网站爬取-案例一:猫眼电影TOP100
Posted 我爱在伊甸园吃苹果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网站爬取-案例一:猫眼电影TOP100相关的知识,希望对你有一定的参考价值。
今天有小朋友说想看一下猫眼TOP100的爬取数据,要TOP100的名单,让我给发过去,其实很简单,先来看下目标网站:
建议大家都用谷歌浏览器:

这是我们要抓取的内容,100个数据,很少
我们看一下页面结构
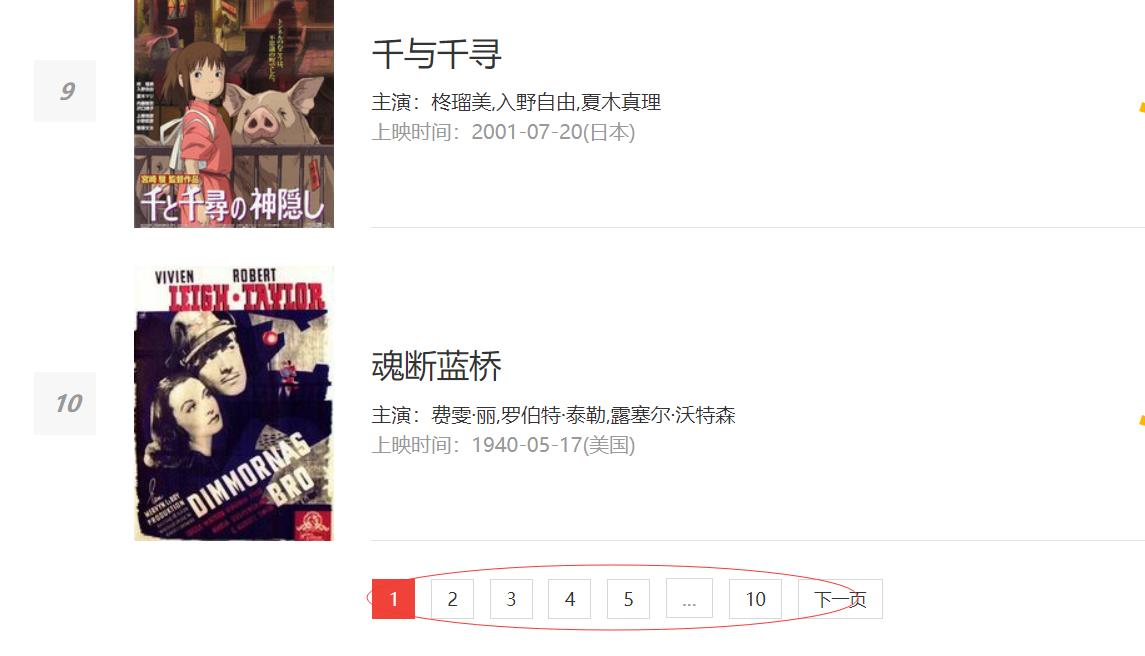 100部电影分十个页码,也就是一页10个电影,抓取方式为10页循环抓取
100部电影分十个页码,也就是一页10个电影,抓取方式为10页循环抓取
先看下代码:
引入模块:
 这次我用REQUEST模块作为抓取工具,以JSON的形式做成文件存储方式
这次我用REQUEST模块作为抓取工具,以JSON的形式做成文件存储方式
第一步:请求网页并且读取:
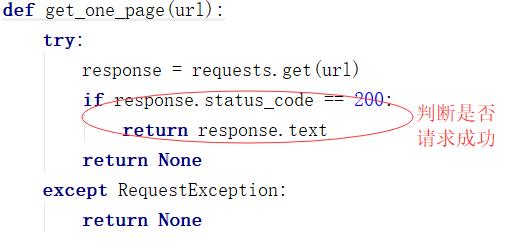 这个网站并没有设立反爬虫手段
这个网站并没有设立反爬虫手段
第二步:解析网页函数:
 我这里用的正则表达式
我这里用的正则表达式
第三步:定义存储函数:’

第四部:主函数:
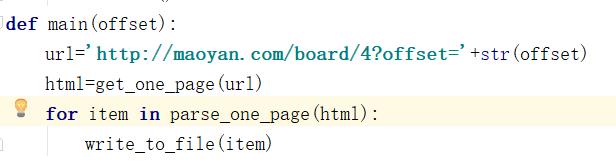 请注意主函数里的参数
请注意主函数里的参数
第5步:执行爬取

看下结果:

这个真的很简单
以上是关于网站爬取-案例一:猫眼电影TOP100的主要内容,如果未能解决你的问题,请参考以下文章