HashMap原理剖析
Posted 知行合一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap原理剖析相关的知识,希望对你有一定的参考价值。
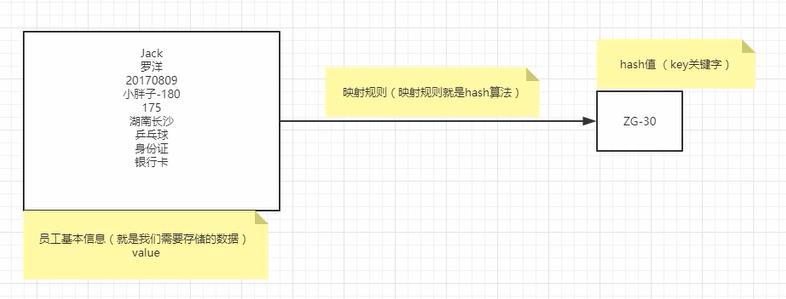
什么叫hash?
就是把一个不固定的长度的二进制值映射成一个固定长度的二进制值。
hash算法:就是对应的这个映射规则。
hash值:固定长度的二进制值。
什么叫hash表?HashMap底层的存储结构就是hashtable。
什么是hash算法?
1、除留余数法(应用于根据key找到hash表的index值)
key % table.length = index 得到的这个index数字就是对应的hashtable的索引
2、冲突解决(冲突hashtable中的元素index相同)
table.length = 10
对应的hash值key.hashCode() = 2
2 % 10 = 2
另一个key对应的hash值key.hashCode() = 12
12 % 10 = 2
那么,该如何解决?

解决hash冲突
01.冲突过程:key4占掉key3的位置(后进来的元素占掉先进来的)
02.那么key3去哪混?
key4中的next指针会指向key3的位置(Obejct key4_next = new Object(key3))
下面我们jdk源码的实现方式自定义一个简化版的HashMap,以便于加深理解。
1.定义MyMap接口
1 package cn.yzx.hashmap; 2 /** 3 * 自定义的Map接口 4 * @author Xuas 5 * 6 */ 7 public interface MyMap<K,V> { 8 9 public V put(K k,V v);//将k v属性包装成对象存储到hash表中 10 11 public V get(K k);//根据key获取value 12 13 public int size();//获取hash表的长度 14 15 /** 16 * 内部接口Entry<K,V> 17 * Entry对象就是存储到hash表中的数据对象 18 * hash表中每个元素存储的数据结构是一个Entry对象(包括key,value,next指针三个属性) 19 */ 20 public interface Entry<K,V> { 21 public K getKey();//获取key 22 public V getValue();//获取value 23 } 24 }
2.定义MyHashMap实现类
1 package cn.yzx.hashmap; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 6 public class MyHashMap<K,V> implements MyMap<K, V> { 7 8 /** 9 * hash表的默认长度 10 * jdk中的static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 11 */ 12 private static int defaultLength = 16; 13 14 /** 15 * 负载因子(阈值) 16 * 当表中元素数量超过 表容量 * 负载因子,那么表长度就需要扩容。(预警作用) 17 * static final float DEFAULT_LOAD_FACTOR = 0.75f; 18 */ 19 private static double defaultLoader = 0.75; 20 21 /** 22 * 表中存储元素的个数 23 */ 24 private int size = 0; 25 26 /** 27 * 存储数据的Entry[] 28 */ 29 private Entry<K,V>[] table = null; 30 31 /** 32 * 构造初始化属性值 33 * public HashMap(int initialCapacity, float loadFactor) {} 34 * @param length 35 * @param loader 36 */ 37 public MyHashMap(int length,double loader) { 38 defaultLength = length; 39 defaultLoader = loader; 40 table = new Entry[defaultLength]; 41 } 42 43 /** 44 * 无参构造使用默认值 45 */ 46 public MyHashMap() { 47 this(defaultLength, defaultLoader); 48 } 49 50 /** 51 * 需要把k,v存储到hash表中 52 */ 53 @Override 54 public V put(K k, V v) { 55 56 if(size >= defaultLength * defaultLoader) {//进行扩容 57 up2size(); 58 } 59 60 //01.获取表中索引 61 int index = getIndex(k); 62 //02.判断此index上是否存在数据 63 Entry<K,V> entry = table[index]; 64 if(null == entry) {//为空进行填充entry数据 65 table[index] = new Entry(k,v,null);//因entry==null,故next为null 66 size++; 67 }else {//此index上存在数据 68 table[index] = newEntry(k,v,entry);//新entry覆盖此位置上的原entry,并将新entry的next指针指向原entry 69 size++; 70 } 71 72 return table[index].getValue(); 73 } 74 75 /** 76 * 实例化Entry对象 77 * @param k 78 * @param v 79 * @return 80 */ 81 private Entry<K,V> newEntry(K k,V v,Entry<K,V> next) { 82 return new Entry(k,v,next); 83 } 84 85 /** 86 * 扩容:默认扩容是扩大一倍 87 * 疑问:扩容后原表中的元素在新表中的位置会变化吗? 88 * 一定会。因为表中索引index是通过hash算法得到的。即:除留余数法 key.hashCode() % table.length = index 89 * 这个table.length已经变化了!(再散列过程,重新散列分配位置 计算新的索引index) 90 */ 91 private void up2size() { 92 Entry<K,V>[] newTable = new Entry[defaultLength * 2]; 93 } 94 95 /** 96 * 再散列(重新分配位置) 97 * @param newTable 98 */ 99 private void againHash(Entry<K,V>[] newTable) { 100 //01.获取原表中的数据 101 List<Entry<K,V>> list = new ArrayList<Entry<K,V>>(); 102 103 for(int i=0 ; i<table.length; i++) { 104 if(null == table[i]) {//此判断目的:不一定hash表中所有的元素都有数据(index:i是hash算法计算出来的) 105 continue; 106 } 107 findEntryByNext(table[i], list); 108 } 109 110 if(list.size() > 0) { 111 //重新初始化hash表属性 112 size = 0; 113 defaultLength = defaultLength * 2; 114 table = newTable; 115 116 for(Entry<K,V> entry : list) { 117 if(null != entry.next) { 118 entry.next = null; //初始化next指针 119 } 120 put(entry.getKey(), entry.getValue());//将数据添加到扩容后的hash表中 121 } 122 } 123 } 124 125 /** 126 * 因为hash表是链表结构,所以通过next递归将原表中元素添加到List集合中,以便后续存入新表中 127 * @param entry 128 * @param list 129 */ 130 private void findEntryByNext(Entry<K,V> entry,List<Entry<K,V>> list) { 131 if(null != entry && null != entry.next) { 132 list.add(entry); 133 findEntryByNext(entry.next, list); 134 }else { 135 list.add(entry); 136 } 137 } 138 139 /** 140 * 根据key使用hash算法返回hash表的索引index 141 * 根据key的hash值对hash表长度取模。得到index索引就是表中的存储位置 142 * @param k 143 * @return 144 */ 145 private int getIndex(K k) { 146 int l = defaultLength; 147 148 int index = k.hashCode() % l; 149 return index >= 0 ? index : -index; 150 } 151 152 /** 153 * 根据key递归的去找key相等的value值 154 */ 155 @Override 156 public V get(K k) { 157 158 int index = getIndex(k);//获取索引 159 if(null == table[index]) { 160 return null; 161 } 162 return findValueByEqualKey(k, table[index]); 163 } 164 165 /** 166 * 表中两个元素是同一个索引(同一个索引index下存在不同的key) 167 * 所以我们需要拿到参数传进来的key和index下与之对应的key相同的那个元素的value 168 * 使用递归实现 169 * @param k 170 * @param entry 171 * @return 172 */ 173 private V findValueByEqualKey(K k,Entry<K,V> entry) { 174 if(k == entry.getKey() || k.equals(entry.getKey())) { 175 return entry.getValue(); 176 }else { 177 if(null != entry.next) { 178 return findValueByEqualKey(k, entry.next); 179 } 180 } 181 return null; 182 } 183 184 @Override 185 public int size() { 186 // TODO Auto-generated method stub 187 return 0; 188 } 189 190 /** 191 * 内部类实现Entry接口(因为Entry是接口无法实例化,此内部类目的是实例化Entry对象) 192 * static class Node<K,V> implements Map.Entry<K,V> {} 193 * @author Xuas 194 * 195 * @param <K> 196 * @param <V> 197 */ 198 class Entry<K,V> implements MyMap.Entry<K, V> { 199 200 K k; 201 202 V v; 203 204 Entry<K,V> next;//next指针,next是指向Entry对象的 205 206 public Entry(K k,V v,Entry<K,V> next) { 207 this.k = k; 208 this.v = v; 209 this.next = next; 210 } 211 212 @Override 213 public K getKey() { 214 return k; 215 } 216 217 @Override 218 public V getValue() { 219 return v; 220 } 221 222 } 223 224 }
3.测试
1 package cn.yzx.hashmap; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 6 public class Test { 7 public static void main(String[] args) { 8 // 测试jdk的HashMap 9 Map<String, String> jdkmap = new HashMap<String, String>(); 10 11 Long begin = System.currentTimeMillis(); 12 for (int i = 0; i < 1000; i++) { 13 jdkmap.put("key" + i, "value" + i); 14 } 15 16 for (int i = 0; i < 1000; i++) { 17 System.out.println(jdkmap.get("key" + i)); 18 } 19 Long end = System.currentTimeMillis(); 20 System.out.println("jdk\'time:" + (end - begin)); 21 22 System.out.println("*************************************************************"); 23 // 自定义的MyHashMap 24 MyMap<String, String> mymap = new MyHashMap<String, String>(); 25 26 Long begin2 = System.currentTimeMillis(); 27 for (int i = 0; i < 1000; i++) { 28 mymap.put("key" + i, "value" + i); 29 } 30 31 for (int i = 0; i < 1000; i++) { 32 System.out.println(mymap.get("key" + i)); 33 } 34 Long end2 = System.currentTimeMillis(); 35 System.out.println("jdk\'time:" + (end2 - begin2)); 36 37 } 38 }
这里本人对于性能的对比没做太深研究。
就酱~
以上是关于HashMap原理剖析的主要内容,如果未能解决你的问题,请参考以下文章