分布式计算框架MapReduce
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式计算框架MapReduce相关的知识,希望对你有一定的参考价值。
MapReduce概述
- 源自于Google的MapReduce论文,论文发表于2004年2月
- Hadoop MapReduce 是 Google MapReduce 的克隆版
- MapReduce优点:海量数据离线处理 & 易开发(相对于自己开发分布式框架来说的,现在的Spark和Flink要比MapReduce更简单) & 易运行(可以本地开发本地测试)
- MapReduce缺点:实时流式计算
MapReduce编程模型
MapReduce编程模型之Map和Reduce阶段
- 将作业拆分成Map阶段和Reduce阶段
- Map阶段:Map Tasks
- Reduce阶段:ReduceTasks
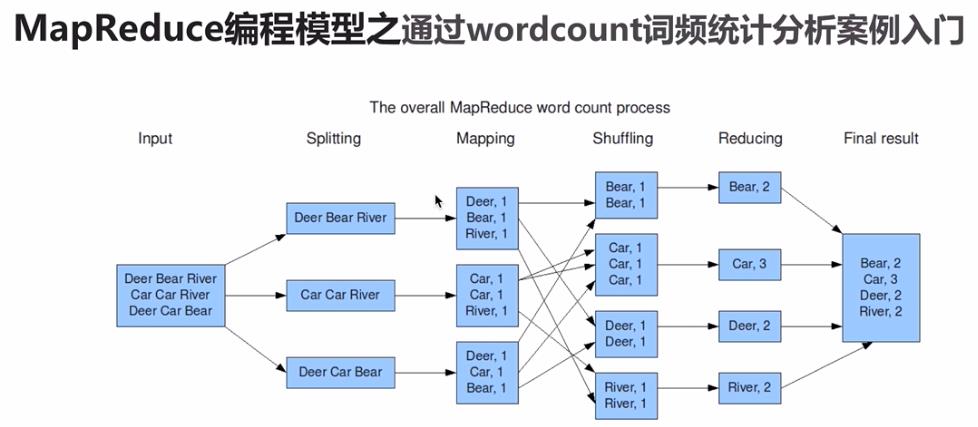
MapReduce变成模型之执行步骤
- 准备map处理的输入数据
- Mapper处理
- shuffle
- Reduce处理
- 结果输出
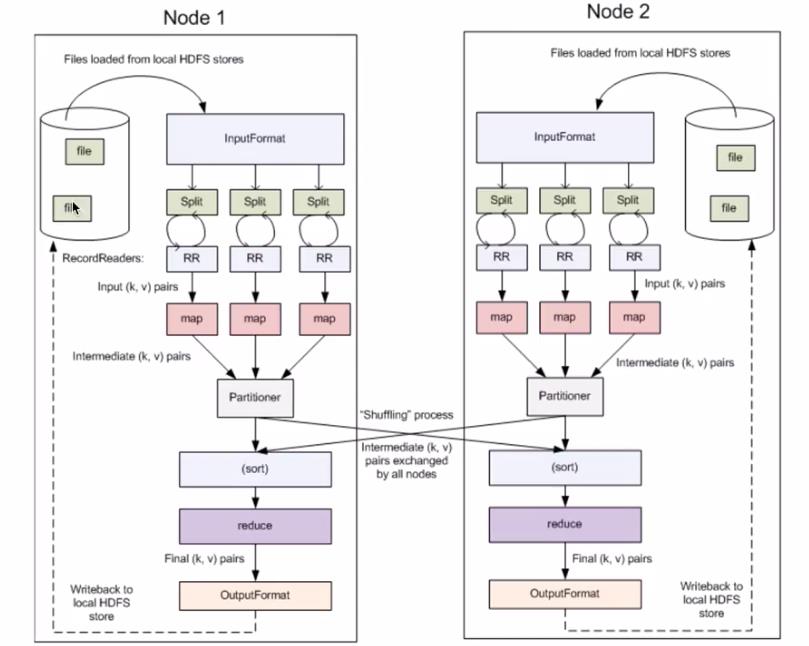
MapReduce编程模型核心概念详解
- Split
- InputFormat
- OutputFormat
- Combiner
- Partitioner
词频统计升级之Combiner操作
Combiner
- 优点:能减少IO,提升作业的执行性能
- 缺点:求平均数: 总数 / 个数, 其实可以理解为非求和操作都要慎重?
- 每个map求平均再到reducer求平均,与直接reducer求平均通常不一样。
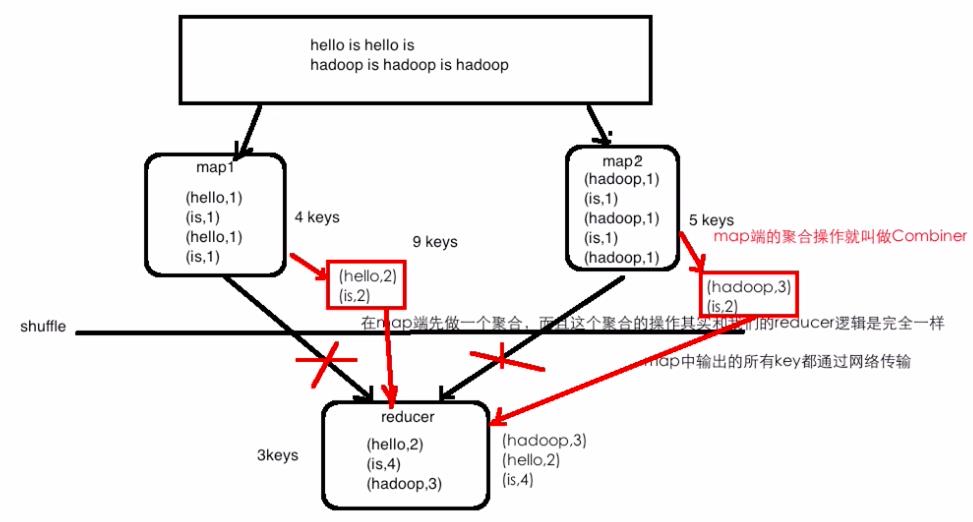
map端的聚合操作就叫做combiner。
设map1处理了1kw个单词,均是hello,is;map2也处理了1千万个单词,均是hadoop和is。则所有的这些中间结果都需要经过网络传输,即1kw个中间结果+1kw个中间结果(map中输出的所有key都通过网络传输),可想而知,性能不会好,此时若我们先在map端做一次聚合,则只需各传输两个中间结果【(hello, 2), (is, 2)】+ 【(hadoop, 3), (is, 2)】,可以节省网络的开销,即在map端先做一次聚合,且该聚合操作和reducer的逻辑是一样的。
报错
忘记加载主类、也没有提交
[WARN ] method:org.apache.hadoop.util.NativeCodeLoader.<clinit>(NativeCodeLoader.java:62)
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
参考:慕课网-Hadoop 系统入门+核心精讲
以上是关于分布式计算框架MapReduce的主要内容,如果未能解决你的问题,请参考以下文章