分布式计算框架MapReduce
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式计算框架MapReduce相关的知识,希望对你有一定的参考价值。
MapReduce概述
MapReduce源自Google的MapReduce论文,论文发表于2004年12月。Hadoop MapReduce可以说是Google MapReduce的一个开源实现。MapReduce优点在于可以将海量的数据进行离线处理,并且MapReduce也易于开发,因为MapReduce框架帮我们封装好了分布式计算的开发。而且对硬件设施要求不高,可以运行在廉价的机器上。MapReduce也有缺点,它最主要的缺点就是无法完成实时流式计算,只能离线处理。
MapReduce属于一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce官方文档地址如下:
在学习MapReduce之前我们需要准备好Hadoop的环境,也就是需要先安装好HDFS以及YARN,环境的搭建方式可以参考我之前的两篇文章:HDFS伪分布式环境搭建 以及 分布式资源调度——YARN框架
从WordCount案例说起MapReduce编程模型
在安装Hadoop时,它就自带有一个WordCount的案例,这个案例是统计文件中每个单词出现的次数,也就是词频统计,我们在学习大数据开发时,一般都以WordCount作为入门。
例如,我现在有一个test.txt,文件内容如下:
hello world
hello hadoop
hello MapReduce现在的需求是统计这个文件中每个单词出现的次数。假设我现在写了一些代码实现了这个文件的词频统计,统计的结果如下:
hello 3
world 1
hadoop 1
MapReduce 1以上这就是一个词频统计的例子。
词频统计看起来貌似很简单的样子,一般不需要多少代码就能完成了,而且如果对shell脚本比较熟悉的话,甚至一句代码就能完成这个词频统计的功能。确实词频统计是不难,但是为什么还要用大数据技术去完成这个词频统计的功能呢?这是因为实现小文件的词频统计功能或许用简单的代码就能完成,但是如果是几百GB、TB甚至是PB级的大文件还能用简单的代码完成吗?这显然是不可能的,就算能也需要花费相当大的时间成本。
而大数据技术就是要解决这种处理海量数据的问题,MapReduce在其中就是充当一个分布式并行计算的角色,分布式并行计算能大幅度提高海量数据的处理速度,毕竟多个人干活肯定比一个人干活快。又回到我们上面所说到的词频统计的例子,在实际工作中很多场景的开发都是在WordCount的基础上进行改造的。例如,要从所有服务器的访问日志中统计出被访问得最多的url以及访问量最高的IP,这就是一个典型的WordCount应用场景,要知道即便是小公司的服务器访问日志通常也都是GB级别的。
使用MapReduce执行WordCount的流程示意图: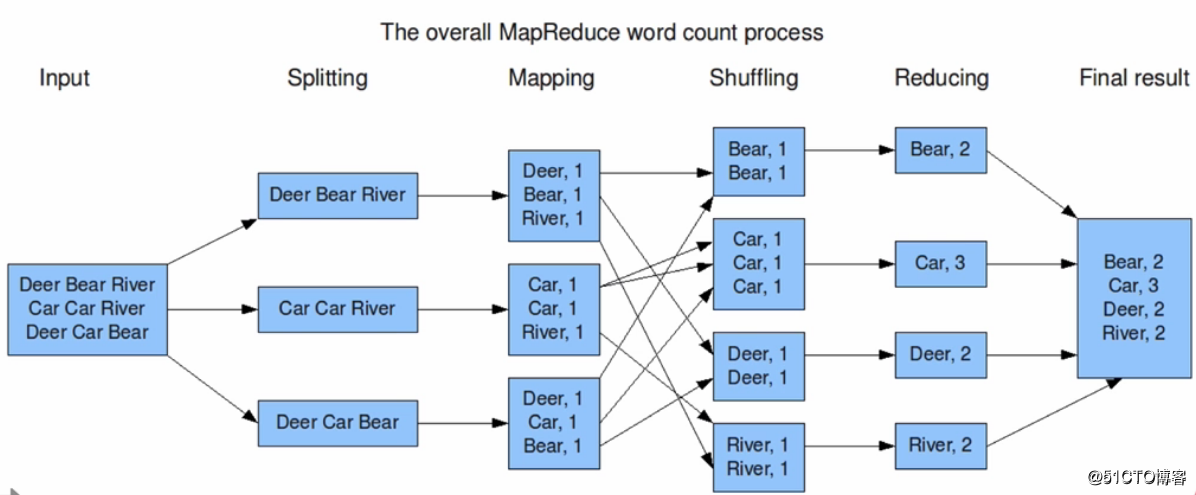
从上图中,可以看到,输入的数据集会被拆分为多个块,然后这些块都会被放到不同的节点上进行并行的计算。在Splitting这一环节会把单词按照分割符或者分割规则进行拆分,拆分完成后就到Mapping上了,到Mapping这个环节后会把相同的单词通过网络进行映射或者说传输到同一个节点上。接着这些相同的单词就会在Shuffling环节时进行洗牌也就是合并,合并完成之后就会进入Reducing环节,这一环节就是把所有节点合并后的单词再进行一次合并,也就是会输出到HDFS文件系统中的某一个文件中。大体来看就是一个拆分又合并的过程,所以MapReduce是分为map和Reduce的。最重要的是,要清楚这一流程都是分布式并行的,每个节点都不会互相依赖,都是相互独立的。
MapReduce执行流程
以上我们也提到了MapReduce是分为Map和Reduce的,也就是说一个MapReduce作业会被拆分成Map和Reduce阶段。Map阶段对应的就是一堆的Map Tasks,同样的Reduce阶段也是会对应一堆的Reduce Tasks。
其实简单来说这也是一个输入输出的流程,要注意的是在MapReduce框架中输入的数据集会被序列化成键/值对,map阶段完成后会对这些键值对进行排序,最后到reduce阶段中进行合并输出,输出的也是键/值对,官网文档写的流程如下:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)示意图: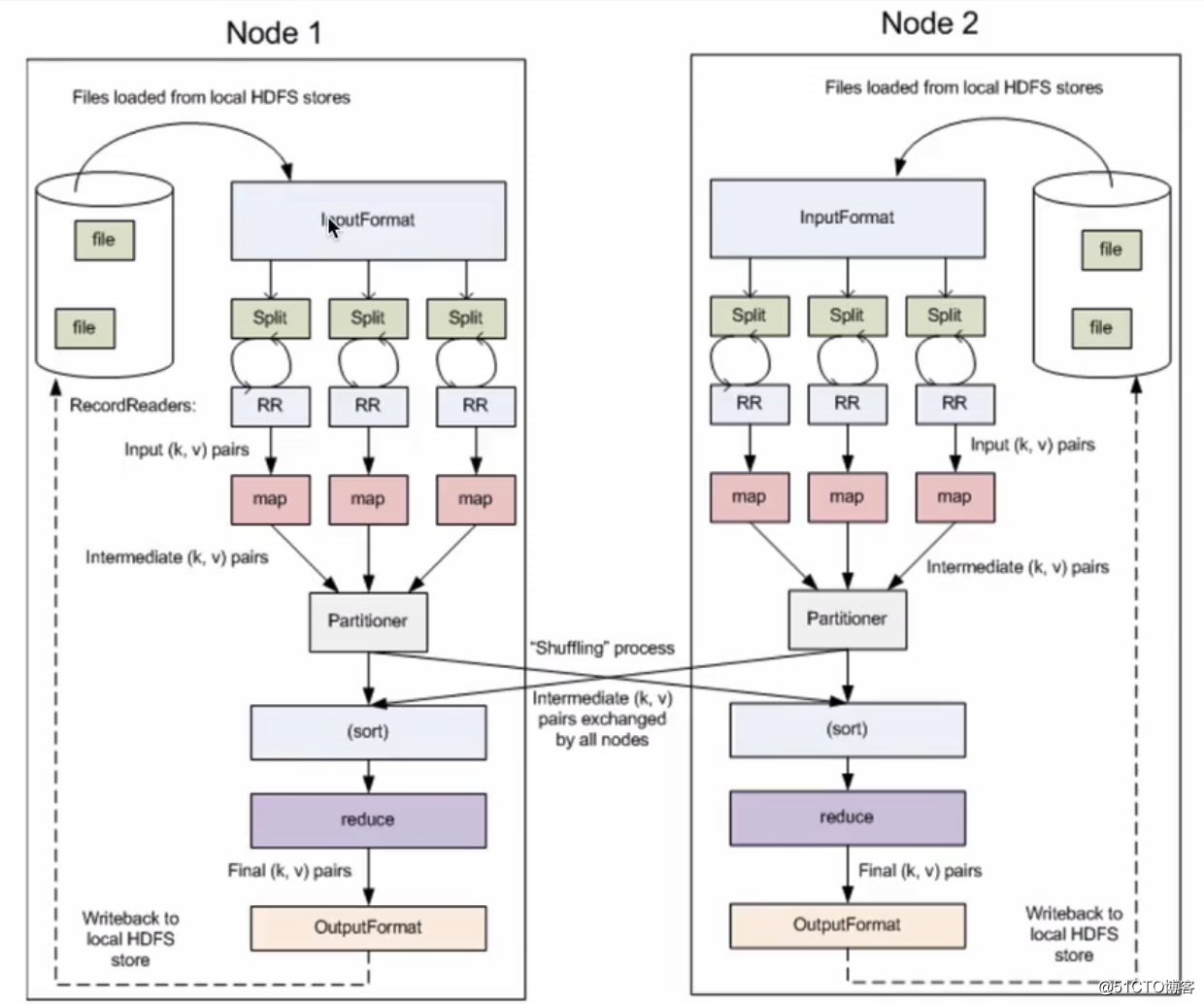
我们可以看到有几个主要的点:
- InputFormat:将我们输入数据进行分片(split)
- Split:将数据块交MapReduce作业来处理,数据块是MapReduce中最小的计算单元
- 在HDFS中,数据块是最小的存储单元,默认为128M
- 默认情况下,HDFS与MapReduce是一一对应的,当然我们也可以手动所设置它们之间的关系(但是不建议这么做)
- OutputFormat:输出最终的处理结果
我们可以再来看一张图,假设我们手动设置了block与split的对应关系,一个block对应两个split: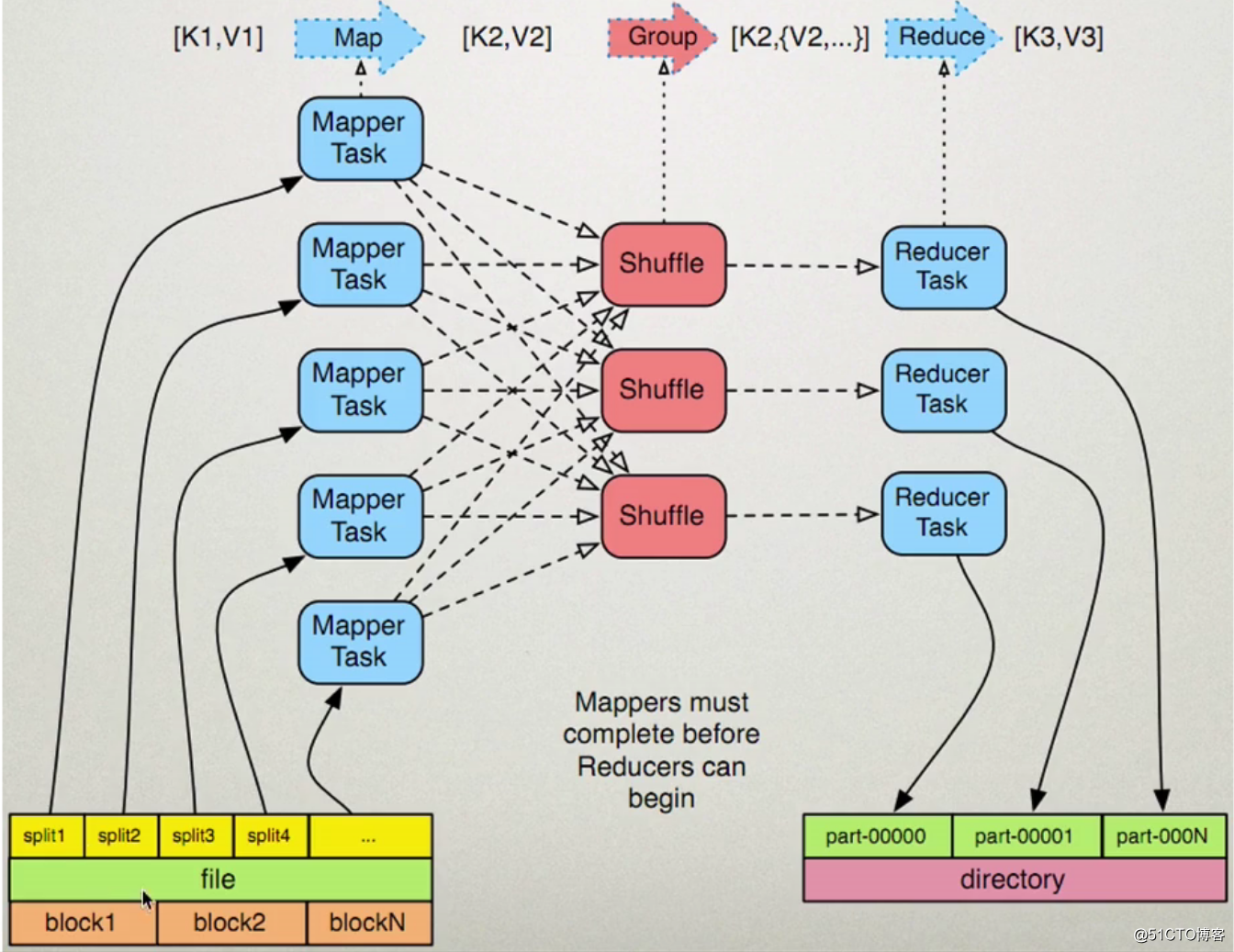
上图中一个block对应两个split(默认是一对一),一个split则是对应一个Map Task。Map Task将数据分完组之后到Shuffle,Shuffle完成后就到Reduce上进行输出,而每一个Reduce Tasks会输出到一个文件上,上图中有三个Reduce Tasks,所以会输出到三个文件上。
MapReduce1.x架构
MapReduce1.x架构图如下: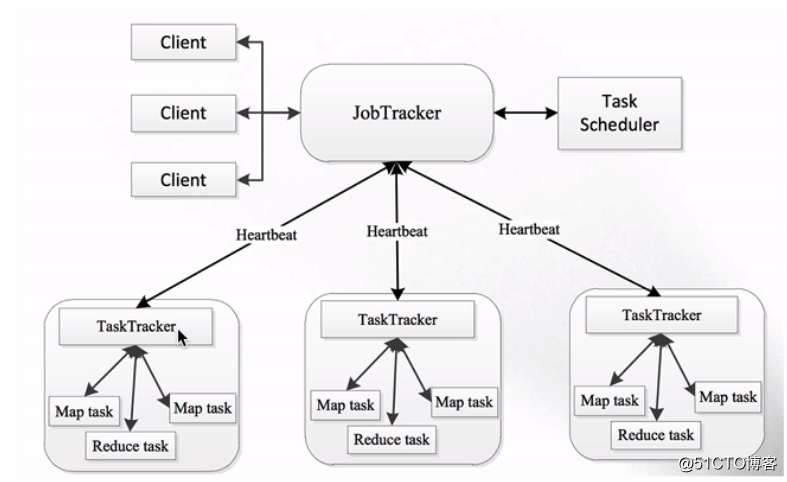
简单说明一下其中的几个组件:
- JobTracker:作业的管理者,它会将作业分解成一堆的任务,也就是Task,Task里包含MapTask和ReduceTask。它会将分解后的任务分派给TaskTracker进行运行,它还需要完成作业的监控以及容错处理(task作业挂掉了,会重启task)。如果在一定的时间内,JobTracker没有收到某个TaskTracker的心跳信息的话,就会判断该TaskTracker挂掉了,然后就会将该TaskTracker上运行的任务指派到其他的TaskTracker上去执行。
- TaskTracker:任务的执行者,我们的Task(MapTask和ReduceTask)都是在TaskTracker上运行的,TaskTracker可以与JobTracker进行交互,例如执行、启动或停止作业以及发送心跳信息给JobTracker等。
- MapTask:我们自己开发的Map任务会交由该Task完成,它会解析每条记录的数据,然后交给自己编写的Map方法进行处理,处理完成之后会将Map的输出结果写到本地磁盘。不过有些作业可能只有map没有reduce,这时候一般会将结果输出到HDFS文件系统里。
- ReduceTask:将MapTask输出的数据进行读取,并按照数据的规则进行分组,然后传给我们自己编写的reduce方法处理。处理完成后默认将输出结果写到HDFS。
MapReduce2.x架构
MapReduce2.x架构图如下,可以看到JobTracker和TaskTracker已经不复存在了,取而代之的是ResourceManager和NodeManager。不仅架构变了,功能也变了,2.x之后新引入了YARN,在YARN之上我们可以运行不同的计算框架,不再是1.x那样只能运行MapReduce了: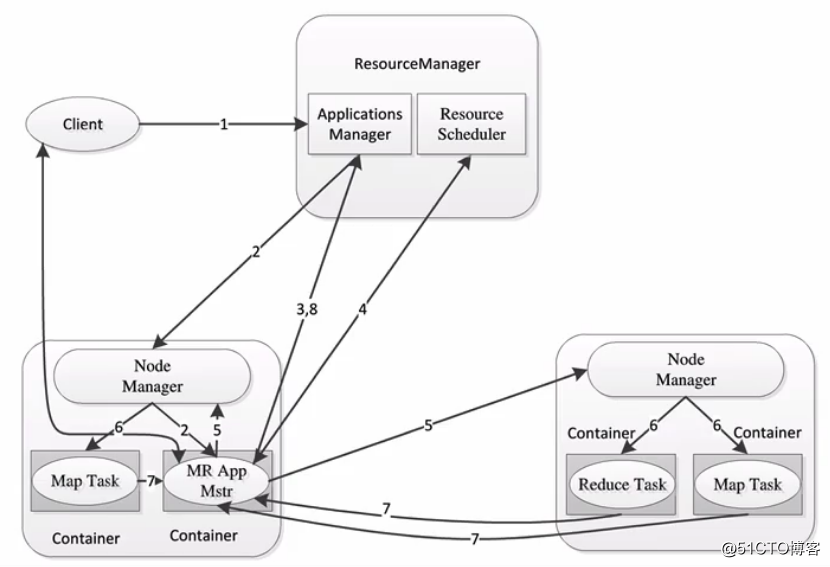
关于MapReduce2.x的架构之前已经在分布式资源调度——YARN框架一文中说明过了,这里就不再赘述了。
Java版本wordcount功能实现
1.创建一个Maven工程,配置依赖如下:
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>2.创建一个类,开始编写我们wordcount的实现代码:
package org.zero01.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @program: hadoop-train
* @description: 使用MapReduce开发WordCount应用程序
* @author: 01
* @create: 2018-03-31 14:03
**/
public class WordCountApp {
/**
* Map: 读取输入的文件内容
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
LongWritable one = new LongWritable(1);
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
// 按照指定的分割符进行拆分
String[] words = line.split(" ");
for (String word : words) {
// 通过上下文把map的处理结果输出
context.write(new Text((word)), one);
}
}
}
/**
* Reduce: 归并操作
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
// 求key出现的次数总和
sum += value.get();
}
// 将最终的统计结果输出
context.write(key, new LongWritable(sum));
}
}
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
// 创建Job,通过参数设置Job的名称
Job job = Job.getInstance(configuration, "wordcount");
// 设置Job的处理类
job.setJarByClass(WordCountApp.class);
// 设置作业处理的输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置reduce相关参数
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置作业处理完成后的输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}3.编写完成之后,在IDEA里通过Maven进行编译打包:
4.把打包好的jar包上传到服务器上:
测试文件内容如下:
[[email protected] ~]# hdfs dfs -text /test.txt
hello world
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
hello hadoop
[[email protected] ~]# 5.然后执行如下命令执行Job:
[[email protected] ~]# hadoop jar ./hadoop-train-1.0.jar org.zero01.hadoop.mapreduce.WordCountApp /test.txt /output/wc简单说明一下这个命令:
- hadoop jar 是Hadoop执行jar包的命令
- ./hadoop-train-1.0.jar 是jar包的所在路径
- org.zero01.hadoop.mapreduce.WordCountApp 是jar包的主类也就是main类
- /test.txt 是测试文件也就是输入文件所在路径(HDFS上的路径)
- /output/wc 为输出文件的存在路径
6.到YARN上查看任务执行的信息:
申请资源:
运行: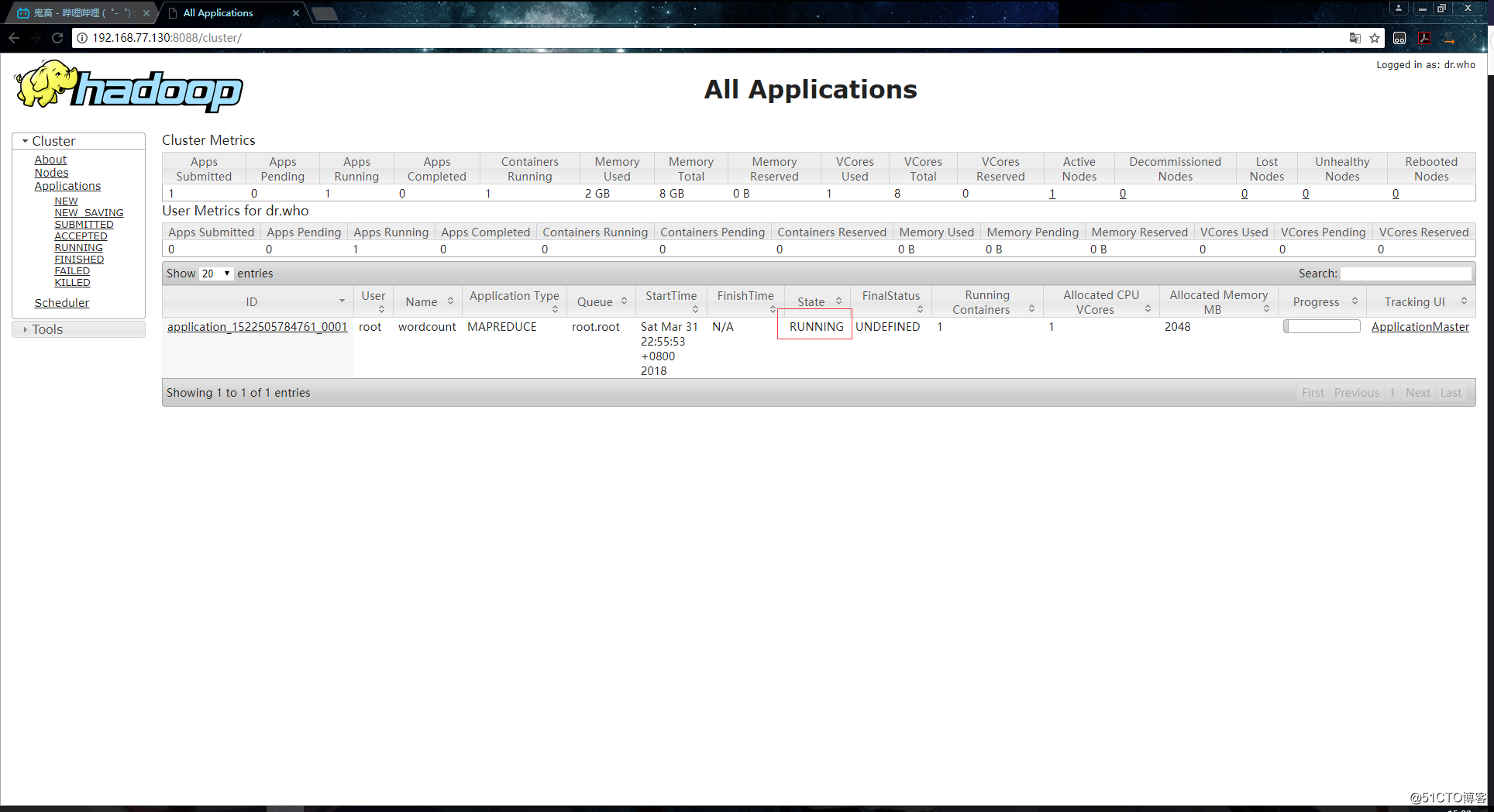
完成: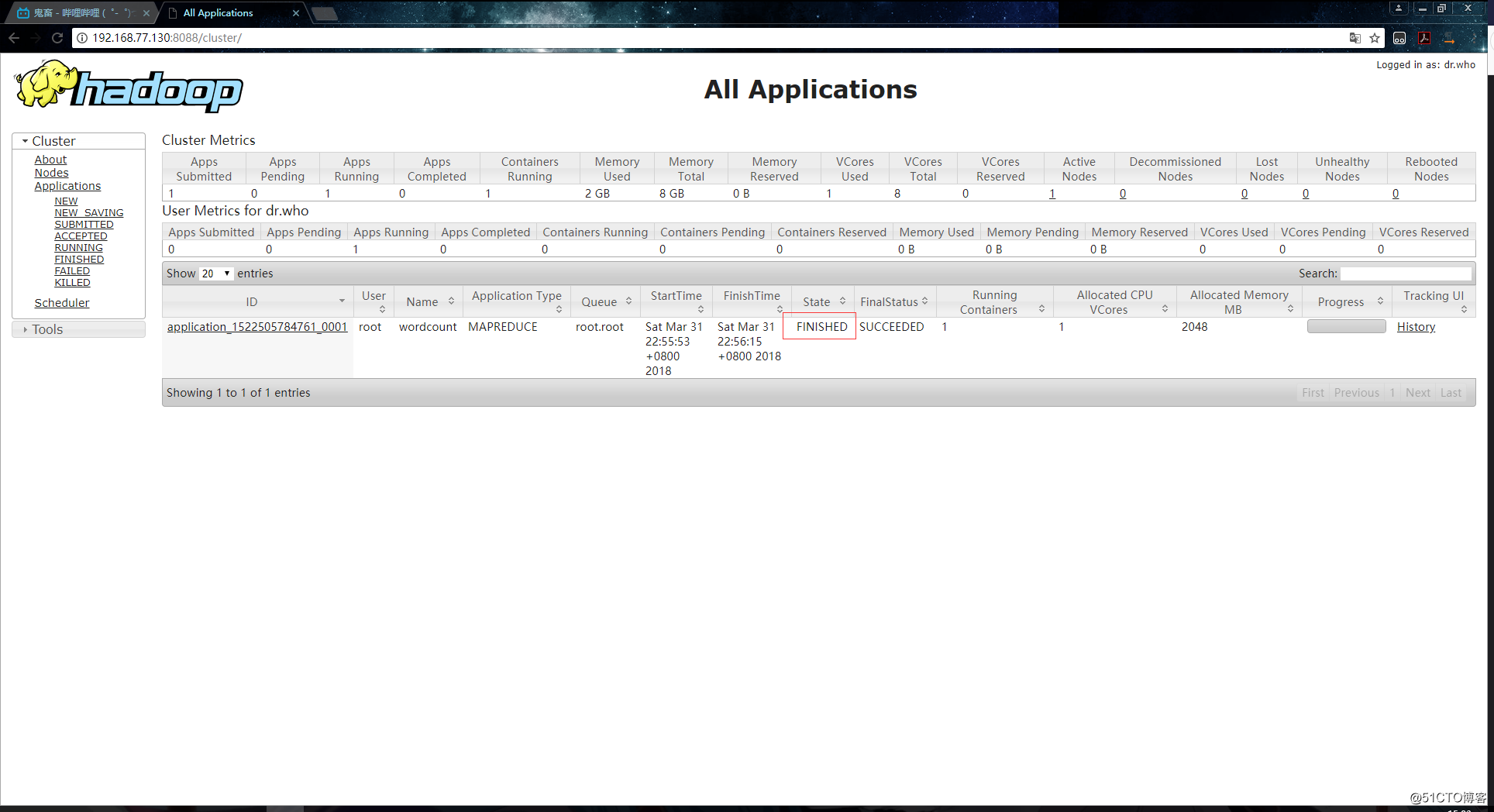
7.可以看到已经执行成功,命令行终端的日志输出内容如下:
18/03/31 22:55:51 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/03/31 22:55:52 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/03/31 22:55:52 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/03/31 22:55:53 INFO input.FileInputFormat: Total input paths to process : 1
18/03/31 22:55:53 INFO mapreduce.JobSubmitter: number of splits:1
18/03/31 22:55:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1522505784761_0001
18/03/31 22:55:54 INFO impl.YarnClientImpl: Submitted application application_1522505784761_0001
18/03/31 22:55:54 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1522505784761_0001/
18/03/31 22:55:54 INFO mapreduce.Job: Running job: job_1522505784761_0001
18/03/31 22:56:06 INFO mapreduce.Job: Job job_1522505784761_0001 running in uber mode : false
18/03/31 22:56:06 INFO mapreduce.Job: map 0% reduce 0%
18/03/31 22:56:11 INFO mapreduce.Job: map 100% reduce 0%
18/03/31 22:56:16 INFO mapreduce.Job: map 100% reduce 100%
18/03/31 22:56:16 INFO mapreduce.Job: Job job_1522505784761_0001 completed successfully
18/03/31 22:56:16 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=190
FILE: Number of bytes written=223169
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=174
HDFS: Number of bytes written=54
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3151
Total time spent by all reduces in occupied slots (ms)=2359
Total time spent by all map tasks (ms)=3151
Total time spent by all reduce tasks (ms)=2359
Total vcore-seconds taken by all map tasks=3151
Total vcore-seconds taken by all reduce tasks=2359
Total megabyte-seconds taken by all map tasks=3226624
Total megabyte-seconds taken by all reduce tasks=2415616
Map-Reduce Framework
Map input records=5
Map output records=11
Map output bytes=162
Map output materialized bytes=190
Input split bytes=100
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=190
Reduce input records=11
Reduce output records=6
Spilled Records=22
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=233
CPU time spent (ms)=1860
Physical memory (bytes) snapshot=514777088
Virtual memory (bytes) snapshot=5571788800
Total committed heap usage (bytes)=471859200
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=74
File Output Format Counters
Bytes Written=548.查看输出文件的内容:
[[email protected] ~]# hdfs dfs -ls /output/wc/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-03-31 22:56 /output/wc/_SUCCESS
-rw-r--r-- 1 root supergroup 54 2018-03-31 22:56 /output/wc/part-r-00000 # 执行结果的输出文件
[[email protected] ~]# hdfs dfs -text /output/wc/part-r-00000 # 查看文件内容
hadoop 4
hdfs 2
hello 2
mapreduce 1
welcome 1
world 1
[[email protected] ~]# Java版本wordcount功能重构
虽然我们已经成功通过编写java代码实现了wordcount功能,但是有一个问题,如果我们再执行刚刚那条命令,就会报如下错误:
[[email protected] ~]# hadoop jar ./hadoop-train-1.0.jar org.zero01.hadoop.mapreduce.WordCountApp /test.txt /output/wc
18/04/01 00:30:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/04/01 00:30:12 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/04/01 00:30:12 WARN security.UserGroupInformation: PriviledgedActionException as:root (auth:SIMPLE) cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.77.130:8020/output/wc already exists
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.77.130:8020/output/wc already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:270)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:143)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1304)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1693)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1304)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1325)
at org.zero01.hadoop.mapreduce.WordCountApp.main(WordCountApp.java:86)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
[[email protected] ~]# 在平时的MapReduce据程序开发中,这个异常非常地常见,这个异常是因为输出文件的存放目录已经存在:Output directory hdfs://192.168.77.130:8020/output/wc already exists
有两种方式可以解决这个问题:
- 在执行MapReduce作业时,先删除或更改输出文件的存放目录(不推荐)
- 在代码中完成自动删除功能(推荐)
我们来在代码中实现自动删除功能,在刚刚的代码中,加入如下内容:
...
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
// 准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
System.out.println("output file exists, but is has deleted");
}
...编写完成之后重新将编辑后的jar包上传,再执行hadoop jar ./hadoop-train-1.0.jar org.zero01.hadoop.mapreduce.WordCountApp /test.txt /output/wc命令,就不会再报错了。
Combiner应用程序开发
Combiner类似于本地的Reduce,相当于是在Map阶段的时候就做一个Reduce的操作,它能够减少Map Task输出的数据量及网络传输量。
如下图: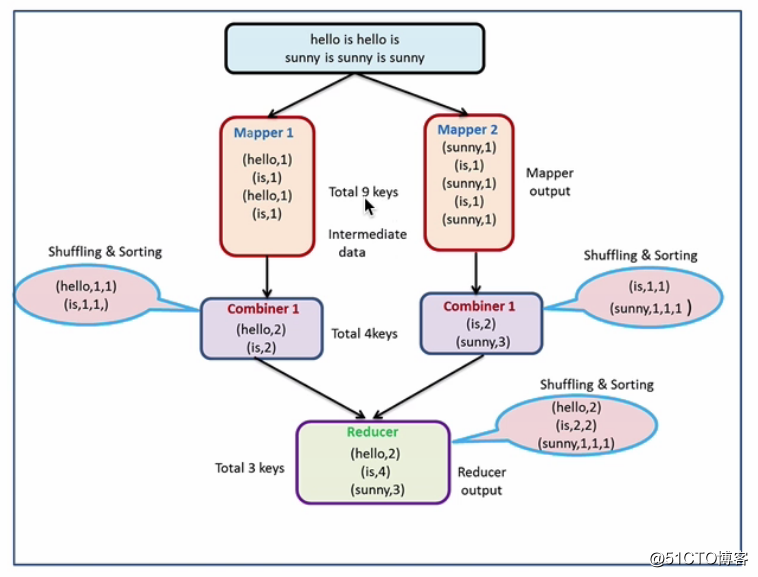
在上图中,可以看到Mapper与Reducer之间有一层Combiner。Mapper先把数据在本地进行一个Combiner,也就是先做一个本地数据的合并,这个过程类似于Reduce只不过是本地的,也即是本节点。当Combiner合并完成之后,再把数据传输到Reducer上再一次进行最终的合并。这样Map Task输出的数据量就会大大减少,性能也会相应的提高,这一点可以从上图中看到。
我们来尝试一下在刚才开发的wordcount程序中,增加一层Combiner。增加Combiner很简单,只需要在设置map和reduce参数的代码之间增加一行代码即可,如下:
// 通过Job对象来设置Combiner处理类,在逻辑上和reduce是一样的
job.setCombinerClass(MyReducer.class);修改完成并重新上传jar包后,这时再执行wordcount程序,在终端的日志输出信息中,会发现Combiner相关的字段都有值,那么就代表我们的Combiner已经成功添加进去了: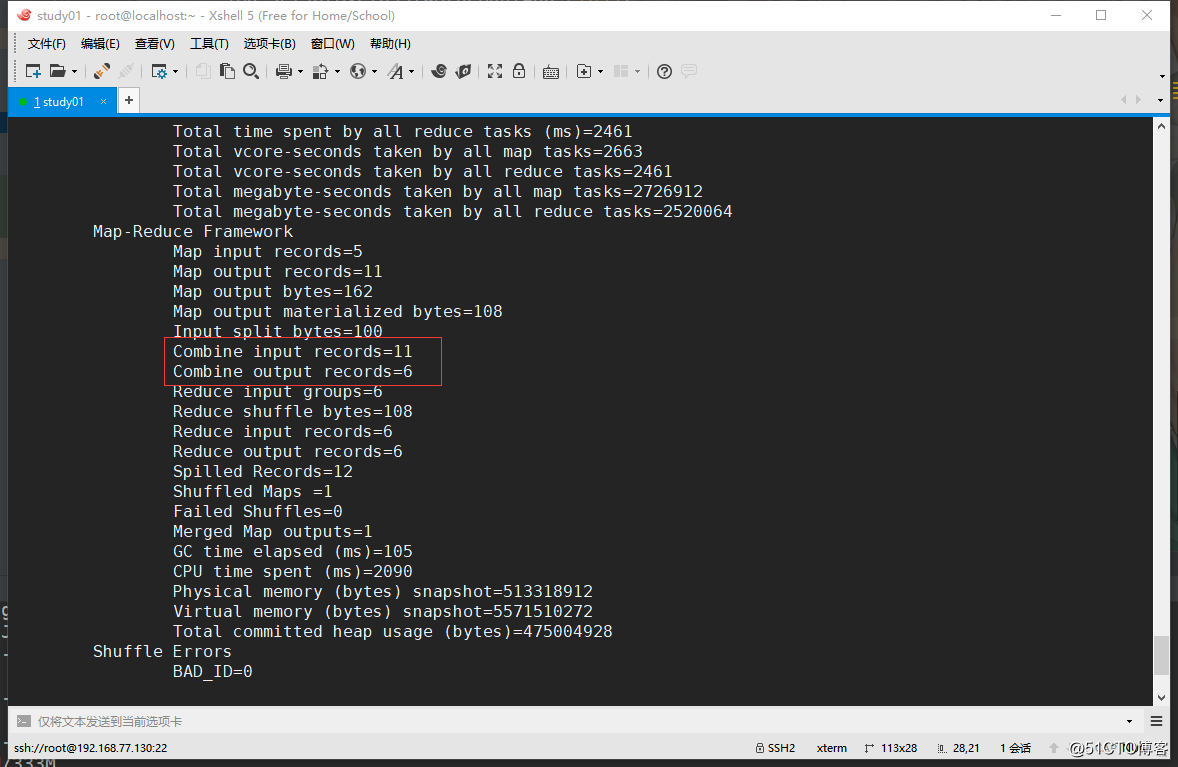
Combiner的适用场景:
- 求和、计数,累计类型的场景适合使用
Combiner的不适用的场景:
- 求平均数、求公约数等类型的操作不适合,如果这种场景下使用Combiner,得到的结果就是错误的
Partitioner应用程序开发
Partitioner决定Map Task输出的数据交由哪个Reduce Task处理,也就是类似于制定一个分发规则。默认情况下的分发规则实现:分发的key的hash值对Reduce Task个数取模。
如下图: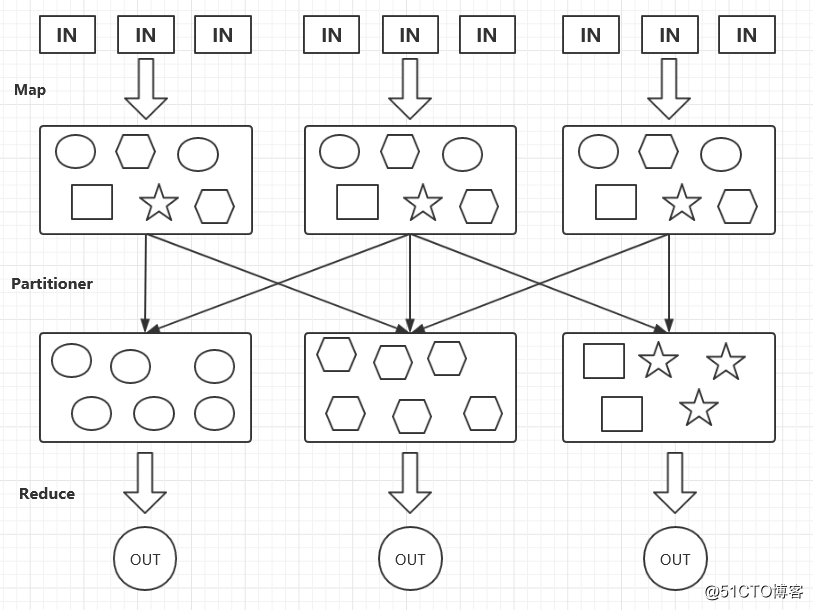
上图中,把圆形数据放到了同一个Reduce Task上,把六边形数据放到了同一个Reduce Task上,剩下的图形数据则放到剩下的Reduce Task上, 这样的一个分发过程就是Partitioner。
例如,我现在有一组数据如下,这是今日各个手机品牌的销售量:
[[email protected] ~]# hdfs dfs -text /partitioner.txt
xiaomi 200
huawei 300
xiaomi 100
iphone7 300
iphone7 500
nokia 100
[[email protected] ~]#现在我有一个需求,就是将相同品牌的手机名称,分发到同一个Reduce上进行处理。这就需要用到Partitioner了,在我们之前的代码中增加如下内容:
public class WordCountApp {
/**
* Map: 读取输入的文件内容
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
// 按照指定的分割符进行拆分
String[] words = line.split(" ");
// 通过上下文把map的处理结果输出
context.write(new Text((words[0])), new LongWritable(Long.parseLong(words[1])));
}
}
...
/**
* Partitioner: 设定Map Task输出的数据的分发规则
*/
public static class MyPartitioner extends Partitioner<Text, LongWritable> {
public int getPartition(Text key, LongWritable value, int numPartitions) {
if(key.toString().equals("xiaomi")){
return 0;
}
if(key.toString().equals("huawei")){
return 1;
}
if(key.toString().equals("iphone7")) {
return 2;
}
return 3;
}
}
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
...
// 设置Job的partition
job.setPartitionerClass(MyPartitioner.class);
// 设置4个reducer,每个分区一个
job.setNumReduceTasks(4);
...
}
}同样的,修改了代码后需要重新编译打包,把新的jar上传到服务器上。然后执行命令:
[[email protected] ~]# hadoop jar ./hadoop-train-1.0.jar org.zero01.hadoop.mapreduce.WordCountApp /partitioner.txt /output/wc执行成功,此时可以看到/output/wc/目录下有四个结果文件,这是因为我们在代码上设置了4个reducer,并且可以看到内容都是正确的:
[[email protected] ~]# hdfs dfs -ls /output/wc/
Found 5 items
-rw-r--r-- 1 root supergroup 0 2018-04-01 04:37 /output/wc/_SUCCESS
-rw-r--r-- 1 root supergroup 11 2018-04-01 04:37 /output/wc/part-r-00000
-rw-r--r-- 1 root supergroup 11 2018-04-01 04:37 /output/wc/part-r-00001
-rw-r--r-- 1 root supergroup 13 2018-04-01 04:37 /output/wc/part-r-00002
-rw-r--r-- 1 root supergroup 10 2018-04-01 04:37 /output/wc/part-r-00003
[[email protected] ~]# for i in `seq 0 3`; do hdfs dfs -text /output/wc/part-r-0000$i; done
xiaomi 300
huawei 300
iphone7 800
nokia 100
[[email protected] ~]# JobHistory的配置
JobHistory是一个Hadoop自带的历史服务器,它用于记录已运行完的MapReduce信息到指定的HDFS目录下。我们都知道,执行了MapReduce任务后,可以在YARN的管理页面上查看到任务的相关信息,但是由于JobHistory默认情况下是不开启的,所以我们无法通过点击History查看历史信息: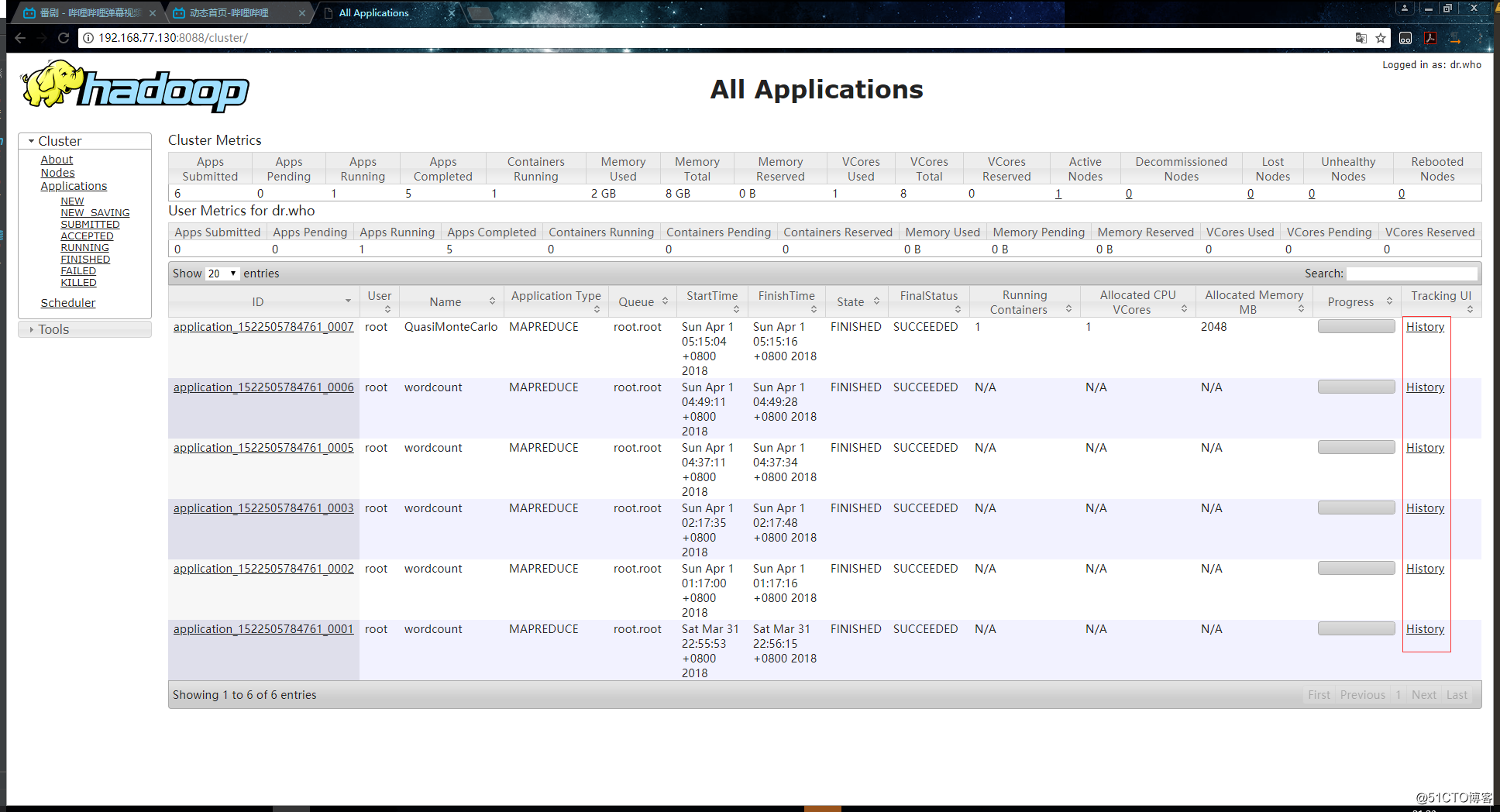
所以我们就需要打开这个服务,编辑配置文件内容:
[[email protected] ~]# cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim mapred-site.xml # 增加如下内容
<!-- jobhistory的通信地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.77.130:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<!-- jobhistory的web访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.77.130:19888</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<!-- 任务运行完成后,history信息所存放的目录 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!-- 任务运行中,history信息所存放的目录 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim yarn-site.xml # 增加如下内容
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.77.130:19888/jobhistory</value>
</property>
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# 编辑完配置文件后,重新启动YARN服务:
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# ./stop-yarn.sh
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# ./start-yarn.sh 启动JobHistory服务:
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# ./mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/mapred-root-historyserver-localhost.out
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# 检查进程:
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# jps
2945 DataNode
12946 JobHistoryServer
3124 SecondaryNameNode
12569 NodeManager
13001 Jps
2812 NameNode
12463 ResourceManager
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]#然后执行一个案例测试一下:
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce]# hadoop jar ./hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 3 4任务执行成功后,这时候访问http://192.168.77.130:19888就可以进入到JobHistory的web页面了: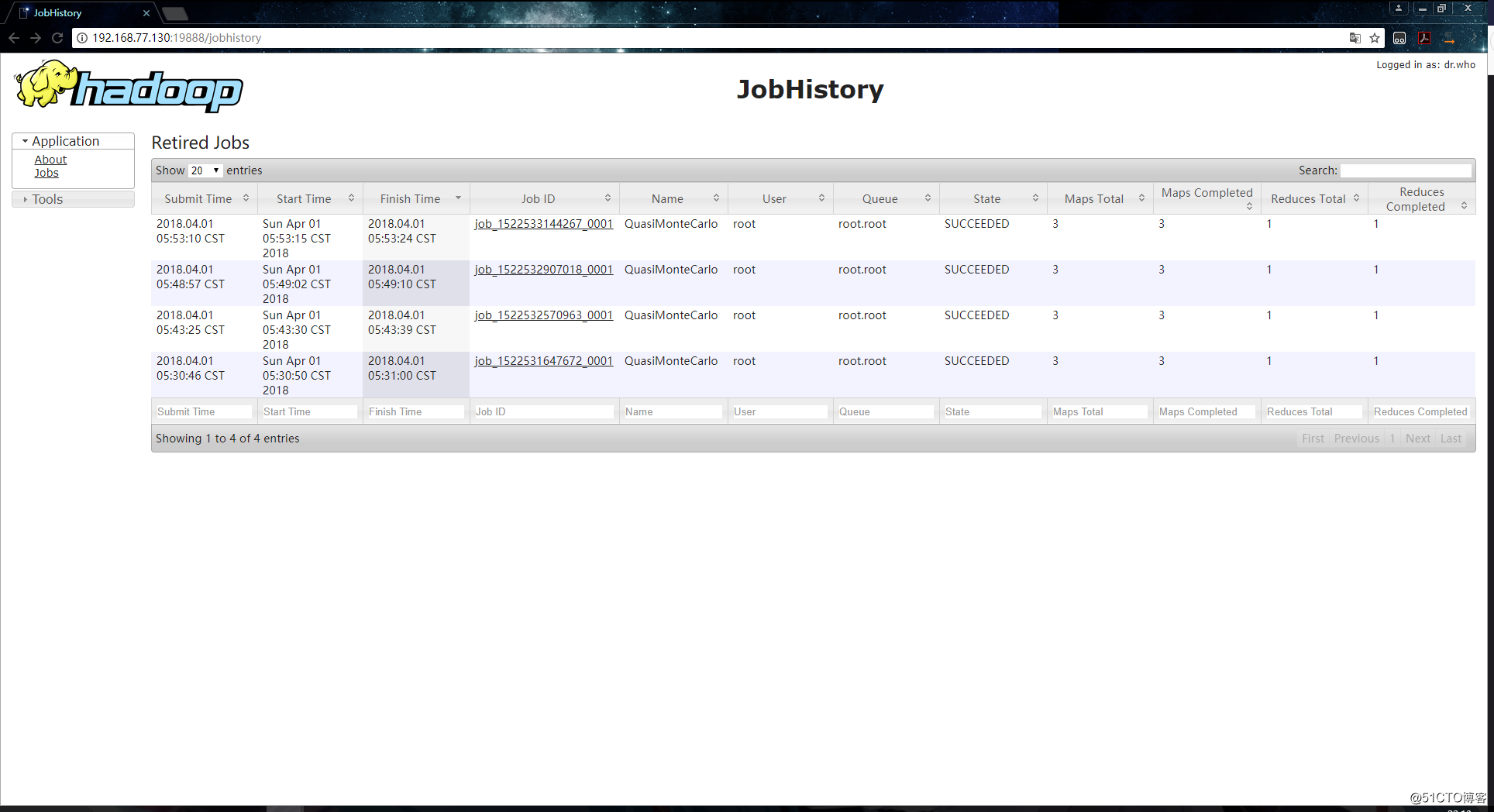
能够正常访问就代表配置已经成功了,现在所有任务的执行日志都可以在这里进行查看,有利于我们日常开发中的排错,而且ui界面操作起来也要方便一些。
以上是关于分布式计算框架MapReduce的主要内容,如果未能解决你的问题,请参考以下文章