2018年5月5日论文阅读
Posted Ariel_一只猫的旅行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2018年5月5日论文阅读相关的知识,希望对你有一定的参考价值。
国外精读!title(27):We don’t need no bounding-boxes: Training object class detectors using only human verification(我们不需要任何边界框:只使用人工验证来训练对象类别检测器)---20170424
这篇文章主要设计了一个框架,输入是图片和image-level的类标签。目标就是:1、训练detector,能够自动predict出比较好的bounding box;2、减小人工标注bounding box的工作量。
文章的内容和目标检测有关。目标检测两个基本的模式包括:1)全监督:即需要提供所有物体的bounding box 2) 弱监督:只提供图片级别的标签,无bounding box 3) 半监督:介于两者之间。与这些模式不同,本文提出了一种全新的训练detector的方式: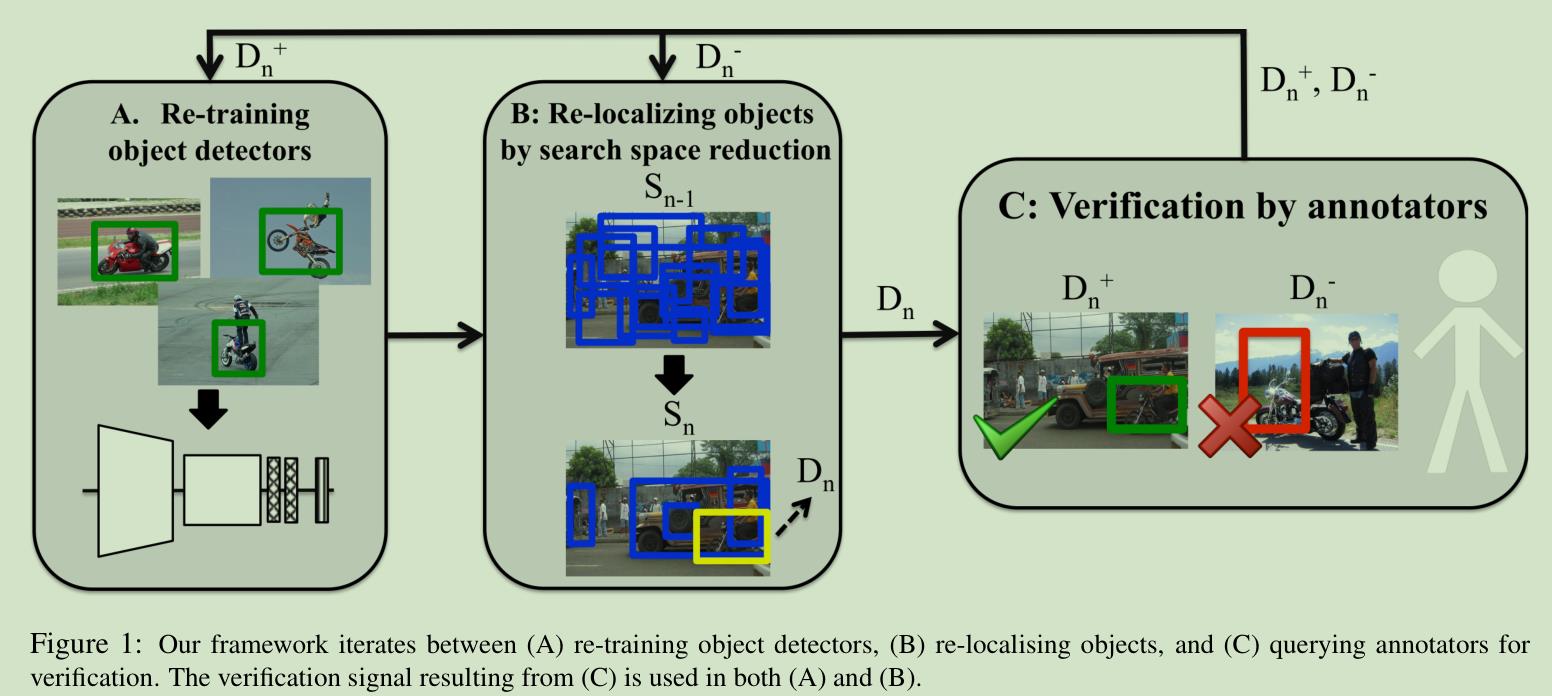
如上图所示,文章首先生成很多proposal出发,然后从一个传统的弱监督检测算法出发,训练出一个detector,每次将分数最高的输出交给标注者做验证,然后根据反馈 1) 重新训练detector 2) 去除掉明显不可能的proposal。作者在文章中提出了两种验证的方式:
-
标注者只回答Yes/No,即框是不是框住了一个特定的物体。
-
如果回答是No,标注者要提供更详细的信息:Part, Container, Mixed, Missed,分别对应以下四种情况:

如果采用后者的标注方式,则可以根据这些信息进一步筛选proposal,这里文章作者引入了本文最大的一个限制条件来达到这个目的:限制每张图每类物体只能有一个bounding box。如果加上这个条件,例如对于Part的标注,那么我们可以消除掉所有和这个bounding box不相交的框,从而快速缩小搜索的范围。
下面是一个两种标注方法比较的例子,可以看到额外的信息确实大幅提高了找到正确框的速度:

在最后的实验中,和全监督的方法比较,本文的方法以牺牲6%(51%->45%)的代价将标注时间缩短了6到9倍。不过由于是在VOC这样相对较小的数据集上进行的实验,我相信如果将数据规模加大,这个性能差距会更进一步减小。
综上所述,本文提供了一个全新的目标检测训练方式,将人工验证带入到整个训练流程中,通过active learning的办法,力求在人工标注的速度和准确性上取得了一个平衡。除了前面提到的本文的限制,文章使用的active learning的算法也比较初级,这些都制约了算法的最终性能。然而如果从这个文章拓展出去,我们可以发现有很多有意思的问题有待解决,例如:
-
对于类别数目很多的分类问题,我们怎么更为有效地转化为适合人类分类的二元分类问题加快数据标注?我们如何设计这样二元问题可以使每次标注得到的信息量最大?
-
对于目标检测问题,除了这种判断Yes/No的方式,是否有更多快速但是可以提供更多信息的标注方式?例如是否可以通过某种快速的点击提供更多的位置信息从而转化问题为一种全新的弱监督学习的问题?
-
在视频数据上,如何更有效地利用时序信息进行标注和训练?
很希望这些问题在不久的未来都会有圆满的解决,这些问题在这个数据为上的时代不管从理论还是实践上都有很大的意义 :)
以上是关于2018年5月5日论文阅读的主要内容,如果未能解决你的问题,请参考以下文章