实现优先队列结构主要是通过堆完成,主要有:二叉堆、d堆、左式堆、斜堆、二项堆、斐波那契堆、pairing 堆等。
1. 二叉堆
1.1. 定义
完全二叉树,根最小。
存储时使用层序。

1.2. 操作
(1). insert(上滤)
插入末尾 26,不断向上比较,大于26则交换位置,小于则停止。

(2). deleteMin(下滤)
提取末尾元素,放在堆顶,不断下滤:

(3). 其他操作:
都是基于insert(上滤)与deleteMin(下滤)的操作。
减小元素:减小节点的值,上滤调整堆。
增大元素:增加节点的值,下滤调整堆。
删除非顶点节点:直接删除会出问题。方法:减小元素的值到无穷小,上滤后删除。
Merge:insert one by one
2. d叉堆
2.1. 定义
完全d叉树,根最小。
存储时使用层序。

2.2. 操作:
操作跟二叉堆基本一致:insert,deleteMin,增大元素,减小元素,删除非顶元素,merge。

2.3 二叉堆与d叉堆的对比:

3. 左式堆
3.1. 定义
零路径长度:到没有两个儿子的节点最短距离
左式堆:
1.一棵二叉树
2.零路径长:左儿子≧右儿子,父节点= min{儿子} +1(这条性质导致了左式堆的严重左偏)
零路径长度:
3.2. 操作:
(1) merge :
原则:根值大的堆与根值小的堆的右子堆合并(根值:根位置的元素值,并非零路径长度)
具体分三种情况(设堆H1的根值小于H2)
H1只有一个节点
H1根无右孩子
H1根有右孩子
(1.1).H1只有一个节点,若出现不满足:零路径长:左儿子≧右儿子,交换左右孩子。
(1.2).H1根无右孩子,若出现不满足:零路径长:左儿子≧右儿子,交换左右孩子。

(1.3).H1根有右孩子
1.初始状态,H1的根6,H2的根为8,将H2合并到H1。

2.将H1构造成根无右孩子的形式:

3.将元素10, merge到H2,要首先将H2构造成根无右孩子的形式,递归,merge,若出现不满足:零路径长:左儿子≧右儿子,交换左右孩子……
 ——》
——》 ——》
——》 ——》
——》
4.

5.

3.3. 性质分析:
insert:merge
deleteMin:delete root,merge
时间复杂度:merge与右路径长度之和成正比;最坏O(logN)
缺点:交换需判断;维护零路径长
4. 斜堆
4.1. 定义
二叉树,根最小。由此可见:
特点:merge无条件交换。
时间复杂度:最坏O(N);最好Ω(1);平均O(logN)
4.2性能比较:

定義
- 僅有一個節點的樹為斜堆;
- 兩個斜堆合併的結果仍為斜堆。
合併操作
斜堆合併操作的遞歸合併過程和左偏樹完全一樣。假設我們要合併
A 和 B兩個斜堆,且 A 的根節點比 B 的根節點小,我們只需要把 A 的根節點作為合併後新斜堆的根節點,並將 A 的右子樹與 B
合併。由於合併都是沿著最右路徑進行的,經過合併之後,新斜堆的最右路徑長度必然增加,這會影響下一次合併的效率。所以合併後,通過交換左右子樹,使整棵樹的最右路徑長度非常小(這是啟發規則)。然而斜堆不記錄節點的距離,在操作時,從下往上,沿著合併的路徑,在每個節點處都交換左右子樹。通過不斷交換左右子樹,斜堆把最右路徑甩向左邊了。
遞歸實現合併
- 比較兩個堆; 設p是具有更小的root的鍵值的堆,q是另一個堆,r是合併後的結果堆。
- 令r的root是p(具有最小root鍵值),r的右子樹為p的左子樹。
- 令r的左子樹為p的右子樹與q合併的結果。
舉例。合併前: 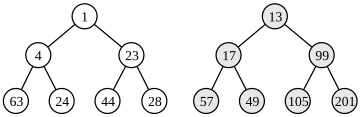
合併後 
非遞歸合併實現
- 把每個堆的每棵(遞歸意義下)最右子樹切下來。這使得得到的每棵樹的右子樹均為空。
- 按root的鍵值的升序排列這些樹。
- 迭代合併具有最大root鍵值的兩棵樹:
- 具有次大root鍵值的樹的右子樹必定為空。把其左子樹與右子樹交換。現在該樹的左子樹為空。
- 具有最大root鍵值的樹作為具有次大root鍵值樹的左子樹。
舉例:





5. 总结

如果是不支持所谓的合并操作union的话,普通的堆数据结构就是一种很理想的数据结构(堆排序)。 但是如果想要支持集合上的合并操作的话,最好是使用二项堆或者是斐波那契堆,普通的堆在union操作上最差的情况是O(n),但是二项堆和斐波那契堆是O(lgn)。
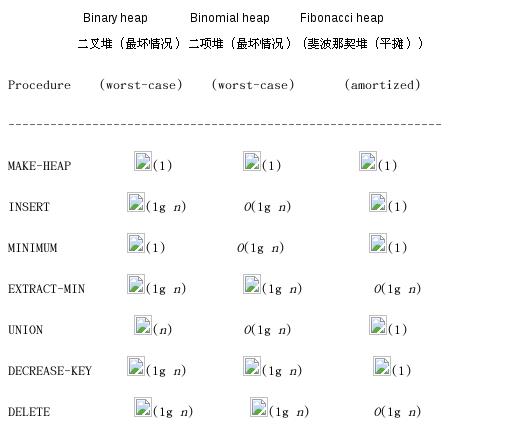
二叉堆简介
平时所说的堆,若没加任何修饰,一般就是指二叉堆。同二叉树一样,堆也有两个性质,即结构性和堆序性。正如AVL树一样,对堆的以此操作可能破坏者两个性质中的一个,因此,堆的操作必须要到堆的所有性质都被满足时才能终止。
结构性质
堆是一棵完全填满的二叉树,因为完全二叉树很有规律,所以它可以用一个数组表示而不需要指针。如下图所示,图2中的数组对应图1中的堆。


图1:二叉堆 图2:二叉堆的数组存储
对于任意位置i上的元素,其左儿子在位置2i处,右儿子在位置2i+1处,而它的父亲在i/2。因此,不仅指针这里不需要,而且遍历该树所需要的操作也十分简单。这种表示法的唯一问题在于:最大的堆大小需要事先估计,但对于典型的情况者并不成问题,图2中堆的大小是13个元素。该数组有一个位置0,用做哨兵,后面会有阐述。
因此,一个堆的数据结构将由一个数组,一个代表最大值的整数以及当前堆的大小组成。
堆序性质
使操作能快速执行的性质是堆序性。在一个堆中,对于每个节点X,X的父亲中的关键字小于(或等于)X中的关键字,根节点除外(根节点没有父亲)。图3中,左边的是堆,右边的不是(虚线表示堆序性质被破坏)。

图3:两棵完全二叉树
基本操作
Insert(插入):
为了将一个元素X插入到堆中,我们在下一个空闲位置创建一个空穴,否则该堆将不是完全树。如果X可以放入到该空穴中,那么插入完成。否则,我们把空穴的父节点上的元素移入该空穴中,这样,空穴就朝着根的方向上行一步。继续该过程直到X能被放入到空穴中为止。图4表示,为了插入14,我们在堆的下一个可用位置建立一个空穴,由于将14插入空穴破坏了堆序性质,因此将31移入该空穴,图5继续这种策略,直到找到14的正确位置。


图4:创建一个空穴,再将空穴上冒 图5:将14插入到前面的堆中的其余两步
这种策略叫做上虑。新元素在堆中上虑直到找出正确的位置;使用如下代码,很容易实现。
如果要插入的元素师新的最小值,那么它将一直被推向顶端,这样在某一时刻,i将是1,我们就需要令程序跳出while循环。当然可以通过明确的测试做到这一点。不过,这里采用的是把一个很小的值放到位置0处以使while循环终止,这个值必须小于堆中的任何值,称之为标记或哨兵。这类似于链表中头结点的使用。通过添加的这个标记,避免了每次循环都要执行一次测试,这是简单的空间换时间策略。
DeleteMin(删除最小元):
找出最小元是很容易的;困难的部分是删除它。当删除一个最小元时,在根节点处产生了一个空穴。由于现在堆少了一个元素,因此对中最后一个元素X必须移到该堆的某个地方。如果X可以被放入空穴中,那么DeleteMin完成。不过这一般都不可能,因此我们将空穴的两个儿子中较小者移入空穴中,这样就把空穴向下推了一层,重复该步骤,知道X可以被放入空穴中。因此,我们的做法是将X置入沿着从根开始包含最小儿子的一条路径上的一个正确的位置。
图6显示DeleteMin之前的堆,删除13之后,我们必须要正确的将31放到堆中,31不能放在空穴中,因为这将破坏堆序性质,于是,我们把较小的儿子14置入空穴,同时空穴向下滑一层,重复该过程,把19置入空穴,在更下一层上建立一个新的空穴,然后26置入空穴,在底层又建立一个新的空穴,最后,我们得以将31置入空穴中。这种策略叫做下虑。

图6 在根处建立空穴 图7:将空穴下滑一层

图8:空穴移到底层,插入31
BinHeap.h
typedef int ElementType;
#ifndef _BinHeap_H
#define MinPQSize 10
#define MinData -32767
struct HeapStruct;
typedef struct HeapStruct *PriorityQueue;
PriorityQueue Initialize(int MaxElements);
void Destroy(PriorityQueue H);
void MakeEmpty(PriorityQueue H);
void Insert(ElementType X,PriorityQueue H);
ElementType DleteMin(PriorityQueue H);
ElementType FindMin(PriorityQueue H);
int IsEmpty(PriorityQueue H);
int IsFull(PriorityQueue H);
#endif
BinHeap.c

#include"BinHeap.h"
#include"fatal.h"
struct HeapStruct
{
int Capacity;
int Size;
ElementType *Elements;
};
PriorityQueue Initialize(int MaxElements)
{
PriorityQueue H;
if(MaxElements<MinPQSize)
Error("Priority queue size is too small");
H=malloc(sizeof(struct HeapStruct));
H->Elements=malloc((MaxElements+1)*sizeof(ElementType));
if(H->Elements==NULL)
FatalError("Out of space!!!");
H->Capacity=MaxElements;
H->Size=0;
H->Elements[0]=MinData;
return H;
}
void MakeEmpty(PriorityQueue H)
{
H->Size=0;
}
void Insert(ElementType X,PriorityQueue H)
{
int i;
if(IsFull(H))
{
Error("Priority queue is full");
}
for(i=++H->Size;X<H->Elements[i/2];i=i/2)
{
H->Elements[i]=H->Elements[i/2];
}
H->Elements[i]=X;
}
ElementType DeleteMin(PriorityQueue H)
{
int i,Child;
ElementType MinElement,LastElement;
if(IsEmpty(H))
{
Error("Priority queue is empty");
return H->Elements[0];
}
MinElement=H->Elements[1];
LastElement=H->Elements[H->Size--];
for(i=1;i<H->Size;i=Child)
{
Child=2*i;
if(Child!=H->Size&&H->Elements[Child]>H->Elements[Child+1])
Child++;
if(LastElement>H->Elements[Child])
H->Elements[i]=H->Elements[Child];
else
break;
}
H->Elements[i]=LastElement;
return MinElement;
}
ElementType FindMin(PriorityQueue H)
{
return H->Elements[1];
}
int IsEmpty(PriorityQueue H)
{
return H->Size==0;
}
int IsFull(PriorityQueue H)
{
return H->Capacity==H->Size;
}
void Destroy(PriorityQueue H)
{
free(H->Elements);
free(H);
}
UseBinHeap.c
#include <stdio.h>
#include <stdlib.h>
#include"BinHeap.h"
int main()
{
int i;
PriorityQueue H=Initialize(MinPQSize);
MakeEmpty(H);
for(i=0;i<MinPQSize;i++)
{
Insert(i,H);
}
printf("Hello world!\\n");
return 0;
}
d-堆
二叉堆因为实现简单,因此在需要优先队列的时候几乎总是使用二叉堆。d-堆是二叉堆的简单推广,它恰像一个二叉堆,只是所有的节点都有d个儿子(因此,二叉堆又叫2-堆)。下图表示的是一个3-堆。注意,d-堆要比二叉堆浅得多,它将Insert操作的运行时间改进为 。然而,对于大的d,DeleteMin操作费时得多,因为虽然树浅了,但是d个儿子中的最小者是必须找到的,如果使用标准算法,将使用d-1次比较,于是将此操作的时间提高到
。然而,对于大的d,DeleteMin操作费时得多,因为虽然树浅了,但是d个儿子中的最小者是必须找到的,如果使用标准算法,将使用d-1次比较,于是将此操作的时间提高到 。如果d是常数,那么当然两种操作的运行时间都为 O(logN)。虽然仍可以使用一个数组,但是,现在找出儿子和父亲的乘法和除法都有个因子d,除非d是2的幂,否则会大大增加运行时间,因为我们不能再通过二进制移位来实现除法和乘法了。D-堆在理论上很有趣,因为存在许多算法,其插入次数比删除次数多得多,而且,当优先队列太大不能完全装入内存的时候,d-堆也是很有用的,在这种情况下,d-堆能够以与B-树大致相同的方式发挥作用。
。如果d是常数,那么当然两种操作的运行时间都为 O(logN)。虽然仍可以使用一个数组,但是,现在找出儿子和父亲的乘法和除法都有个因子d,除非d是2的幂,否则会大大增加运行时间,因为我们不能再通过二进制移位来实现除法和乘法了。D-堆在理论上很有趣,因为存在许多算法,其插入次数比删除次数多得多,而且,当优先队列太大不能完全装入内存的时候,d-堆也是很有用的,在这种情况下,d-堆能够以与B-树大致相同的方式发挥作用。
除了不能执行Find操作外(指以对数执行),堆的实现最明显的两个缺点是:将两个堆合并成一个堆是很困难的。这种附加的操作叫做Merge。存在许多实现堆的方法使得Merge操作的运行时间为O(logN),如下篇介绍的左式堆。

简介
设计一种堆结构像二叉堆那样高效的支持合并操作而且只使用一个数组似乎很困难。原因在于,合并似乎需要把一个数组拷贝到另一个数组中去,对于相同大小的堆,这将花费O(N)。正因为如此,所有支持高效合并的高级数据结构都需要使用指针。
像二叉堆那样,左式堆也有结构性和堆序性。不仅如此,左式堆也是二叉树,它和二叉堆之间的唯一区别在于:左式堆不是理想平衡的,而实际上是趋向于非常不平衡。
左式堆性质
把任意节点X的零路径长(null path length, NPL)Npl(X)定义为从X到一个没有两个儿子的节点的最短路径长。因此,具有0个或1个儿子的节点的Npl值为0,而Npl(NULL)=-1。注意,任意节点的零路径长比它的各个儿子节点的最小值多1。
左式堆的性质是:对于堆中的每一个节点X,左儿子的零路径长至少与右儿子的零路径长一样大。因此,下图1中,左边的二叉树是左式堆,而右边的二叉树则不是。这个性质使左式堆明显更偏重于使树向左增加深度,左式堆的名称也由此而来。

图1:两棵树的零路径长,只有左边的树是左式堆
左式堆操作
左式堆的基本操作是合并(Merge),注意,插入只是合并的特殊情形。因为可以把插入看成是单节点堆与一个大的堆的Merge。对于合并操作,主要采取的是递归解法。如图2所示,两个左式堆H1,H2,注意,最小元在根处。除数据,左指针,右指针外,每个单元还需要有一个指示零路径长的项。

图2:两个左式堆H1,H2
如果这两个堆有一个是空的,那么可以直接返回。否则,为了合并两个堆,需要比较它们的根。首先,将具有大的根值的堆与具有较小的根值的堆的右子树堆合并。在本例中,我们递归的将H2与H1在8处的右子树堆合并,得到如图3中的堆。

图3:将H2与H1的右子树堆合并的结果
如果直接将图3中的堆作为H1的右儿子,如图4所示,那么新的H1虽然满足堆序性质,但是它不是左式堆,因为左子树的零路径长为1,而根的右儿子的零路径长为2.因此,左式堆的性质在根处被破坏。不过,很容易看到,树的其余部分必然是左式堆,由于递归步骤,根的右子树也是左式堆。根的左子树没发生变化,必然也是左式堆。这样一来,只需要对根进行调整就可以了。使整个树是左式堆的做法如下:只要交换根的左儿子和右儿子,并更新零路径长,就完成了Merge。如图5所示:

图4:H1接上图3中的左式堆作为右儿子的结果

图5:交换H1的根的儿子得到的结果
上面提到,我们可以通过把被插入项看成单节点并执行一次Merge来完成插入。为了执行DeleteMin,只要除掉根而得到两个堆,然后再将这两个堆合并。因此执行一次DeleteMin操作的时间为O(logN)。
代码实现
LeafHeap.h
typedef int ElementType;
#ifndef _LeafHeap_H
struct TreeNode;
typedef struct TreeNode *PriorityQueue;
PriorityQueue Initialize(void);
ElementType FindMin(PriorityQueue H);
int IsEmpty(PriorityQueue H);
PriorityQueue Merge(PriorityQueue H1,PriorityQueue H2);
#define Insert(X,H) (H=Insert1((X),H))
PriorityQueue Insert1(ElementType X,PriorityQueue H);
PriorityQueue DeleteMin(PriorityQueue H);
#endif
struct TreeNode
{
ElementType Element;
PriorityQueue left;
PriorityQueue right;
int Np1;
};
LeftHeap.c
#include "LeftHeap.h"
#include "fatal.h"
PriorityQueue Initialize(void)
{
PriorityQueue H=malloc(sizeof(struct TreeNode));
H->left=H->right=NULL;
H->Np1=-1;
H->Element=0;
return H;
}
ElementType FindMin(PriorityQueue H)
{
if(IsEmpty(H))
return -1;
return H->Element;
}
int IsEmpty(PriorityQueue H)
{
return H==NULL;
}
static void SwapChildren(PriorityQueue H)
{
PriorityQueue temp;
temp=H->left;
H->left=H->right;
H->right=temp;
}
static PriorityQueue Merge1(PriorityQueue H1, PriorityQueue H2)
{
if(H1->left==NULL)
H1->left=H2;
else
{
H1->right=Merge(H1->right,H2);
if(H1->left->Np1<H1->right->Np1)
SwapChildren(H1);
H1->Np1=H1->right->Np1+1;
}
return H1;
}
PriorityQueue Merge(PriorityQueue H1, PriorityQueue H2)
{
if(H1==NULL)
return H2;
else if(H2==NULL)
return H1;
if(H1->Element<H2->Element)
return Merge1(H1,H2);
else
return Merge1(H2,H1);
}
PriorityQueue Insert1(ElementType X, PriorityQueue H)
{
PriorityQueue SingleNode;
SingleNode=malloc(sizeof(struct TreeNode));
if(SingleNode==NULL)
FatalError("Out of space!!!");
else
{
SingleNode->left=SingleNode->right=NULL;
SingleNode->Np1=0;
SingleNode->Element=X;
H=Merge(SingleNode,H);
}
return H;
}
PriorityQueue DeleteMin(PriorityQueue H)
{
PriorityQueue LeftHeap,RightHeap;
if(IsEmpty(H))
{
Error("Priority queue is empty");
return H;
}
LeftHeap=H->left;
RightHeap=H->right;
free(H);
return Merge(LeftHeap,RightHeap);
}
UseLeftHeap.c
#include"LeftHeap.h"
#include<stdio.h>
int main()
{
int i;
PriorityQueue H;
H=Initialize();
for(i=0;i<10;i++)
H=Insert1(i,H);
for(i=0;i<10;i++)
{
printf("Element : %d ",H[i].Element);
}
return 0;
}
虽然左式堆每次操作花费O(logN),这有效的支持了合并,插入和DeleteMin,但还是有改进的余地,因为我们知道,二叉堆以每次操作花费常数平均时间支持插入。二项队列支持所有这种操作,每次操作的最坏情形运行时间为O(logN),而插入操作平均花费常数时间。
二项队列结构
二项队列不同于左式堆和二叉堆等优先队列的实现之处在于,一个二项队列不是一棵堆序的树,而是堆序树的集合,即森林。堆序树中的每棵树都是由约束形式的,叫做二项树。每一个高度上至多存在一棵二项树。高度为0的二项树是一颗单节点树,高度为k的二项树Bk通过将一棵二项树Bk-1附接到另一颗二项树Bk-1的根上而构成。图1显示二项树B0,B1,B2,B3以及B4。

图1:高度为0,1,2,3,4的五棵二项树
从图中可以看出,二项树Bk由一个带有儿子B0,B1,B2,……Bk-1 的根组成。高度为k的二项树恰好有2^k个节点。如果我们把堆序施加到二项树上并允许任意高度上最多有一棵二项树,那么我们便能够用二项树的集合惟一的表示任意大小的优先队列。例如,大小为13的优先队列可以用森林B3,B2,B0表示,可以把这种表示写成1101,它不仅以二进制表示了13,而且说明了B3,B2,B0出现,而B1没出现。
二项队列操作
此时,因为二项队列也满足了堆序性,故最小元可以通过搜索所有的树根来找出,由于最多有logN棵不同的树,因此最小元可以在O(logN)中找到。
合并操作基本上是通过将两个队列加到一起来完成的。令H1,H2是两个二项队列,H3是新的二项队列。由于H1没有高度为0的二项树而H2有,因此就用H2中高度为0的二项树作为H3的一部分。因为H1,H2都有高度为1的二项树,将它们合并,让大的根成为小的根的子树,从而建立高度为2的二项树,见图3所示。这样,H3将没有高度为1的二项树。先存在3棵高度为2的二项树,即H1,H2原有的两棵树及由上一步合并得到的一棵二项树。我们将一棵高度为2的二项树放入到H3中,并合并其他两个二项树,得到一棵高度为3的二项树。由于H1,H2都没有高度为3的二项树,因此该二项树就成为H3的一部分,合并结束,见图4所示:


图2:两个二项队列H1,H2 图3:H1和H2中两棵B1树合并

图3:最终结果
插入实际上就是合并的特殊情形,我们只要创建一棵单节点的树并执行一次合并,这种操作的最坏情形运行时间也是O(logN)。更准确的说,如果元素将要插入的那个优先队列不存在的最小的二项树是Bi,那么运行时间与i+1成正比。图4和图5演示通过依序插入1到7来构成一个二项队列。

在1插入之后 在2插入之后 在3插入之后 在4插入之后

在5插入之后 在6插入之后 在7插入之后
DeleteMin可以通过首先找出一棵具有最小根的二项树来完成,令该树为Bk,并令原有的优先队列为H,我们从H的树的森林中除去二项树Bk,形成新的二项队列H1。再出去Bk的根,得到一些二项树B0,B1,B2,….Bk-1,它们共同形成了优先队列H2,合并H1,H2,操作结束。
图6,图7和图8演示了对H3执行一次DeleteMin。

图6:二项队列H3,最小元为12


图7:二项队列H‘,包含除B3外H3中所有的二项树 图8:二项队列H\'\',除去12之后的B3

图9:DeleteMin(H3)的结果
二项队列实现
DeleteMin操作需要快四找出根的所有子树的能力,因此,需要一般树的标准表示方法:每个节点的儿子都在一个链表中,每个节点都有一个指向它的第一个儿子的指针。该操作还要求,诸儿子按照他们的子树大小排序。当两棵树被合并时,其中的一棵树最为儿子被加到另一棵树上。由于这棵新树将是最大的子树,因此,以大小递减的方式保持这些子树很有意义。
总之,二项树的每一个节点将包括:数据,指向第一个儿子的指针以及右兄弟。二项树中的诸儿子以递减次序排序。
图10解释如何表示H3中的二项队列。

图10 二项队列H3的表示方式
为了合并两个二项队列,我们需要一个例程来合并两个大小相同的二项树。图11指出两个大小相同的二项树合并时指针是如何变化的:

图11: 合并两颗二项树
详细代码:
binheap.h
typedef long ElementType;
#define Infinity (30000L)
#ifndef _BinHeap_H
#define _BinHeap_H
#define MaxTrees (14) //二项队列中的二项树高度最大为13
#define Capacity (16383) //高度0,1,2,3,...13的二项树节点数目之和
struct BinNode;
typedef struct BinNode *BinTree;
struct Collection;
typedef struct Collection *BinQueue;
typedef BinTree Position;
BinQueue Initialize(void);
void Destroy(BinQueue H);
BinQueue MakeEmpty(BinQueue H);
BinQueue Insert(ElementType X,BinQueue H);
ElementType DeleteMin(BinQueue H);
BinTree CombineTrees(BinTree T1,BinTree T2);
BinQueue Merge(BinQueue H1,BinQueue H2);
ElementType FindMin(BinQueue H);
int IsEmpty(BinQueue H);
int IsFull(BinQueue H);
#endif // _BinHeap_H
//一个树的节点结构组成
struct BinNode
{
ElementType Element;
Position LeftChild;
Position NextSibling;
};
struct Collection
{
int CurrentSize; //所有树中的节点个数
Position TheTrees[MaxTrees]; //指向每棵树的指针数组,其中每个元素指向一棵树
};
binheap.c
#include"binheap.h"
#include"fatal.h"
#include<stdio.h>
BinQueue Initialize(void)
{
BinQueue H;
int i=0;
H=malloc(sizeof(struct Collection));
if(H==NULL)
{
FatalError("Out of space!");
}
H->CurrentSize=0;
for(i=0;i<MaxTrees;i++)
H->TheTrees[i]=NULL;
return H;
}
static void DestroyTree(BinTree T)
{
if(T!=NULL)
{
DestroyTree(T->LeftChild);
DestroyTree(T->NextSibling);
free(T);
}
}
void Destroy(BinQueue H)
{
int i=0;
for(i=0;i<MaxTrees;i++)
DestroyTree(H->TheTrees[i]);
}
BinQueue MakeEmpty(BinQueue H)
{
int i=0;
Destroy(H);
for(i=0;i<MaxTrees;i++)
{
H->TheTrees[i]=NULL;
}
H->CurrentSize=0;
return H;
}
//创建一个有单个节点二项树的二项队列,与H的单个节点的二项树树进行合并
BinQueue Insert(ElementType X,BinQueue H)
{
BinTree NewNode;
BinQueue OneItem;
NewNode=malloc(sizeof(struct BinNode));
if(NewNode==NULL)
FatalError("out of space!");
NewNode->LeftChild=NewNode->NextSibling=NULL;
NewNode->Element=X;
OneItem=Initialize();
OneItem->CurrentSize=1;
OneItem->TheTrees[0]=NewNode;
return Merge(H,OneItem);
}
ElementType FindMin(BinQueue H)
{
int i=0;
ElementType MinItem=Infinity;
if(IsEmpty(H))
Error("empty");
for(i=0;i<MaxTrees;i++)
{
if(H->TheTrees[i]&&H->TheTrees[i]->Element<MinItem)
MinItem=H->TheTrees[i]->Element;
}
return MinItem;
}
int IsEmpty(BinQueue H)
{
return H->CurrentSize==0;
}
int IsFull(BinQueue H)
{
return H->CurrentSize==Capacity;
}
BinTree CombineTrees(BinTree T1, BinTree T2)
{
if(T1->Element>T2->Element)
return CombineTrees(T2,T1);
T2->NextSibling=T1->LeftChild;
T1->LeftChild=T2;
return T1;
}
BinQueue Merge(BinQueue H1, BinQueue H2)
{
BinTree T1,T2,Carry=NULL;
int i=0,j=0;
//首先判断合并是否会超出二项队列限制的大小
if(H1->CurrentSize+H2->CurrentSize>Capacity)
{
FatalError("Out of space!!");
}
H1->CurrentSize+=H2以上是关于优先队列的实现的主要内容,如果未能解决你的问题,请参考以下文章
线性表--08---优先队列
优先队列实现dijkstra算法C++代码
基于最大堆实现最大优先队列代码
优先队列代码实现
优先队列的实现(最小堆)
利用Vector实现优先级队列










