggle官网下载数据:train 、test。
赛事描述:
- 泰坦尼克号的沉没是历史上最臭名昭著的沉船之一。1912年4月15日,泰坦尼克号在处女航时与冰山相撞沉没,2224名乘客和船员中有1502人遇难。这一耸人听闻的悲剧震惊了国际社会,并导致更好的船舶安全法规。船难造成如此巨大的人员伤亡的原因之一是船上没有足够的救生艇供乘客和船员使用。虽然在沉船事件中幸存下来是有运气因素的,但有些人比其他人更有可能存活下来。比如妇女、儿童和上层阶级。
- 在此次比赛中,我们需要参赛者预测哪一类人更有可能存活下来。尤其是,我们需要你用机器学习的工具去预测哪些乘客在这次灾难中幸存。
目录
- 提出问题
- 理解数据
- 数据处理(数据预处理and特征工程)
- 模型构建与评估
- 总结
一.提出问题:
根据已知信息预测test中418名乘客生存与否,并将预测结果提交。

问题分析:
即基于一组预测变量预测一个分类结果(二分类)。有监督机器学习领域中包含可用于分类的方法:逻辑回归、KNN、决策树、随机森林、支持向量机、神经网络等。本文选择Logistic 和 KNN 来做分类预测。
二.理解数据:
先初步了解一下变量个数、数据类型、分布情况、缺失情况等,并做出一些猜想。
#调入所需模块
#数据处理
import numpy as np
import pandas as pd
import re
#作图
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
#设置作图风格
sns.set_style("darkgrid")OK,先浏览数据:
#读取数据
train = pd.read_csv(r"G:KaggleTitanic rain.csv")
test = pd.read_csv(r"G:KaggleTitanic est.csv")
#看一下训练集前6行
train.head(6)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
训练集字段:乘客ID、是否生存、舱位等级、姓名、性别、年龄、堂兄弟和堂兄妹个数、父母和孩子的个数、船票编码、票价、客舱、上船口岸。
#随机查看测试集的数据
test.sample(6)| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 417 | 1309 | 3 | Peter, Master. Michael J | male | NaN | 1 | 1 | 2668 | 22.3583 | NaN | C |
| 224 | 1116 | 1 | Candee, Mrs. Edward (Helen Churchill Hungerford) | female | 53.0 | 0 | 0 | PC 17606 | 27.4458 | NaN | C |
| 99 | 991 | 3 | Nancarrow, Mr. William Henry | male | 33.0 | 0 | 0 | A./5. 3338 | 8.0500 | NaN | S |
| 410 | 1302 | 3 | Naughton, Miss. Hannah | female | NaN | 0 | 0 | 365237 | 7.7500 | NaN | Q |
| 41 | 933 | 1 | Franklin, Mr. Thomas Parham | male | NaN | 0 | 0 | 113778 | 26.5500 | D34 | S |
| 70 | 962 | 3 | Mulvihill, Miss. Bertha E | female | 24.0 | 0 | 0 | 382653 | 7.7500 | NaN | Q |
与训练集相比,少了目标变量Survived,其余字段都是一样的。
train.info()
print("==" * 50)
test.info()<class ‘pandas.core.frame.DataFrame‘>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
====================================================================================================
<class ‘pandas.core.frame.DataFrame‘>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KBtrain总共有891名乘客信息、12个字段,Age、Cabin、Embarked均有缺失。
test总共有418名乘客信息、11个字段,Age、Fare、Cabin均有缺失。
在两个数据集中,Age缺失较多,Cabin缺失严重;均有数值型、字符型数据。
#查看数值型数据情况:
train.describe()| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
#查看字符型数据情况:
train.describe(include=[‘O‘])| Name | Sex | Ticket | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Kink-Heilmann, Miss. Luise Gretchen | male | 1601 | C23 C25 C27 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
A.基本描述:
类别型变量:Survived、Pclass(顺序)、Sex、Embarked。数值型变量:Age、 SibSp(离散)、Parch(离散)、Fare.
总共4个字段有缺失,缺失程度不一样(Age、Cabin缺较多,Fare、Embarked缺较少)
- 训练集中:
- (1)共有891名乘客,生存率为38%
- (2)年龄最小为0.42,最大为80岁,除去缺失值,平均年龄为29,高龄人士较少
- (3)约25%的乘客有一个或以上的兄弟姐妹陪伴的,75%以上的乘客没有与父母孩子同行
- (4)票价平均值在32美元,最高值在512美元,差距较大
- (5)每个人的名字都是无重复的
- (6)男性共计577人,男乘客较女乘客多
- (7)Ticket有681个不同的值
- (8)Cabin的数据缺失较多,891人中有记录的仅为204人
- (9)上船口岸有缺失值,644人在S港口上船,占比较大
B.猜想:
现已知目标变量为Survived,其余都作为建模可供考虑的特征。下面我们要探究一下现有的每一个变量对乘客生存的影响程度,有用的留下,没用的删除,也看能不能发掘出新的信息帮助构建模型。可做出以下猜想:
1.Pclass、Fare反映一个人的身份、财力情况,在危难关头,社会等级高的乘客的生存率比等级低的乘客的生存率高。
2.在灾难发生时,人类社会的尊老爱幼、女性优先必会起作用。故老幼、女性生存率更高。
3.有多个亲人同行的话,人多力量大,生存率可能更高些。
4.名字、Ticket看不出能反映什么,可能会删掉。
5.Id在记录数据中有用,在分析中没什么用,删掉。
C:缺失数据:
对于缺失的数据,需要根据不同情况进行处理。
处理缺失值方式(在scikit-learn中,build models时若有缺失值会报错):
- 删(简单粗暴,dropna)
- 完整实例删除,即删行(简单粗暴,当样本量大,且缺失案例较少时用)
- 删除有缺失值的特征(该列缺失严重,且该特征对建模效果影响不大时用)
- Imputation(从已知的部分数据中推断出缺失值,虽然估计值并不绝对百正确,但是比上述删除列的做法来说,此法建模效果更好一点)
- 用该特征的均值、中位数、众数等去估算(普通版)
- 由其他已知的数值型数据,去估算缺失值的值(进阶版)
D.数据类型转换:
字符型都要转换成数值型数据。
三.数据处理(数据预处理and特征工程)
首先合并train和test,为了后续写代码能同时处理两个数据集:
combination_data = [train,test]下面将根据现在数据的类型,分数值型和字符串来讨论、研究,同时完成缺失值进行处理、根据每个变量与生存率之间的关系进行选择,必要时将删除变量或者创造出新的变量来帮助模型的构建。最终所有的数据类型都将处理为数值型。
数值型:
- PassengerId
乘客编码,做区分用,对预测无作用,删掉。
del train["PassengerId"]- Pclass
船舱分三等,某种程度上代表了乘客的身份、社会地位,下面探究一下Pclass的作用:
train[["Pclass","Survived"]].groupby("Pclass",as_index=False).mean().sort_values(by="Survived",ascending=False)| Pclass | Survived | |
|---|---|---|
| 0 | 1 | 0.629630 |
| 1 | 2 | 0.472826 |
| 2 | 3 | 0.242363 |
sns.barplot(x="Pclass",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b986f4e0>
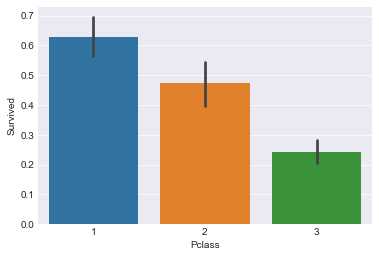
超过60%的一等舱的乘客存活了下来,而仅24%的三等舱乘客存活了下来。由图更直观看出Pclass=1的优势所在。可见,Pclass对生存预测存在影响,故考虑该特征。
- SibSp
train[["SibSp","Survived"]].groupby("SibSp",as_index=False).mean().sort_values(by="Survived",ascending=False)| SibSp | Survived | |
|---|---|---|
| 1 | 1 | 0.535885 |
| 2 | 2 | 0.464286 |
| 0 | 0 | 0.345395 |
| 3 | 3 | 0.250000 |
| 4 | 4 | 0.166667 |
| 5 | 5 | 0.000000 |
| 6 | 8 | 0.000000 |
SibSp为3、4、5、8人时,生存率都较小,甚至为0,有影响但不明显。
- Parch
train[["Parch","Survived"]].groupby("Parch",as_index=False).mean().sort_values(by="Survived",ascending=False)| Parch | Survived | |
|---|---|---|
| 3 | 3 | 0.600000 |
| 1 | 1 | 0.550847 |
| 2 | 2 | 0.500000 |
| 0 | 0 | 0.343658 |
| 5 | 5 | 0.200000 |
| 4 | 4 | 0.000000 |
| 6 | 6 | 0.000000 |
看到Parch为4、5、6的生存率也较小,影响不是很明显。跟上面的SibSp情况类似,现将两变量人数合起来看对生存率的影响如何:
for dataset in combination_data:
dataset["Family"] = dataset["SibSp"] + dataset["Parch"] + 1train[["Family","Survived"]].groupby("Family",as_index=False).mean().sort_values(by="Survived",ascending=False)| Family | Survived | |
|---|---|---|
| 3 | 4 | 0.724138 |
| 2 | 3 | 0.578431 |
| 1 | 2 | 0.552795 |
| 6 | 7 | 0.333333 |
| 0 | 1 | 0.303538 |
| 4 | 5 | 0.200000 |
| 5 | 6 | 0.136364 |
| 7 | 8 | 0.000000 |
| 8 | 11 | 0.000000 |
sns.countplot(x="Family",hue="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b985eb00>
单独一人以及家庭规模>=5人时,死亡率高于生存率。于是,按家庭规模分成小、中、大家庭:
for dataset in combination_data:
dataset["Family_size"] = 0 #创建新的一列
dataset.loc[dataset["Family"] == 1,"Family_size"] = 1 #小家庭(独自一人)
dataset.loc[(dataset["Family"] > 1) & (dataset["Family"] <= 4),"Family_size"] = 2 #中家庭(2-4)
dataset.loc[dataset["Family"] > 4,"Family_size"] = 3 #大家庭(5-11)
dataset["Family_size"] = dataset["Family_size"].astype(int)同时,我们也可考虑家庭成员的陪伴对生存率是否有影响,来看是否需要构建一个新的特征:
for dataset in combination_data:
dataset["Alone"] = dataset["Family"].map(lambda x : 1 if x==1 else 0)train[["Alone","Survived"]].groupby("Alone",as_index=False).mean().sort_values("Survived",ascending=False)| Alone | Survived | |
|---|---|---|
| 0 | 0 | 0.505650 |
| 1 | 1 | 0.303538 |
sns.barplot(x="Alone",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b9d58940>
有家庭成员同船,生存率比独自在船的生存率高。所以引入该新特征,而将SibSp、Parch、Family都删除掉。
for dataset in combination_data:
dataset.drop(["SibSp","Parch","Family"],axis=1,inplace=True)我们加入Pclass来考虑此问题:
sns.factorplot(x="Pclass",y="Survived",hue="Alone",data=train)<seaborn.axisgrid.FacetGrid at 0x49b99229e8>
在考虑乘客是否独自一人对生存率影响的同时,乘客所属船舱等级也一直在影响生存率。考虑Pclass是有必要的。
- Age
train.Age.describe()count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64#查看Age的分布情况
sns.violinplot(y="Age",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b9f28860>
乘客主要是二三十岁的群体,中位数是28,百分之五十的人集中在20-38岁。60岁以上的人比较少。
#查看生存与死亡乘客的年龄分布
sns.violinplot(y="Age",x="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b9f619b0>
我们看一下train中的数据,先把年龄等宽划分成5组,看各个年龄组的生存如何:
train["Age_group"] = pd.cut(train.Age,5)
train[["Age_group","Survived"]].groupby("Age_group",as_index=False).mean().sort_values("Survived",ascending=False)| Age_group | Survived | |
|---|---|---|
| 0 | (0.34, 16.336] | 0.550000 |
| 3 | (48.168, 64.084] | 0.434783 |
| 2 | (32.252, 48.168] | 0.404255 |
| 1 | (16.336, 32.252] | 0.369942 |
| 4 | (64.084, 80.0] | 0.090909 |
sns.barplot(x="Age_group",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49ba2b1dd8>
不同年龄段,生存率不同。0-16岁之间生存率最高,64-80岁的老年人的生存率最低。说明年龄是影响生存的一个重要因素。
del train["Age_group"]下面要填补Age的缺失值,先查看Age列的情况
train.Age.isnull().sum()177train数据集的891个乘客中,177人(接近20%)的年龄数据缺失,平均年龄为29.7,标准差为14.5,中位数为28。
对于age的缺失值,暂时用平均值跟标准差填补,这在某种程度上引入了噪声。后期学到更高级的估算,再回来修改。
for dataset in combination_data:
Age_avg = dataset.Age.mean()
Age_std = dataset["Age"].std()
missing_number = dataset["Age"].isnull().sum()
dataset["Age"][np.isnan(dataset["Age"])] = np.random.randint(Age_avg - Age_std, Age_avg + Age_std, missing_number)
dataset["Age"] = dataset["Age"].astype(int) F:Anacondalibsite-packagesipykernel_launcher.py:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""#仍是采用5组:
for dataset in combination_data:
dataset["Age_group"] = pd.cut(dataset.Age, 5)#现在我们以新的标识符来记录每人的分组:
for dataset in combination_data:
dataset.loc[dataset["Age"] <= 16,"Age"] = 0
dataset.loc[(dataset["Age"] > 16) & (dataset["Age"] <= 32), "Age"] = 1
dataset.loc[(dataset["Age"] > 32) & (dataset["Age"] <= 48), "Age"] = 2
dataset.loc[(dataset["Age"] > 48) & (dataset["Age"] <= 64), "Age"] = 3
dataset.loc[dataset["Age"] > 64, "Age"] = 4
for dataset in combination_data:
dataset.drop("Age_group",axis=1,inplace=True)- Fare
train.Fare.describe()count 891.000000
mean 32.204208
std 49.693429
min 0.000000
25% 7.910400
50% 14.454200
75% 31.000000
max 512.329200
Name: Fare, dtype: float64sns.violinplot(y="Fare",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b95e7320>
部分票价数据偏大,但数量较少,数据整体分布较分散。最小值是0,最大值约为512。中位数是14.45,平均值是32.20。50%的票价集中在8-31之间。
#对比生死乘客的票价
sns.violinplot(y="Fare",x="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b95065c0>
可看到成功生存的乘客票价的中位数是比死亡乘客票价中位数大。票价较低的群体死亡率更高,粗略判断票价对生存有影响作用。
下面以具体数字去看不同Fare对生存率的影响:
train["Fare_group"] = pd.qcut(train["Fare"],4) #分段
train[["Fare_group","Survived"]].groupby("Fare_group",as_index=False).mean()| Fare_group | Survived | |
|---|---|---|
| 0 | (-0.001, 7.91] | 0.197309 |
| 1 | (7.91, 14.454] | 0.303571 |
| 2 | (14.454, 31.0] | 0.454955 |
| 3 | (31.0, 512.329] | 0.581081 |
随着票价的升高,乘客的生存率也是逐渐升高。所以将Fare作为一个考虑特征。
测试集中Fare有两个缺失值,我们选择用中位数填补:
test["Fare"].fillna(test["Fare"].median(),inplace=True)for dataset in combination_data:
dataset.loc[dataset["Fare"] <= 7.91,"Fare"] = 0
dataset.loc[(dataset["Fare"] > 7.91) & (dataset["Fare"] <= 14.454), "Fare"] = 1
dataset.loc[(dataset["Fare"] > 14.454) & (dataset["Fare"] <= 31.0), "Fare"] = 2
dataset.loc[dataset["Fare"] > 31.0, "Fare"] = 3
dataset["Fare"] = dataset["Fare"].astype(int)del train["Fare_group"]字符型
Name
成员的名字没有重复项,本可删掉。但从别人的文章得知,外国人的名字长度、头衔也能反映一个人的身份地位,于是我们来探究一下这两个因素对生存率的影响:
(1)名字长度
for dataset in combination_data:
dataset["The_length_of_name"] = dataset["Name"].map(lambda x:len(re.split(" ",x)))train[["The_length_of_name","Survived"]].groupby("The_length_of_name",as_index=False).mean().sort_values("Survived",ascending=False)| The_length_of_name | Survived | |
|---|---|---|
| 6 | 9 | 1.000000 |
| 7 | 14 | 1.000000 |
| 4 | 7 | 0.842105 |
| 3 | 6 | 0.773585 |
| 5 | 8 | 0.555556 |
| 2 | 5 | 0.427083 |
| 1 | 4 | 0.340206 |
| 0 | 3 | 0.291803 |
sns.barplot(x="The_length_of_name",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49b96106a0>
名字长一点的生存率相对名字短的要高一点。考虑此新变量。
下面将名字的长度做标准化处理:
from sklearn.preprocessing import StandardScaler
Stdsca = StandardScaler()
name_length1 = Stdsca.fit_transform(train[["The_length_of_name"]])
name_length1 = pd.DataFrame(name_length1,columns=["name_length"])
train = pd.concat([train,name_length1],axis=1)#同理,test也做标准化处理
name_length2 = Stdsca.fit_transform(test[["The_length_of_name"]])
name_length2 = pd.DataFrame(name_length2,columns=["name_length"])
test = pd.concat([test,name_length2],axis=1)#把新数据联合起来
combination_data = [train,test]#删除原名字长度
for dataset in combination_data:
del dataset["The_length_of_name"](2)头衔
#查看一下名字的样式
train.Name.head(7)0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
5 Moran, Mr. James
6 McCarthy, Mr. Timothy J
Name: Name, dtype: object#将title取出当新的一列
for dataset in combination_data:
dataset["Title"] = dataset["Name"].str.extract("([A-Za-z]+).",expand=False)train.sample(4)| Survived | Pclass | Name | Sex | Age | Ticket | Fare | Cabin | Embarked | Family_size | Alone | name_length | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 271 | 1 | 3 | Tornquist, Mr. William Henry | male | 1 | LINE | 0 | NaN | S | 1 | 1 | -0.059474 | Mr |
| 389 | 1 | 2 | Lehmann, Miss. Bertha | female | 1 | SC 1748 | 1 | NaN | C | 1 | 1 | -0.914177 | Miss |
| 40 | 0 | 3 | Ahlin, Mrs. Johan (Johanna Persdotter Larsson) | female | 2 | 7546 | 1 | NaN | S | 2 | 0 | 1.649930 | Mrs |
| 709 | 1 | 3 | Moubarek, Master. Halim Gonios ("William George") | male | 1 | 2661 | 2 | NaN | C | 2 | 0 | 1.649930 | Master |
#title跟Sex有联系,联合起来分析
pd.crosstab(train.Title,train.Sex)| Sex | female | male |
|---|---|---|
| Title | ||
| Capt | 0 | 1 |
| Col | 0 | 2 |
| Countess | 1 | 0 |
| Don | 0 | 1 |
| Dr | 1 | 6 |
| Jonkheer | 0 | 1 |
| Lady | 1 | 0 |
| Major | 0 | 2 |
| Master | 0 | 40 |
| Miss | 182 | 0 |
| Mlle | 2 | 0 |
| Mme | 1 | 0 |
| Mr | 0 | 517 |
| Mrs | 125 | 0 |
| Ms | 1 | 0 |
| Rev | 0 | 6 |
| Sir | 0 | 1 |
#Title较多集中于Master、Miss、Mr、Mrs,对于其他比较少的进行归类:
for dataset in combination_data:
dataset[‘Title‘] = dataset[‘Title‘].replace([‘Lady‘, ‘Countess‘,‘Capt‘, ‘Col‘,‘Don‘, ‘Dr‘, ‘Major‘, ‘Rev‘, ‘Sir‘, ‘Jonkheer‘, ‘Dona‘], ‘Rare‘)
dataset[‘Title‘] = dataset[‘Title‘].replace(‘Mlle‘, ‘Miss‘)
dataset[‘Title‘] = dataset[‘Title‘].replace(‘Ms‘, ‘Miss‘)
dataset[‘Title‘] = dataset[‘Title‘].replace(‘Mme‘, ‘Mrs‘)#探索title与生存的关系
train[["Title","Survived"]].groupby("Title",as_index=False).mean().sort_values("Survived",ascending=False)| Title | Survived | |
|---|---|---|
| 3 | Mrs | 0.793651 |
| 1 | Miss | 0.702703 |
| 0 | Master | 0.575000 |
| 4 | Rare | 0.347826 |
| 2 | Mr | 0.156673 |
sns.barplot(x="Title",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49ba411048>
带女性title的乘客的生存率均超过70%,而title为Mr的男性乘客,生存率不到16%。可看出在当时灾难面前,女士的优势是较大的。考虑此新特征。
#将各头衔转换为数值型数据
for dataset in combination_data:
dataset["Title"] = dataset["Title"].map({"Mr":1,"Mrs":2,"Miss":3,"Master":4,"Rare":5})
dataset["Title"] = dataset["Title"].fillna(0)#删除原先的Name特征
for dataset in combination_data:
del dataset["Name"]#查看一下现在的数据
train.head(3)| Survived | Pclass | Sex | Age | Ticket | Fare | Cabin | Embarked | Family_size | Alone | name_length | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 1 | A/5 21171 | 0 | NaN | S | 2 | 0 | -0.059474 | 1 |
| 1 | 1 | 1 | female | 2 | PC 17599 | 3 | C85 | C | 2 | 0 | 2.504633 | 2 |
| 2 | 1 | 3 | female | 1 | STON/O2. 3101282 | 1 | NaN | S | 1 | 1 | -0.914177 | 3 |
- Sex
在分析title时,我们已知道性别对生存的影响存在,下面我们专门就Sex来研究一下:
train[["Sex","Survived"]].groupby("Sex",as_index=False).mean().sort_values("Survived",ascending=False)| Sex | Survived | |
|---|---|---|
| 0 | female | 0.742038 |
| 1 | male | 0.188908 |
sns.countplot(x="Sex",hue="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49bb53fe48>
明显看到,女性的生存率远高于男性。加入性别因素。
现加入Pclass,探究各船舱女性的生存率:
train[["Pclass","Sex","Survived"]].groupby(["Pclass","Sex"],as_index=False).mean().sort_values(by="Survived",ascending=False)| Pclass | Sex | Survived | |
|---|---|---|---|
| 0 | 1 | female | 0.968085 |
| 2 | 2 | female | 0.921053 |
| 4 | 3 | female | 0.500000 |
| 1 | 1 | male | 0.368852 |
| 3 | 2 | male | 0.157407 |
| 5 | 3 | male | 0.135447 |
sns.factorplot(x="Pclass",y="Survived",hue="Sex",data=train)<seaborn.axisgrid.FacetGrid at 0x49bb54a048>
从图表直观得出,不论船舱级别,女性的生存率始终高于男性。而且随着Pclass等级越高,人的生存率越高。一等舱的女性生存率超过96%,二等舱生存率为92%,三等舱生存率50%,高出一等舱男性的生存率(37%)。也反映出考虑特征Pclass的必要性。
#将字符串类型转换成数值型,0表示男性,1表示女性。
for dataset in combination_data:
dataset["Sex"] = dataset["Sex"].map({"male":0,"female":1})train.head(4)| Survived | Pclass | Sex | Age | Ticket | Fare | Cabin | Embarked | Family_size | Alone | name_length | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | A/5 21171 | 0 | NaN | S | 2 | 0 | -0.059474 | 1 |
| 1 | 1 | 1 | 1 | 2 | PC 17599 | 3 | C85 | C | 2 | 0 | 2.504633 | 2 |
| 2 | 1 | 3 | 1 | 1 | STON/O2. 3101282 | 1 | NaN | S | 1 | 1 | -0.914177 | 3 |
| 3 | 1 | 1 | 1 | 2 | 113803 | 3 | C123 | S | 2 | 0 | 2.504633 | 2 |
- Cabin
#从describe已知Cabin缺失较多
a = train.Cabin.isnull().sum()
print("缺失个数:%d" % a)缺失个数:687超过75%的数据缺失,故不打算填补。考虑以Cabin是否缺失来构建一个新特征,看是否对生存有影响。若没有影响,则删除该列。
train["Cabin_exist"] = train.Cabin.map(lambda x : "Yes" if type(x)==str else "No")
train[["Cabin_exist", "Survived"]].groupby("Cabin_exist",as_index=False).mean()| Cabin_exist | Survived | |
|---|---|---|
| 0 | No | 0.299854 |
| 1 | Yes | 0.666667 |
sns.barplot(x="Cabin_exist",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49bb6b8048>
当Cabin存在时,生存率超过65%,而Cabin不存在时,生存率不及30%。说明可构造新特征帮助预测生存与否。
#需将此列转换为数值型变量,删掉再构建一遍
del train["Cabin_exist"]#船舱存在用1表示,缺失则用0表示
for dataset in combination_data:
dataset["Cabin_exist"] = dataset["Cabin"].map(lambda x : 1 if type(x)==str else 0)#将原Cabin删掉
for dataset in combination_data:
del dataset["Cabin"]train.head(3)| Survived | Pclass | Sex | Age | Ticket | Fare | Embarked | Family_size | Alone | name_length | Title | Cabin_exist | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | A/5 21171 | 0 | S | 2 | 0 | -0.059474 | 1 | 0 |
| 1 | 1 | 1 | 1 | 2 | PC 17599 | 3 | C | 2 | 0 | 2.504633 | 2 | 1 |
| 2 | 1 | 3 | 1 | 1 | STON/O2. 3101282 | 1 | S | 1 | 1 | -0.914177 | 3 | 0 |
- Embarked
该列有缺失值。我们先研究一下不同的上船地点对生存率是否有影响:
train[["Embarked","Survived"]].groupby("Embarked",as_index=False).count().sort_values("Survived",ascending=False)| Embarked | Survived | |
|---|---|---|
| 2 | S | 644 |
| 0 | C | 168 |
| 1 | Q | 77 |
train[["Embarked","Survived"]].groupby("Embarked",as_index=False).mean().sort_values("Survived",ascending=False)| Embarked | Survived | |
|---|---|---|
| 0 | C | 0.553571 |
| 1 | Q | 0.389610 |
| 2 | S | 0.336957 |
sns.barplot(x="Embarked",y="Survived",data=train)<matplotlib.axes._subplots.AxesSubplot at 0x49bb78d518>
各口岸上船人数:S > C > Q。各口岸乘客生存率:C > Q > S,不同上岸地点对生存有影响,将Embarked作为建模特征。
下面探究一下加入Pclass因素的影响:
sns.factorplot(x="Pclass",y="Survived",hue="Embarked",data=train)<seaborn.axisgrid.FacetGrid at 0x49bb7974e0>
发现在Q口岸上船的乘客,船舱等级为2的乘客生存率 > 船舱等级为1的乘客生存率。与我们料想的不一致。而且在二等舱乘客中,Q口岸上船的生存率最高。
猜想是否是性别在其中影响:
train[["Sex","Survived","Embarked"]].groupby(["Sex","Embarked"],as_index=False).count().sort_values("Survived",ascending=False)| Sex | Embarked | Survived | |
|---|---|---|---|
| 2 | 0 | S | 441 |
| 5 | 1 | S | 203 |
| 0 | 0 | C | 95 |
| 3 | 1 | C | 73 |
| 1 | 0 | Q | 41 |
| 4 | 1 | Q | 36 |
S口岸,登船人数644,女性乘客占比46%;C口岸,登船人数168,女性占比接近77%;Q口岸,登船人数77,女性占比接近88%。前面已知女性生存率明显高于男性生存率,所以上述问题可能由性别因素引起。
缺失值处理:在查看数据集的时候,我们已知较多人在S口岸上岸,而Embarked缺失2个。于是我们选择用S来替换train的缺失值:
train["Embarked"] = train.Embarked.fillna("S")#将Embarked转换成数值型数据:
for dataset in combination_data:
dataset["Embarked"] = dataset["Embarked"].map({"C":0,"Q":1,"S":2}).astype(int)train.head(2)| Survived | Pclass | Sex | Age | Ticket | Fare | Embarked | Family_size | Alone | name_length | Title | Cabin_exist | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | A/5 21171 | 0 | 2 | 2 | 0 | -0.059474 | 1 | 0 |
| 1 | 1 | 1 | 1 | 2 | PC 17599 | 3 | 0 | 2 | 0 | 2.504633 | 2 | 1 |
- Ticket
train.Ticket.sample(10)749 335097
87 SOTON/OQ 392086
179 LINE
682 6563
629 334912
586 237565
159 CA. 2343
466 239853
539 13568
419 345773
Name: Ticket, dtype: object该列无缺失值,但信息较为混乱,有681个不重复值,删掉不做考虑。
for dataset in combination_data:
del dataset["Ticket"]特征选择
数据处理完毕,现在看一下我们的特征:
train.tail(4)| Survived | Pclass | Sex | Age | Fare | Embarked | Family_size | Alone | name_length | Title | Cabin_exist | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 887 | 1 | 1 | 1 | 1 | 2 | 2 | 1 | 1 | -0.059474 | 3 | 1 |
| 888 | 0 | 3 | 1 | 1 | 2 | 2 | 2 | 0 | 0.795228 | 3 | 0 |
| 889 | 1 | 1 | 0 | 1 | 2 | 0 | 1 | 1 | -0.059474 | 1 | 1 |
| 890 | 0 | 3 | 0 | 1 | 0 | 1 | 1 | 1 | -0.914177 | 1 | 0 |
test.head(4)| PassengerId | Pclass | Sex | Age | Fare | Embarked | Family_size | Alone | name_length | Title | Cabin_exist | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | 0 | 2 | 0 | 1 | 1 | 1 | -0.933840 | 1 | 0 |
| 1 | 893 | 3 | 1 | 2 | 0 | 2 | 2 | 0 | 0.716668 | 2 | 0 |
| 2 | 894 | 2 | 0 | 3 | 1 | 1 | 1 | 1 | -0.108586 | 1 | 0 |
| 3 | 895 | 3 | 0 | 1 | 1 | 2 | 1 | 1 | -0.933840 | 1 | 0 |
下面通过计算各个特征与标签的相关系数,来选择特征。
corr_df = train.corr()
corr_df| Survived | Pclass | Sex | Age | Fare | Embarked | Family_size | Alone | name_length | Title | Cabin_exist | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Survived | 1.000000 | -0.338481 | 0.543351 | -0.049290 | 0.295875 | -0.167675 | 0.108631 | -0.203367 | 0.278520 | 0.405921 | 0.316912 |
| Pclass | -0.338481 | 1.000000 | -0.131900 | -0.308842 | -0.628459 | 0.162098 | -0.043973 | 0.135207 | -0.222866 | -0.120491 | -0.725541 |
| Sex | 0.543351 | -0.131900 | 1.000000 | -0.087157 | 0.248940 | -0.108262 | 0.280570 | -0.303646 | 0.375797 | 0.564438 | 0.140391 |
| Age | -0.049290 | -0.308842 | -0.087157 | 1.000000 | 0.066096 | -0.039259 | -0.187662 | 0.144766 | 0.052876 | -0.194844 | 0.225237 |
| Fare | 0.295875 | -0.628459 | 0.248940 | 0.066096 | 1.000000 | -0.112248 | 0.559259 | -0.568942 | 0.320767 | 0.265495 | 0.497108 |
| Embarked | -0.167675 | 0.162098 | -0.108262 | -0.039259 | -0.112248 | 1.000000 | -0.004951 | 0.063532 | 0.032424 | -0.082845 | -0.160196 |
| Family_size | 0.108631 | -0.043973 | 0.280570 | -0.187662 | 0.559259 | -0.004951 | 1.000000 | -0.923090 | 0.311132 | 0.328943 | 0.088993 |
| Alone | -0.203367 | 0.135207 | -0.303646 | 0.144766 | -0.568942 | 0.063532 | -0.923090 | 1.000000 | -0.369259 | -0.289292 | -0.158029 |
| name_length | 0.278520 | -0.222866 | 0.375797 | 0.052876 | 0.320767 | 0.032424 | 0.311132 | -0.369259 | 1.000000 | 0.124584 | 0.184484 |
| Title | 0.405921 | -0.120491 | 0.564438 | -0.194844 | 0.265495 | -0.082845 | 0.328943 | -0.289292 | 0.124584 | 1.000000 | 0.104024 |
| Cabin_exist | 0.316912 | -0.725541 | 0.140391 | 0.225237 | 0.497108 | -0.160196 | 0.088993 | -0.158029 | 0.184484 | 0.104024 | 1.000000 |
#查看各特征与Survived的线性相关系数
corr_df["Survived"].sort_values(ascending=False)Survived 1.000000
Sex 0.543351
Title 0.405921
Cabin_exist 0.316912
Fare 0.295875
name_length 0.278520
Family_size 0.108631
Age -0.049290
Embarked -0.167675
Alone -0.203367
Pclass -0.338481
Name: Survived, dtype: float64正线性相关前三为:Sex、Title、Cabin_exist;负线性相关前三:Pclass、Alone、Embarked。
#用图形直观查看线性相关系数
plt.figure(figsize=(13,13))
plt.title("Pearson Correlation of Features")
sns.heatmap(corr_df,linewidths=0.1,square=True,linecolor="white",annot=True,cmap=‘YlGnBu‘,vmin=-1,vmax=1)<matplotlib.axes._subplots.AxesSubplot at 0x49bb8b0ef0>
看到特征Family_size跟Alone存在很强的线性相关性,留下Alone,删去Family_size。
for dataset in combination_data:
del dataset["Family_size"]test.head(3)| PassengerId | Pclass | Sex | Age | Fare | Embarked | Alone | name_length | Title | Cabin_exist | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | 0 | 2 | 0 | 1 | 1 | -0.933840 | 1 | 0 |
| 1 | 893 | 3 | 1 | 2 | 0 | 2 | 0 | 0.716668 | 2 | 0 |
| 2 | 894 | 2 | 0 | 3 | 1 | 1 | 1 | -0.108586 | 1 | 0 |
#查看删去Family_size的线性相关情况:
corr_df2 = train.corr()
corr_df2["Survived"].sort_values(ascending=False)Survived 1.000000
Sex 0.543351
Title 0.405921
Cabin_exist 0.316912
Fare 0.295875
name_length 0.278520
Age -0.049290
Embarked -0.167675
Alone -0.203367
Pclass -0.338481
Name: Survived, dtype: float64plt.figure(figsize=(13,13))
plt.title("Pearson Correlation of Features2")
sns.heatmap(corr_df2,linewidths=0.1,square=True,linecolor="white",annot=True,cmap=‘YlGnBu‘,vmin=-1,vmax=1)<matplotlib.axes._subplots.AxesSubplot at 0x49bbf756d8>
四.模型构建与评估
#划分训练集、训练集数据
#一般情况下,会用train_test_split来按比例划分数据集,但是Kaggle已经划分好,我们只需做预测并提交答案即可
x_train = train.drop("Survived",axis=1)
y_train =train["Survived"]
x_test = test.drop("PassengerId",axis=1)1.Logistic回归
from sklearn.linear_model import LogisticRegression
Classifier1 = LogisticRegression()
#训练模型
Classifier1.fit(x_train,y_train)
#预测
Y1_prediction = Classifier1.predict(x_test)
#模型评估
score_Logit = Classifier1.score(x_train,y_train)
score_Logit0.79685746352413023#各个特征对应的系数
Classifier1.coef_array([[-0.77898168, 2.00093191, -0.33760786, -0.08497359, -0.30653537,
0.20655901, 0.28367358, 0.37006791, 0.76227031]])Final = pd.DataFrame({"PassengerId":test["PassengerId"],
"Survived":Y1_prediction
})
Final.head(10)| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 0 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
| 5 | 897 | 0 |
| 6 | 898 | 1 |
| 7 | 899 | 0 |
| 8 | 900 | 1 |
| 9 | 901 | 0 |
Final.to_csv(r"G:KaggleTitanicFinal4.csv",index=False)Kaggle得分0.77990
Fare系数很小,这时候我们剔除Fare,看看效果:
#重新划分训练集、训练集数据
x1_train = train.drop(["Survived","Fare"],axis=1)
y1_train =train["Survived"]
x1_test = test.drop(["PassengerId","Fare"],axis=1)Classifier2 = LogisticRegression()
#训练模型
Classifier2.fit(x1_train,y1_train)
Y2_prediction = Classifier2.predict(x1_test)
#模型评估
score_Logit_2 = Classifier2.score(x1_train,y1_train)
score_Logit_20.79685746352413023Classifier2.coef_array([[-0.73467593, 2.00683788, -0.34049416, -0.31016514, 0.29292148,
0.27713963, 0.36168232, 0.73342319]])Final_2 = pd.DataFrame({"PassengerId":test["PassengerId"],
"Survived":Y2_prediction
})
Final_2.head(10)| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 0 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
| 5 | 897 | 0 |
| 6 | 898 | 1 |
| 7 | 899 | 0 |
| 8 | 900 | 1 |
| 9 | 901 | 0 |
Final_2.to_csv(r"G:KaggleTitanicFinal5.csv",index=False)提交kaggle后,得分降了。所以还是保存Fare。
2.KNN
from sklearn.neighbors import KNeighborsClassifier
Classifier3 = KNeighborsClassifier(n_neighbors=5)
Classifier3.fit(x_train,y_train)
Y3_prediction = Classifier3.predict(x_test)
#模型评估
score_Knn = Classifier3.score(x_train,y_train)
score_Knn0.82603815937149272Final_3 = pd.DataFrame({"PassengerId":test["PassengerId"],
"Survived":Y3_prediction
})
Final_3.head(10)| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 0 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
| 5 | 897 | 0 |
| 6 | 898 | 1 |
| 7 | 899 | 0 |
| 8 | 900 | 1 |
| 9 | 901 | 0 |
Final_3.to_csv(r"G:KaggleTitanicFinal6.csv",index=False)当k=3,kaggle评分0.74641;当k=5,kaggle评分0.77511.
3.决策树、随机森林
对这些算法还没深入了解,后期再回来补充。
# 决策树
#from sklearn.tree import DecisionTreeClassifier
#Classifier4 = DecisionTreeClassifier()
#Classifier4.fit(x_train,y_train)
#Y4_prediction = Classifier4.predict(x_test)
#score_Dtc = Classifier4.score(x_train,y_train)
#score_Dtc#随机森林
#from sklearn.ensemble import RandomForestClassifier
#Classifier5 = RandomForestClassifier(n_estimators=100)
#Classifier5.fit(x_train,y_train)
#Y5_prediction = Classifier5.predict(x_test)
#模型评估
#score_Rfc = Classifier5.score(x_train,y_train)
#score_Rfc五.总结
1.初次走了一遍机器学习的流程,并不算很全面,但是也熟悉了一遍流程,对numpy、pandas、matplotlib等包有所掌握。
2.对于缺失值的处理问题,还需熟悉数据,找到其缺失的原因,并以较好的方式去处理。有imputer,也有以其余数值型变量去估算缺失值的回归方法(RandomForestRegressor),这个要多看别人的文章,多去理解,并找机会练手。
3.对于数据的理解、数据的敏感还需要多加强,多学会用图去发现问题。对于特征互相之间能否构建出新的特征来帮助预测,后面需多去分析。
以上是关于泰坦尼克号生存预测的主要内容,如果未能解决你的问题,请参考以下文章