网站爬取-案例二:天猫爬取( 第一卷:首页数据抓取)
Posted 我爱在伊甸园吃苹果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网站爬取-案例二:天猫爬取( 第一卷:首页数据抓取)相关的知识,希望对你有一定的参考价值。
说到网站数据的爬取,目前为止我见过最复杂的就是天猫了,现在我想对它进行整站的爬取
我们先来看下天猫主页的界面
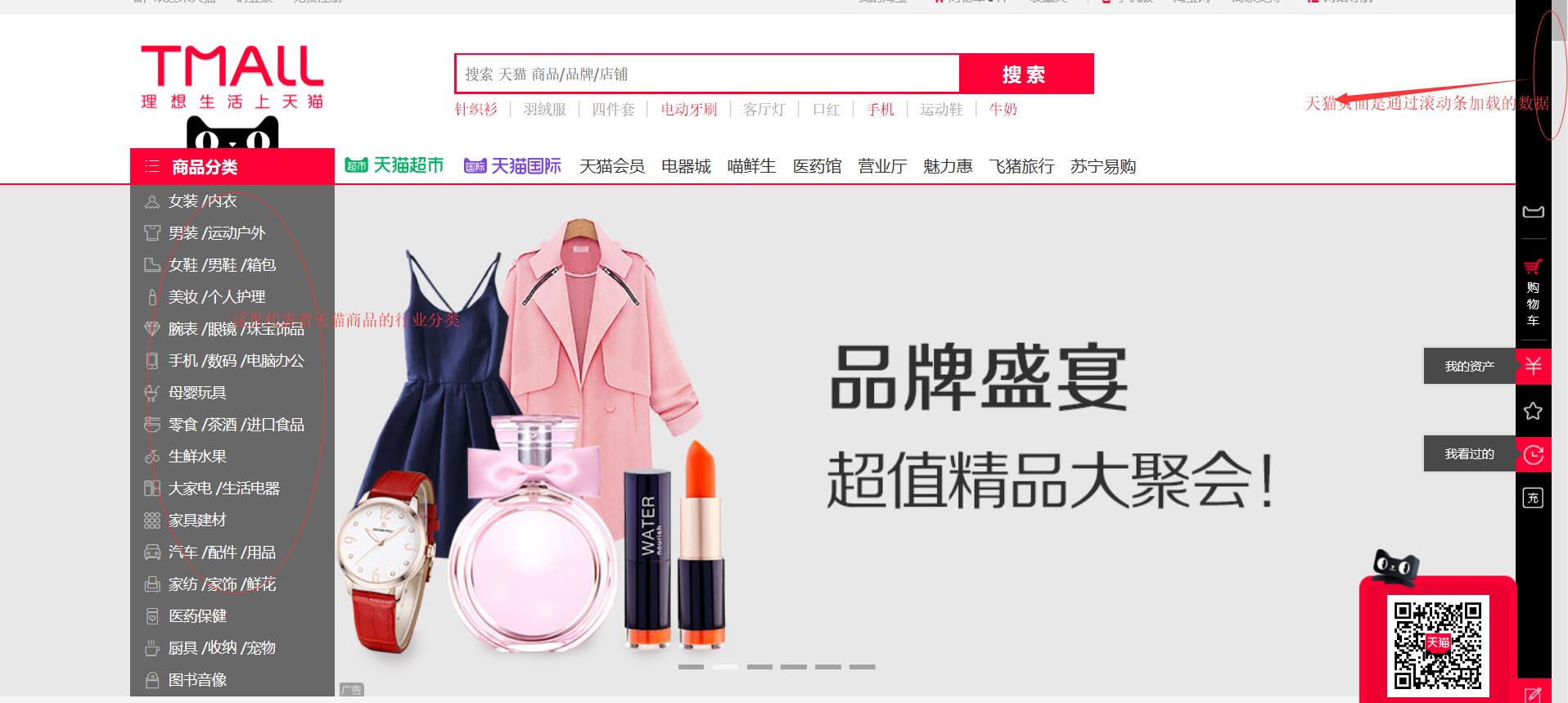
天猫页面很明显是动态页面 所以我们需要用selenium模块
首先我们抓取下行业列表,留作之后的深度爬取

我们来看下结果:

看到商品链接和行业列表的完美展现了吧
可是当前页面并没抓取完毕,我们现在看下首页还有什么内容

我们顺带抓取下发先并没有我们想要的东西,说明页面没有抓取完毕,熟悉网站制作的同僚们因该知道这样的页面都是用OVERFLOW:hidden的方式来做的布局,所以我们可以利用JS的SCOLLER事件来进行动态加载获取当前整个页面的源码
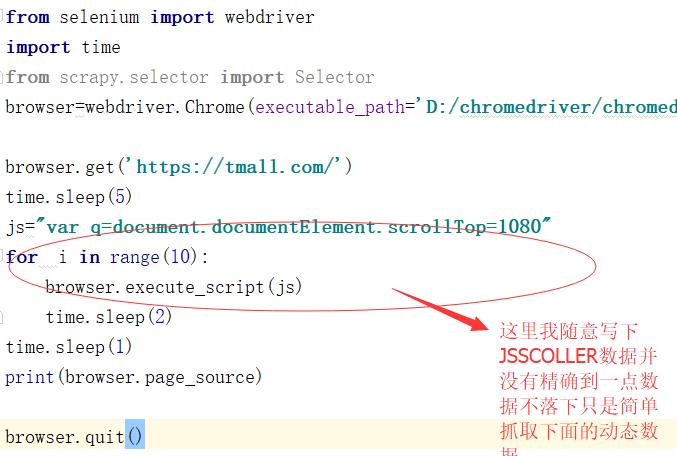 我们把打印的源码拿下来分析下抓取优惠卷的价格和提供商品的价格
我们把打印的源码拿下来分析下抓取优惠卷的价格和提供商品的价格
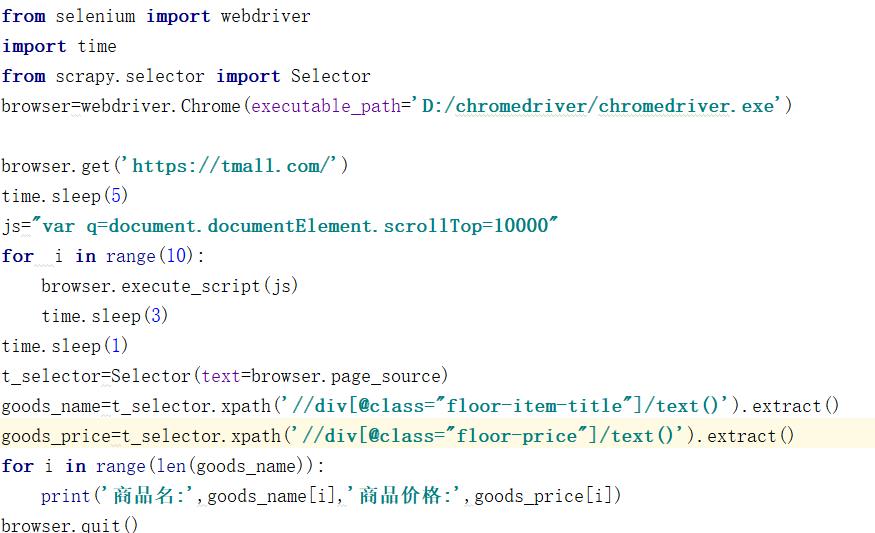
由于我的网络和设置的数值过大所以数据加载的不完整:
看下结果:

好好调整一下 就可以获取所有数据
以上是关于网站爬取-案例二:天猫爬取( 第一卷:首页数据抓取)的主要内容,如果未能解决你的问题,请参考以下文章