2018年3月11日论文阅读
Posted Ariel_一只猫的旅行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2018年3月11日论文阅读相关的知识,希望对你有一定的参考价值。
前言:每天至少读2-3篇文章,有精有泛;
1、多数文章看摘要,少数文章看全文;
2、最重要的是:自己要概括这篇文献到底说了什么,做好笔记和记录,否则等于白读!
3、看过的文章千万不可放置一旁再不过问,记得温故而知新。
4、阅读顺序:
先看abstract、introduction--->然后看discussion--->最后看result、method(结合图表来看,效率高)。
国外泛读!title(1):A Classification Refinement Strategy for Semantic Segmentation(一种用于语义分割的分类细化策略)---20180123(发布在arxiv的时间)
abstract:基于语义分割误差部分可预测的观察结果,我们提出了一种使用训练分类器的混淆统计的精简公式来改进(重新估计)初始像素标签假设。 所提出的策略取决于计算给定数据集的分类器混淆概率并且估计待分类图像中存在的对象类别的相关先验。 我们提供了一个程序来鲁棒地估计混淆概率并探索多个先前的定义。实验使用不同的先验来比较多个具有挑战性的数据集上的性能以改进最先进的语义分割分类器的性能。 这项研究表明,本文算法可以显著提高语义标签的潜力,并对从图像中获得可靠的标签预先估计的未来研究工作有着促进作用。
主旨:本文提出了一个贝叶斯框架来融合由混淆概率和标签先验所形成的上下文,用以实现像素级决策。
国外泛读!title(2):Classification and Disease Localization in Histopathology(组织病理学) Using Only Global Labels(仅使用全局标签进行组织病理学中的分类和疾病定位):A Weakly-Supervised Approach---20180201
abstract:
分析组织病理学的幻灯片是许多诊断的关键步骤,特别是在肿瘤学界定义黄金标准。在进行数字组织病理学分析的情况下,训练有素的病理学家必须在多个缩放级别中查看极端数字分辨率(100,000 2像素)的巨大整幅幻灯片图像,以确定单元的正常区域,或者单个单元格,超过数百万个单元格。深度学习在这个问题上的应用不仅受到小样本量的阻碍,因为典型的数据集只包含几百个样本,而且还通过生成用于训练可解释分类和分割模型的ground-truth本地化注释。我们提出了一种弱监督学习的疾病定位方法,其中只有图像级别的标签在训练期间可用。即使没有像素级注释,我们也能够证明性能可与Camelyon-16淋巴结转移检测挑战中强注释训练的模型相媲美。我们通过使用预先训练的深度卷积网络,特征嵌入以及通过顶级实例和负面证据进行学习,从语义分割和对象检测领域实施多实例学习技术来实现这一目标。
国内精读!title(3):Decoupled Spatial Neural Attention for Weakly Supervised Semantic Segmentation(弱监督语义分割的解耦空间神经注意结构)---20180307
abstract:弱监督语义分割得到了很多研究的关注,因为它减轻了为训练图像获得大量密集的像素ground-truth注释的需要。 与其他形式的弱监督相比,图像标签非常有效。 在我们的工作中,我们主要关注带有图像标注注释的弱监督语义分割。 这项任务的最近进展主要取决于生成的伪标注的质量。 在这项受空间神经注意力影响的图像标题的作品中,我们提出了一个用于生成伪注释的解耦空间神经关注网络。 我们的解耦关注结构可以同时识别对象区域并定位在一条正向路径中生成高质量伪标注的区分性部分。 通过生成的伪标注实现的分割结果,达到了弱监督语义分割的最先进水平。
1 introduction:语义分割是将语义标签分配给图像内的每个像素的任务。 近年来,深度卷积神经网络(DCNNs)[1] - [3]在语义分割性能方面有了很大的提高。 使用像素级ground-truth注释在完全监督环境中训练DCNN可实现最先进的语义分割精确度。 然而,这种完全监督设置的主要局限性在于为训练图像获得大量准确的像素级注释需要大量劳动力。 另一方面,只有图像级注释的数据集更容易获得。 因此,仅受图像标签监督的弱监督语义分割已受到很多关注。
通过引入高效的局部化提示,显着提高了图像级注释的弱监督语义分割性能[4] - [6]。在弱监督语义分割中使用最广泛的pipeline是首先基于定位线索估计训练图像的伪标注,然后利用伪标注作为ground-truth来训练分割DCNN。很明显,伪注释的质量直接影响最终的分割性能。在我们的工作中,我们遵循相同的流程,主要关注第一步,即仅为图像级标签生成训练图像的高质量伪标注。近年来,自顶向下的神经显著性[7] - [9]在弱监督定位任务中表现良好,因此被广泛应用于生成用于监督图像级标签的语义分割的伪注释。然而,在以前的研究中[6],这种自顶向下的神经显着性能很好地识别物体中最具区分性的区域,而不是物体的整个范围。因此,这些方法产生的伪注释远离地面真实注释。为了缓解这个问题,一些工作由多个临时处理步骤(例如迭代训练)组成,这些难以实施。有些工作引入了外部信息(如网页数据)来指导监督,极大地增加了数据和计算负担。相反,我们的工作提出了一条简单而有效实施的主要途径。
我们的目标是高效和有效地生成弱监督语义分割的伪注释。受广泛用于VQA [10]和图像字幕[11]的空间神经注意机制的启发,我们将空间神经注意引入到我们的伪注释生成pipeline,并提出了一个解耦空间神经关注结构,该结构同时在一个端到端框架中定位可区分部分并估计对象区域。 这样的结构有助于在一次正向传播中产生有效的伪标注。 图1为我们的解耦关注结构的简要描述。
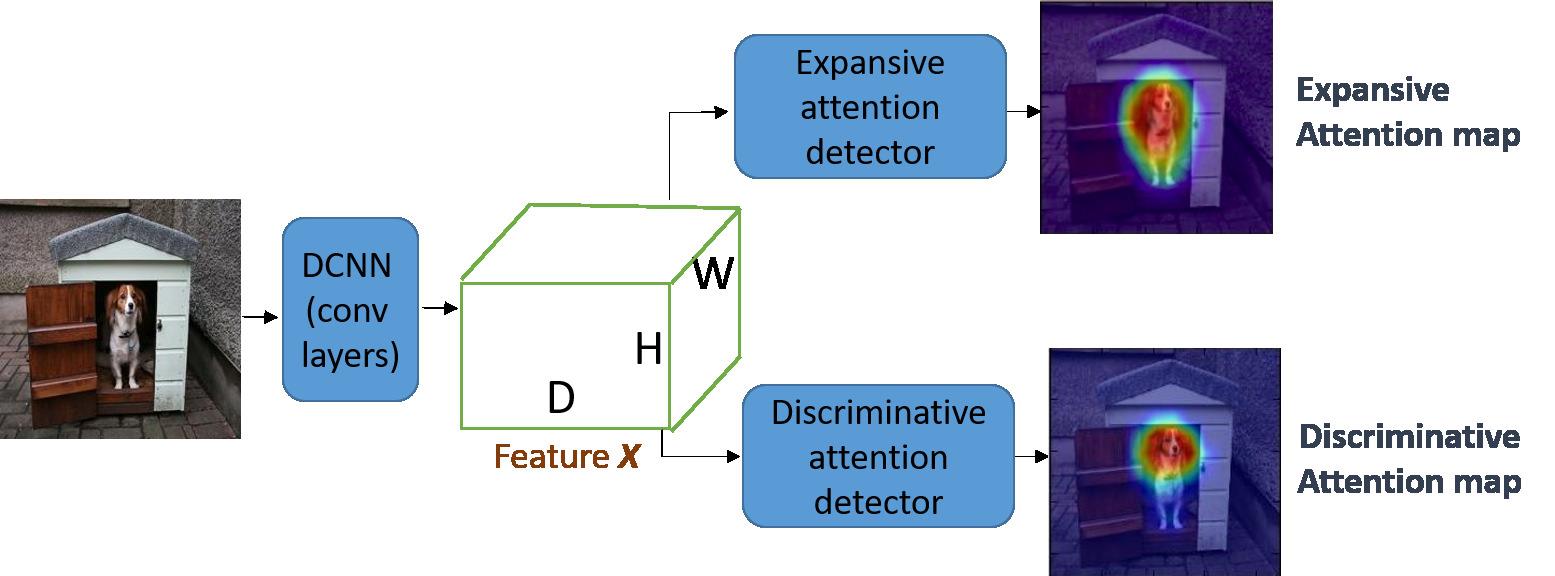
图1:它同时生成两张关注地图,即展开关注地图和区分性关注地图。 Expantive注意图是识别对象区域,而Discriminative注意图是挖掘可区分的部分。
我们的主要贡献可概括如下:
我们引入空间神经注意力,并提出一种解耦的注意力结构,用于为弱监督语义分割生成伪注释。
我们的解耦关注模型输出两个注意图,重点分别是识别对象区域和挖掘判别性部分。 这两张关注地图互相补充以生成高质量的伪标注。
我们采用简单而有效的pipeline,没有启发式多步迭代训练步骤,这与现有的大多数弱监督语义分割方法不同。
我们执行详细的消融实验来验证我们的解耦关注结构的有效性。 在Pascal VOC 2012图像分割基准测试中实现了最先进的弱监督语义分割结果。
2 related work:
A 弱监督语义分割
近年来,借助深度卷积神经网络(DCNN)[1],[3],[12] - [18],语义分割的性能得到了极大的提高。 在完全监督的pipeline中训练用于语义分割的DCNN需要像素级的ground-truth注释,这是非常耗时的。
因此,弱监督语义分割受到研究和关注,用以减轻训练数据的像素注释的工作量。 在弱监督设置中,图像级标签是最容易获得的注释。 至于用图像级标签进行语义分割,一些早期的工作[19,20]将这个问题作为多实例学习(MIL)问题来解决,如果其中至少有一个像素/超像素是正的,则为正;如果所有像素均为负数,则为负。其他早期工作[21]应用期望最大化(EM)处理过程,该过程在预测像素标签和优化DCNN参数之间交替进行。 但由于缺乏有效的定位线索,早期工作的表现不尽如人意。
在引入位置信息以生成用于分割DCNN的本地化种子/伪注释之后,具有图像级别标签的语义分割的性能显著改善。伪注释的质量直接影响分割结果。有几种方法可以估计伪标注。第一类是简单到复杂(STC)策略[22] - [24]。该类别中的方法假定可以通过显著性检测[22]或共分割[24]准确地估计简单图像(例如网页图像)的伪标注。然后利用在简单图像上训练的分割模型来生成复杂图像的伪标注。这一类的方法通常需要大量的外部数据,从而增加了数据和计算负担。第二类是基于区域挖掘的方法。这一类的方法依靠区域挖掘方法[7] - [9]来生成区分性种子的区分性区域。由于这些本地化种子主要稀疏地位于区分的部分,而不是远离ground-truth标注的物体的全部范围,因此许多工作试图通过将定位种子扩大到物体的大小来缓解这个问题。科列斯尼科夫等人[4]通过按照全局加权排序池汇总像素分数来扩大种子。魏等人[6]应用一种对抗 - 擦除方法,该方法在抑制最具区分性的图像区域和训练区域挖掘模型之间进行迭代。它通过多次迭代逐渐本地化下一个最具有区分性的区域,并将所有挖掘出的区分区域合并为最终的伪标注。“Similarly Two-phase”[25]通过两个阶段抑制和挖掘处理来捕获对象的全部范围。有些工作[5],[23]利用外部依赖性,如完全监督显著性方法[26]对附加显著性数据集进行训练,以便于估计对象尺度。
为了生成高质量的伪标注,第一类关注于训练数据的质量,而第二类关注于后处理与区域挖掘模型结构无关的定位种子。与以前的方法不同,我们将注意力放在设计一个可能突出目标区域的区域挖掘模型结构。 我们的目标是为了效率和简单性的目的,在没有外部数据或外部事先考虑的情况下为单一前向路径中的弱监督语义分割生成伪注释。
B 挖掘判别区域
在本节中,我们介绍一些区域挖掘方法,这些方法已被广泛用于生成具有图像级标签的语义分割的伪注释。最近的自顶向下神经显著性[7] - [9]在弱监督定位任务中表现良好。这工作基于图像分类DCNN识别对每个个体类别进行区域判别。 Zhang等人[8]提出激励Backprop在网络层次中反向传播以识别判别区域。 Zhou等人[7]提出了一种称为类激活映射(CAM)的技术,通过用卷积层和全局平均池化替换图像分类CNN中的全连接层来识别判别区域。 Grad-CAM [9]是CAM [7]的一个严格推广,不需要修改DCNN结构。在上述方法中,CAM [7]是弱监督语义分割[4],[6],[25]中应用最广泛的一种,用于生成伪标注。
C 空间注意机制
空间神经关注是一种根据特征内容为不同特征空间区域分配不同权重的机制。 它自动预测加权热图,以增强相关特征,并在特定任务的训练过程中阻止不相关特征。直观地说,这种加权热图可以应用于我们的伪注释生成。
空间神经关注机制已被证明对于许多任务都是有益的,比如图像字幕[11],[27],机器翻译[28],多标签分类[29],人体姿态估计[30]和显著性检测[31]。 与以前的工作不同,据我们所知,我们是第一个将注意力机制应用于弱监督语义分割。
3 approach
首先我们简要回顾了传统的空间神经关注模型,详见III-A部分。 其次,在第二部分介绍我们的解耦关注结构,详见III-B部分。 然后我们介绍如何进一步生成基于这个解耦注意模型的伪标注,详见III-C部分。 最后,将生成的伪标注用作ground-truth标注以训练DCNN分割网络。
A 传统的空间神经关注模型
在本节中,我们将简要介绍传统的空间神经关注机制。 传统的空间神经关注结构如图2所示。注意结构由两个模块化分支组成:主分支模块和注意检测模块。 注意力检测器模块与主分支模块端到端联合训练。
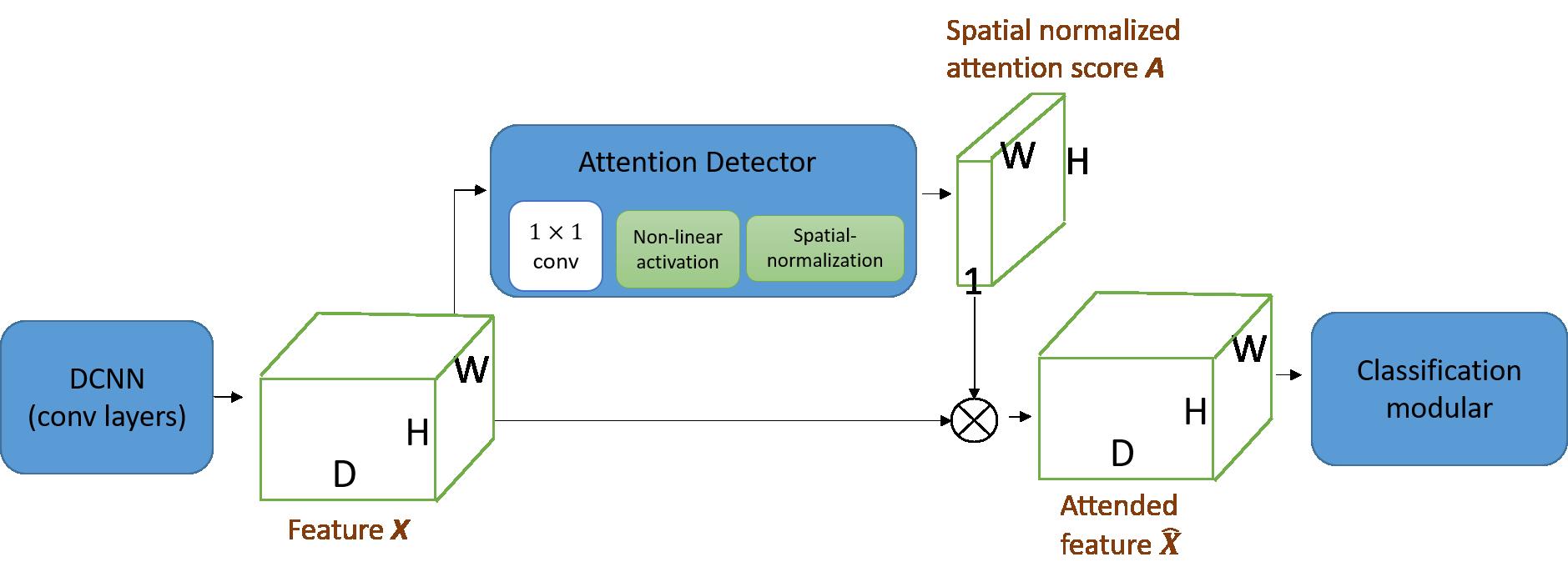
图2 传统的空间神经关注模型的结构说明
在形式上,我们用X∈R W×H×D表示一些卷积/积分层的输出特征。 注意力检测器以特征映射X∈R W×H×D为输入,并且输出空间归一化的注意权重映射A∈R W×H。 将A应用到X上以得到有特征的?X∈R W×H×D .X被馈入分类模块以输出图像分类得分向量p∈RC,其中C是类的数量。
为了表示起来简单,我们用大写字母表示DCNN的3-D特征输出,并在同一空间位置以相应的小写字母表示特征。 例如,x ij∈RD是位于(i,j)处X的特征。注意力检测器输出注意力权重映射A,A充当空间正则化器以增强相关区域并抑制特征X的不相关区域。 因此,我们有动机利用注意力检测器的输出为图像级标签的语义分割任务生成伪注释。 注意检测器模块的细节如下:注意检测器模块由卷积层,非线性激活层(方程(1))和空间归一化(方程(2))组成,如图2。

其中F是一个非线性激活函数,如[11],[30]中的指数函数。 w∈RD和b∈R1是注意检测器模型的参数,为1×1卷积层。 attended feature(不知该怎么翻译合适。。。参与特征?) 的
的
计算公式为:
分类模块作为图像分类器,由空间平均池化层和1×1卷积层组成。 我们将v c和h c表示为c类分类器的参数,因此c类的分类得分计算如下:

其中p c是第c类的得分。
B 解耦注意结构
如III-A部分所述,传统的空间神经注意力检测器的输出是类别不可知的。 但是,在语义分割任务中,每个图像可能包含多个类的对象。 因此,传统的类别不可知关注映射不适用于为这种多类别情况生成伪标注,因为我们需要为每个语义类别而不是仅仅前景/背景预测像素标签。另一方面,传统空间神经关注检测器旨在帮助图像分类的任务,其可能未必为弱监督的语义分割生成期望的伪标注。 受到[29]的启发,我们提出了解耦关注结构,特别是对于弱监督语义分割生成伪注释的任务,以减轻这些问题。
在图3中说明了我们的结构。这种结构将传统的关注结构扩展到多类案例。 此外,它还生成两种不同类型的关注地图,分别标识对象区域和预测可区别部分。 在图3中,由顶部分支中的扩展注意检测器生成的注意映射A∈RW×H×C被命名为扩展注意图,其目标是识别目标区域。 由分支注意力检测器生成的注意映射S∈R W×H×C被命名为判别注意图,旨在挖掘判别性部分。 这两个注意图具有不同的属性,这些属性彼此互补以生成用于弱监督语义分割的伪注释。

图3 我们提出的解耦关注结构。 Expansive注意检测器生成的热图被命名为Expansive注意图,用于识别对象区域。 Discriminative注意力检测器生成的热图被命名为Discriminative注意力图,它对可辨识的部分进行定位。
图3中的结构细节描述如下:
Expansive Attention检测器(E-A检测器)模块由卷积层,非线性激活层(方程(5))和空间归一化步骤(方程(6))组成:

上标/下标c表示第c个信道/类别的值。
正如我们在第二节中所提到的。 对于伪注释生成的任务,我们的目标是估计整个对象范围,而不是仅仅获取最具有判别性的部分。 因此,我们设计E-A检测器的细节如下:我们设置

 = 0.1,类似于[32]。除了注意检测器中的1×1卷积层之外,我们分别在其前后添加一个drop-out层。 这样的drop-out层随机地将训练特征中的元素归零,因此,注意力检测器将突出显示更多相关特征,而不是仅仅用于成功分类的最相关特征。
= 0.1,类似于[32]。除了注意检测器中的1×1卷积层之外,我们分别在其前后添加一个drop-out层。 这样的drop-out层随机地将训练特征中的元素归零,因此,注意力检测器将突出显示更多相关特征,而不是仅仅用于成功分类的最相关特征。
判别注意检测器(D-A检测器)由1×1卷积层组成,其参数表示为v c和h c,与III-A部分中的分类器相同。 D-A检测器以特征映射X为输入,输出特定类别的注意映射S∈R W×H×C。参与特征S∈R W×H×C的计算公式为:

S被喂入到空间平均池化层以生成图像分类评分p∈R C。 因此pc计算公式如下:

对比方程 (4),在我们的解耦模型中,D-A检测器将预测密集像素位置的类别分数,而不是预测图像标签分数。 因此,我们的模型仍然是分类图的空间信息,它更适合于语义分割任务。 每个图像的多标签分类损失表述如下:

其中y c是对应于第c类的二值图像标签。
在图4中我们展示了的扩展注意图和判别注意图的例子,其说明了扩展注意图在识别大对象区域方面表现良好,而区分性注意图在挖掘小的判别性部分时表现良好。 这两张关注地图显示了不同的和互补的特性。 因此,我们使用方程式(11) 合并了这两个注意图。

其中A c是第c类对应的归一化扩张注意图,S c是与第c类对应的归一化判别注意图。 T c是合并注意力映射的结果。 p^是图像分类得分p的softmax归一化结果。 这样的加权组合是直观的:小的预测分数通常对应于小尺寸的困难对象,因此应该将更多的权重放在挖掘判别区域的任务上。

图4 Expansive注意图和Discriminative注意图的例子。 扩展注意图和判别注意图具有不同的性质,适合于不同的情况。
C 伪注释生成
在本节中,我们将介绍如何根据注意力图生成伪注释。我们通过遵循[4],[6],[7]中使用的类似做法的简单阈值生成伪标注。给定一个带有图像标签集L(不包括背景)的图像的注意图,对于L中的每个类c,我们产生如下的前景区域:首先,我们在对应于类别c的注意映射上执行[0,1]范围内的最小 - 最大空间归一化。然后,我们将归一化注意图阈值设置为> 0.2。受到[33]的启发,我们在信道维上对特征图X进行求和,然后对其进行最小 - 最大空间归一化。然后,我们将这个归一化的映射阈值设置为<0.3来生成背景区域。由于区域是为每个类别独立生成的,因此在某些像素位置处可能存在标签冲突。根据文献[4]的实践,我们选择区域尺寸最小的前景标签作为冲突区域。我们将未分类像素的空白标签分配为空,表示标签在此位置不清楚,并且在训练过程中不予考虑。
生成的hard annotation M粗糙且区域不清晰。 我们可以在M上进一步应用denseCRF [34]来生成精炼的注释。 我们首先描述如何为每个空间位置生成类概率向量。对于图像I,存在于I中的标签被表示为C I。 目标数据集中的所有类别标签都表示为C。m i是像素i的M的掩码标签。 我们计算像素i处的类c∈C的类概率向量z i,c如下:

其中τ∈(0.5,1)是手动固定的参数。 | C I | 表示图像I中存在的标签的数量。
计算一元可能性作为概率向量?(The unary potential is calculated for the probability vector.)。我们将denseCRF [34]应用于一元可能性,并将结果掩码作为精炼的注释。
4 实验
A 实验设置
数据集和评估指标:我们在PASCAL VOC 2012图像分割基准[35]上评估我们的方法,该基准具有21个包括背景的语义类。原始数据集包含1464个训练图像(训练),1449个验证图像(val)和1456个测试图像(测试)。 按照常规做法,数据集由[36]增加到10582个训练图像。 在我们的实验中,我们只使用训练图像的图像级别类标签。 我们使用验证集图像来评估我们的方法。 至于分割性能的评估指标,我们使用标准的PASCAL VOC 2012分割度量:交并比(mIoU)。
训练/测试设置:我们训练所提出的解耦关注网络进行伪注释估计。 基于生成的伪注释,我们训练最先进的语义分割网络来预测最终的分割结果。
我们基于VGG-16模型构建了提出的解耦关注模型。我们将VGG-16中的层从第一层转移到层relu5_3作为输出X∈R 14×14×512的起始卷积层(如图3所示)。我们将15个图像的小批量大小和数据增强方法(如随机翻转和随机尺度比例)一起使用。我们将0.01设置为VGG-16转移层的初始学习速率,将0.1设置为关注检测器层的初始学习速率。10个echo后,我们将学习率降低了10倍。训练在20个echo后终止。
我们将[2]的DeepLab-LargeFOV(基于VGG-16)作为我们的分割模型进行训练。网络的输入图像作物原型为321×321,输出图像分割尺寸为41×41。初始基础学习率为0.001,在8个时期后降低10倍。训练在12个echo后终止。 我们使用Deeplab-largeFOV 1的公共可用pytorch实现。在分割的推理阶段,我们使用多尺度推理来结合不同尺度的输出得分,这是[3],[37]中的常见做法。最终的输出是由denseCRF后处理的[34]。
B 解耦注意模型的消融研究
C 与基于区域挖掘的方法进行比较
D 与当前最高水平进行比较
5 结论
6 致谢
参考文献
以上是关于2018年3月11日论文阅读的主要内容,如果未能解决你的问题,请参考以下文章
#论文阅读&CTG Fetal Hypoxia Detection Based on Deep Convolutional Neural Network with Transfer Learn