图像语义分割的前世今生
Posted Ariel_一只猫的旅行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像语义分割的前世今生相关的知识,希望对你有一定的参考价值。
1998年以来,人工神经网络识别技术已经引起了广泛的关注,并且应用于图像分割。基于神经网络的分割方法的基本思想是通过训练多层感知机来得到线性决策函数,然后用决策函数对像素进行分类来达到分割的目的。这种方法需要大量的训练数据。神经网络存在巨量的连接,容易引入空间信息,能较好地解决图像中的噪声和不均匀问题。选择何种网络结构是这种方法要解决的主要问题。
-
普通分割
将不同分属不同物体的像素区域分开。
如前景与后景分割开,狗的区域与猫的区域与背景分割开。 -
语义分割
在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体)。
如把画面中的所有物体都指出它们各自的类别。 -
实例分割
在语义分割的基础上,给每个物体编号。
如这个是该画面中的狗A,那个是画面中的狗B。
这里先说一下图像语义分割和普通的图像分割的关系:
我们先看一下对传统图像分割的定义:所谓图像分割是指根据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出明显的不同。简单的说就是在一副图像中,把目标从背景中分离出来。
关于传统图像分割,想系统了解更多的,请参考:https://www.cnblogs.com/ariel-dreamland/p/9428434.html
普通的图像分割,通常意味着传统语义分割,这个时期的图像分割(大概2010年前),由于计算机计算能力有限,早期只能处理一些灰度图,后来才能处理rgb图,这个时期的分割主要是通过提取图片的低级特征,然后进行分割,涌现了一些方法:Ostu、FCM、分水岭、N-Cut等。这个阶段一般是非监督学习,分割出来的结果并没有语义的标注,换句话说,分割出来的东西并不知道是什么。
随后,随着计算能力的提高,人们开始考虑获得图像的语义分割,这里的语义目前是低级语义,主要指分割出来的物体的类别,这个阶段(大概是2010年到2015年)人们考虑使用机器学习的方法进行图像语义分割。
随着FCN的出现,深度学习正式进入图像语义分割领域,这里的语义仍主要指分割出来的物体的类别,从分割结果可以清楚的知道分割出来的是什么物体,比如猫、狗等等。
现在还有一种叫instance segmentation, 可以对同一类别的不同物体进行不同的划分,可以清楚地知道分割出来的左边和右边的两个人不是同一个人。
图像语义分割是 AI 领域中一个重要的分支,是机器视觉技术中关于图像理解的重要一环。近年的自动驾驶技术中,也需要用到这种技术。车载摄像头探查到图像,后台计算机可以自动将图像分割归类,以避让行人和车辆等障碍。图像语义分割的意思就是机器自动分割并识别出图像中的内容比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示 back ground)。

所以图像分割对图像理解的意义,就好比读古书首先要断句一样。
在 Deeplearning 技术快速发展之前,就已经有了很多做图像分割的技术,其中比较著名的是一种叫做 “Normalized cut” 的图划分方法,简称 “N-cut”。N-cut 的计算有一些连接权重的公式,这里就不提了,它的思想主要是通过像素和像素之间的关系权重来综合考虑,根据给出的阈值,将图像一分为二。
下图是将像素间的关系信息简单描述成为距离,根据距离差距来划分图像的示例:
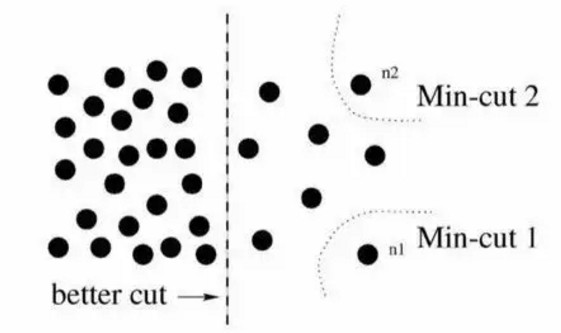
在实际运用中,每运行一次 N-cut,只能切割一次图片,为了分割出图像上的多个物体,需要多次运行,下图示例了对原图 a 进行 7 次 N-cut 后,每次分割出的结果。

但是可以很明显的看到这种简单粗暴的分割方式并不准确,趴在地上的运动员肢体在 b 图中分割出来,而他的手臂则在 h 图中被分割,显然是错误的。
N-cut 技术的缺陷很明显,于是有了一种更新的优化方式,这种优化方式为了避免机器不能很好的分割类似上面例子中 “衣服和肢体颜色反查太大导致分割错误” 的情况,增加了人机交互,在分割过程中,需要人工干预参与完成。这种需要人机交互的技术叫 Grab Cut。
这种技术其实是这样的,给定一张图片,然后人工在想要抠图(也就是我们说的分割)的区域画一个红框,然后机器会对略小于这个框的内容进行 “主体计算”,嗯,这个 “主体计算” 是我起的名字,为了你们更好的理解背后复杂的设计和公式,因为机器会默认红框中部是用户期望得到的结果,所以将中部作为主体参考,然后剔除和主体差异较大的部分,留下结果。

此技术中,抠出来的部分叫 “前景”,剔除的部分叫 “背景”。有时候还挺好用的,但是稍微复杂一点的时候问题就来了:比如要抠下面这个戴头盔的大兵,头盔颜色和背后岩石颜色很相近,结果机器就会把头盔部分剔除,同样脖子附近的山岩也被当做了前景而保留了进来。
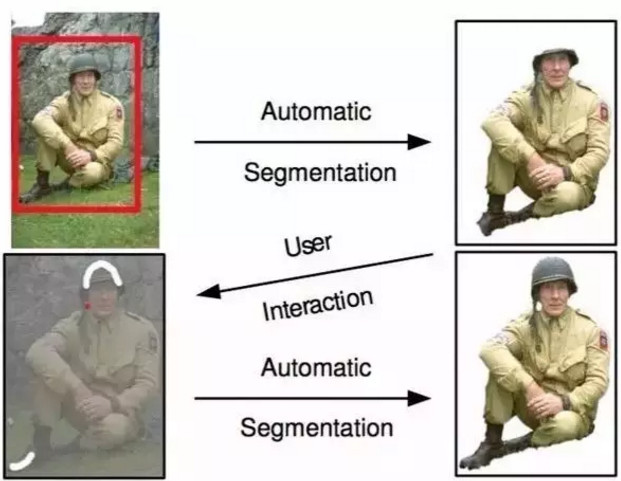
此时又需要进行人工干预了,需要手动在图像上进行标注,画白色线表示是希望保留的前景,红色表示背景,指导辅助机器进行判断,再次运算后,得到了较好的期望结果。
虽然看上去 Grab Cut 给出的结果还不错,但缺点也很明显,首先,它同 N-cut 一样也只能做二类语义分割,说人话就是一次只能分割一类,非黑即白,多个目标图像就要多次运算。其次,它需要人工干预,这个弱点在将来批量化处理和智能时代简直就是死穴。
OK,人类的智慧是无止境的,DeepLearning(深度学习)终于开始大行其道了。
在此前使用的图像识别算法中,主流的技术是卷积神经网络算法(Convolutional Neural Networks),简称 CNN。卷积神经网络就是一种深度神经网络。
但是在 2015 年的 CVPR 上发表了一篇很6的论文(路人甲:请问 CVPR 是神马?答:CVPR 可以简单理解为这个领域的最重量级的会议:国际计算机视觉与模式识别会议),提出了 FCN 即 全卷积神经网络(Fully Convolutional Networks)。
为什么说这个 FCN 论文很牛叉呢?看起来只是多了一个字而已呀,有什么不得了的呢?
嗯,不得不说,真是 “差之毫厘,谬以千里” 啊。
关于深度学习、神经网络等的其他相关知识不在介绍,有兴趣自己下去了解一下好了。下面直接进入卷积神经网络CNN的介绍。
先来复习一下卷积:
卷积有各种各样的公式,还有各种各样的推导算法,但是为了降低本文的难读指数,所以直接跳到卷积的物理意义,不要太 care 那些公式,其实卷积的物理意义,就是 “加权叠加”。在对图像处理进行卷积时,根据卷积核的大小,输入和输出之间也会有规模上的差异。
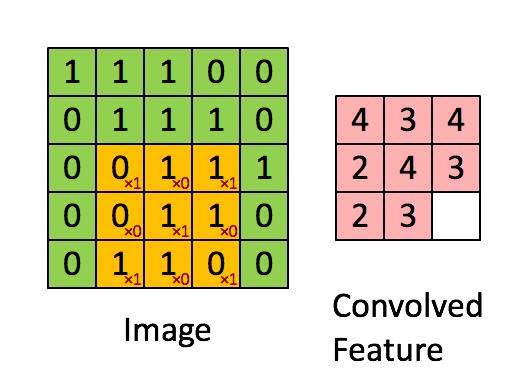
上图左边 5*5 的方块视为图像输入,黄色移动的 3*3 以及里面的数字(*1/*0)是卷积核,该卷积核按照步长为 1 的顺序依次从原始输入的左上角一直移动计算叠加到右下角,卷积核一共移动 9 次。九次的位置对应到右侧的 3*3 的相应格内,格中的数字便是卷积值,(此处是卷积核所覆盖的面积内元素相乘再累加的结果)。9 次移动计算完毕后,右侧 3*3 的新矩阵为此次卷积层的计算结果。
在实际计算过程中,输入是一张原始图片和滤波器 filter(一组固定的权重,也就是上面我们说的卷积核对应的实际意义)做内积后得到新的二维数据。不同的滤波器 filter 会得到不同的输出数据,比如轮廓、颜色深浅,如果想提取图像的不同特征,需要用不同的滤波器 filter 提取想要的关于图像的特定信息。
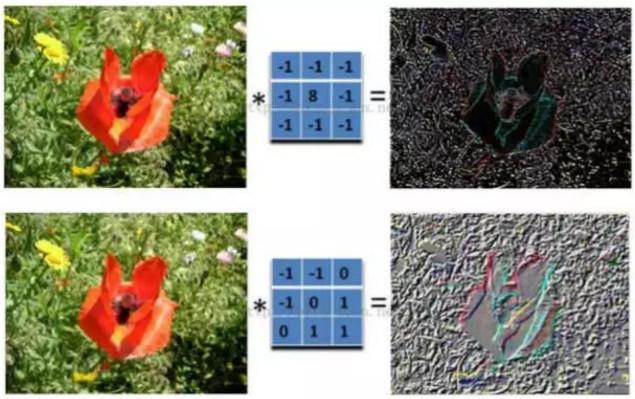
上图为一个卷积层中的卷积处理过程,注意上下两次卷积核内容是不同的,所以得到两种处理结果。等号右边的新的二维信息在 CNN 网络中,会作为下一个卷积层的输入,即在下一个卷积层计算时,右边的图像会作为输入的原始图像。
看一个有趣的段子:
在 CNN 网络中,一共会进行 5 次卷积层计算。
路人甲:那最后会得到一个什么鬼?
沈 MM:咳咳,在连续的 5 个卷积层计算后,紧跟这的是 3 个全连接层。
路人甲:什么是全连接层?
沈 MM:全连接层,并不是一个二维图像,而是—— 一个一维向量。
路人甲已哭晕在厕所。。。
初初读来,是不是有点懵,It doesn\'t matter。不妨先放着,以后自会懂得,trust me!
接下来介绍全卷积神经网络。
应该注意到,CNN 的输入是图像,输出是一个结果,或者说是一个值,一个概率值。而FCN 提出所追求的是:输入是一张图片,输出也是一张图片,学习像素到像素的映射。
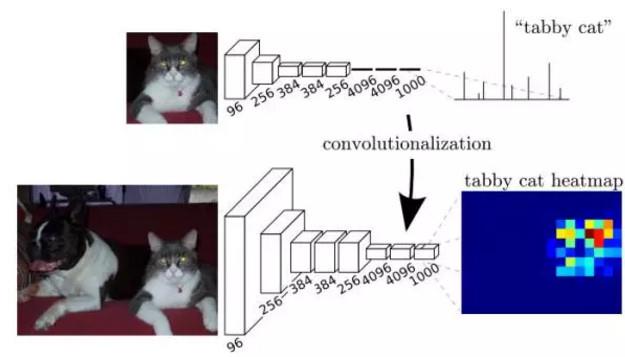
那么 “全卷积” 又体现在哪里呢?
CNN 网络中的后三层,都是一维的向量,计算方式不再采用卷积,所以丢失了二维信息,而 FCN 网络中,将这三层全部转化为 1*1 的卷积核所对应等同向量长度的多通道卷积层,使后三层也全部采用卷积计算,整个模型中,全部都是卷积层,没有向量,所以称为 “全卷积”。
FCN 将第 6 层和 7 层分别从 4096 长度的向量转化为 4096 通道的卷积层,第 8 层则是 21 通道的卷积层。之所以第 8 层从 1000 缩减到 21,是因为 FCN 使用的识别库是 PASCAL VOC,在 PASCAL VOC 中有 20 种物体分类,另外一个 background 分类。
以下(甚至全文)所用到的分割图片中不同的颜色就表示不同的物体类别,一共有 21 种颜色:

CNN 的识别是图像级的识别,也就是从图像到结果,而 FCN 的识别是像素级的识别,对输入图像的每一个像素在输出上都有对应的判断标注,标明这个像素最可能是属于一个什么物体 / 类别。
在此处特别要指出的是,在实际的图像语义分割测试时,输入是一个 H*W*3 的三通道彩色图像,而输出是一个 H*W 的矩阵。
这就可以简单看做每一个像素所携带的信息是多维的,比如颜色,就分为 3 层,分别对应 R、G、B 三个值。
所以在进行卷积的时候,每一个通道都是要独立计算的,计算完之后再叠加,得到最终卷积层结果。
如果卷积核移动的步长为 1,那么卷积是按照像素排列去挨个计算的,计算量可想而知会有多么庞大。但是在实际中,相邻的像素往往都是一类,按照像素依次计算就显得冗余,所以在卷积之后会对输出进行一次池化(pooling)处理。
那么什么又是池化呢?我们来看:
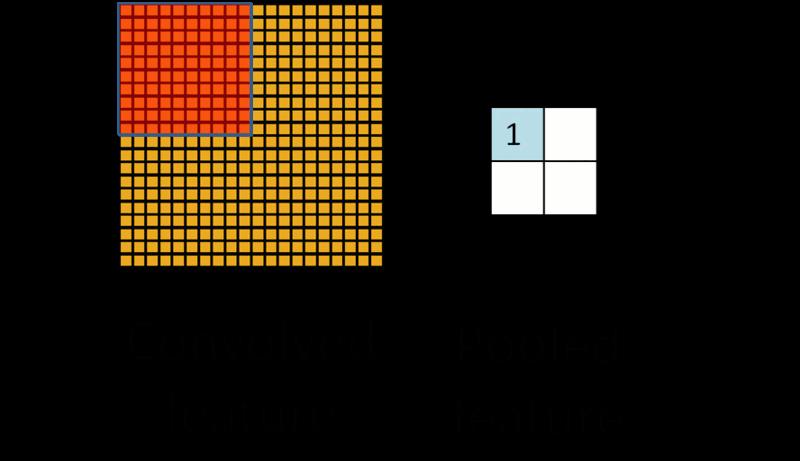
池化简单来说就是将输入图像切块,大部分时候我们选择不重叠的区域,假如池化的分割块大小为 h*h,分割的步长为 j,那么一般 h=j,就像上图,如果需要重叠,只需要 h>j 即可(这个步骤请停留一秒理解一下,很好懂的)。
对完整图像切分,再取切分区域中所有值的均值或最大值作为代表该区域的新值,放入池化后的二维信息图中。得到的新图就是池化结果。
在 CNN 和 FCN 的网络模型中,每一个卷积层,都包含了 [卷积 + 池化] 处理,这就是传说中的 “下采样”,但这样处理之后的结果是:图像的像素信息变小了,每一层的像素信息都是前一层的 1/2 大小,到第五层的时候,图像大小为原始图像的 1/32。
在 CNN 算法里,这并没有什么要紧的,因为 CNN 最终只输出一个结果:“这个图上是个啥”,但是 FCN 不同,FCN 是像素级别的识别,也就是输入有多少像素,输出就要多少像素,像素之间完全映射,并且在输出图像上有信息标注,指明每一个像素可能是什么物体 / 类别。
所以,就必须对这 1/32 的图像进行还原。
这里用到个纯数学技术,叫 “反卷积”,对第 5 层进行反卷积,可以将图像扩充至原来的大小(严格说是近似原始大小,一般会大一点,但是会裁剪掉,为什么会大的原理略复杂,这里先不提,有兴趣且有资历可再行理解)。
——这个 “反卷积” 称为 “上采样”。(和下采样对应)
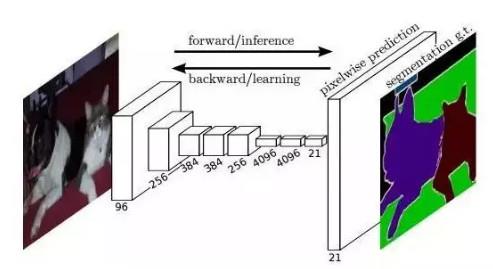
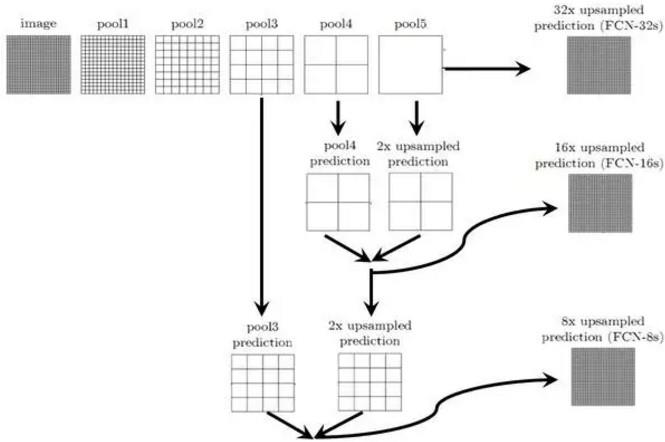
在技术上,我们可以对任一层卷积层做反卷积处理,得到最后的图像,比如用第三层 (8s-8 倍放大),第四层 (16s-16 倍放大),第五层 (32s-32 倍放大) 得到的分割结果。
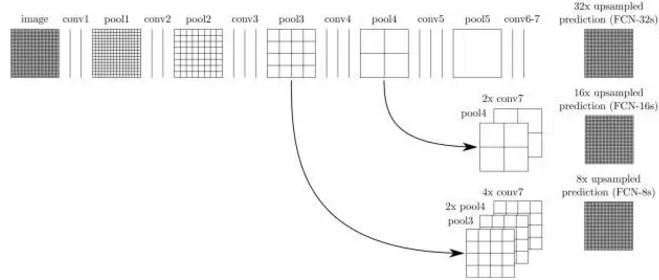
来看一张各层还原后的对比图,分别是:
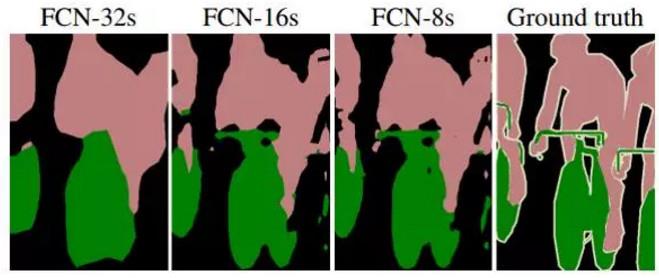
通过对比可以很明显看到:在 16 倍还原和 8 倍还原时,能够看到更好的细节,32 倍还原出来的图,在边缘分割和识别上,虽然大致的意思都出来了,但细节部分(边缘)真的很粗糙,甚至无法看出物体形状。
那么为什么会这样呢?这里就涉及到一个感受域(receptive field)的概念。较浅的卷积层(靠前的)的感受域比较小,学习感知细节部分的能力强,较深的隐藏层 (靠后的),感受域相对较大,适合学习较为整体的、相对更宏观一些的特征。所以在较深的卷积层上进行反卷积还原,自然会丢失很多细节特征。
于是我们会在反卷积步骤时,考虑采用一部分较浅层的反卷积信息辅助叠加,更好的优化分割结果的精度:
尽管 FCN 的提出是一条很6的路,但还是无法避免有很多问题,比如,精度问题,对细节不敏感,以及像素与像素之间的关系,忽略空间的一致性等问题。
于是更牛的大牛就出现了。有牛人提出一种新的卷积计算方式,开始称为 “带 hole” 的卷积,也就是使用一种 “疏松的卷积核” 来计算,以此来取代池化的处理。
上面已经讲过,池化操作能够减少计算量,同时也能防止计算结果过拟合,那么单纯取消池化操作又会使单层网络的感受域缩小。如果使用 “疏松的卷积核” 来处理卷积,可以达到在不增加计算量的情况下增加感受域,弥补不进行池化处理后的精度问题。(这种带洞的卷积方式后来起了一个高雅的名字叫做:“Dilated Convolutions”。)这种方式人为加大了卷积核内部元素之间的距离,可参考下图:
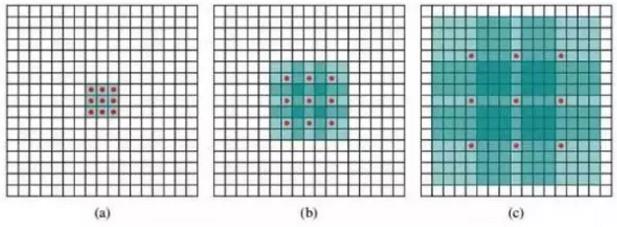
红点表示卷积核的元素,绿色表示感受域,黑线框表示输入图像。
a 为原始卷积核计算时覆盖的感受域,b 为当卷积核覆盖的元素间距离增大的情况,不再在连续的空间内去做卷积,跳着做,当这个距离增加的越大时,单次计算覆盖的感受域面积越大。
上图不太好理解的话再来看一张图:
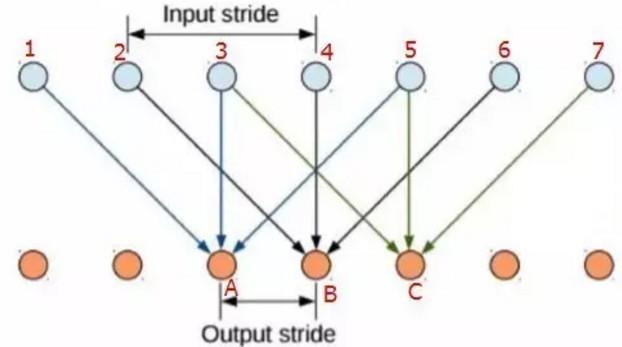
上层绿色点表示输入层像素点,下层黄色是输出层(单次计算时的层级关系),当卷积核元素间距为 0 时(相邻),123 对应输出 A,234 对应输出 B,345 对应输出 C,那么输出 ABC 三个元素结果的感受域只覆盖了 12345 这几个原始像素点。
如果采用稀疏的卷积核,假设间距为 1(相当于卷积计算时跳一个像素再取值计算),如图所示,那么结果 A 对应的输入是 135,结果 B 对应的输入是 246,结果 C 对应的输入是 357,同样输出 ABC 三个结果,在原始图像上取的像素点的长度就多了。
这是水平 X 轴方向上的扩展,在 Y 轴上也会有同样的扩展,感受域在没有增加计算(相对于池化操作后)的情况下增大了,并且保留了足够多的细节信息,对图像还原后的精度有明显的提升。是不是很有趣O(∩_∩)O哈哈~
看一下对比图:

第一列是原始图像,最后一列是手工标注的训练输入图像,第二列为 FCN 在 1/8 倍数下的还原,第三列则是采用了新的卷积算法的还原图像,可以很明显看到,第三列对细节的分割明显优于第二列 FCN 8 倍的图像。
刚才还提到了第二个问题,即像素与像素之间的逻辑关系的问题,毕竟前面再6的算法也只是单纯的计算,而没有根据物理意义,去进行判断。比如需要判断在输出的标注里面,这些结果是否合法(符合现实逻辑)。
很多以深度学习为框架的图像语义分割系统都使用了一种叫做 “条件随机场”( Conditional Random Field,简称 CRF)的技术作为输出结果的优化后处理手段。其实类似技术种类较多,比如还有马尔科夫随机场 (MRF) 和高斯条件随机场 (G-CRF) 用的也比较多,原理都较为类似。
继续,简单来介绍一下 “条件随机场” 的概念。
FCN 是像素到像素的影射,所以最终输出的图片上每一个像素都是标注了分类的,将这些分类简单地看成是不同的变量,每个像素都和其他像素之间建立一种连接,连接就是相互间的关系。于是就会得到一个 “完全图”:
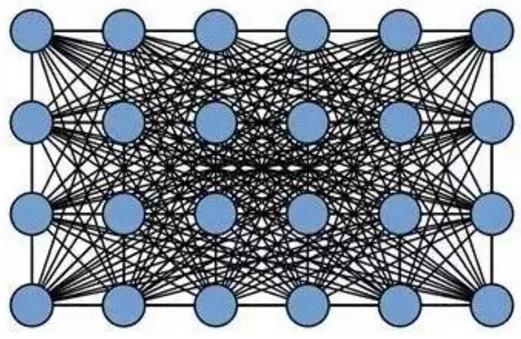
上图是以 4*6 大小的图像像素阵列表示的简易版。
那么在全连接的 CRF 模型中,有一个对应的能量函数:
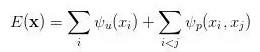
相信广大理工科学生对这个公式里各种符号是熟悉的。如若不是,也没关系,不知道符号就暂且不必知道了,我们先解决问题,当务之急就是一定要首先知道这个公式是干嘛的:
其中等号右边第一个一元项,表示像素对应的语义类别,其类别可以由 FCN 或者其他语义分割模型的预测结果得到;而第二项为二元项,二元项可将像素之间的语义联系 / 关系考虑进去。
这么说太抽象,举个简单的例子,“天空”和 “鸟” 这样的像素在物理空间是相邻的概率,应该要比 “天空” 和 “鱼” 这样像素相邻的概率大,那么天空的边缘就更应该判断为鸟而不是鱼(从概率的角度)。看到这句话,很好理解了吧~
通过对这个能量函数优化求解,把明显不符合事实的识别判断剔除掉,替换成合理的解释,最后可以得到对 FCN 的图像语义预测结果的优化,生成最终的语义分割结果。
优化后的对比图:

上图第二列是 FCN 网络 8 倍还原分割结果,第三列是将 CRF 植入 FCN 处理后的结果。
可以很明显的看到,第三列的物体识别无论是轮廓细节分割还是物体识别,都优于第二列,特别是第二行的沙发中有奇怪的红色东西的识别,在进行 CRF 优化之后,还原成了绿色的沙发。
目前的这种机器学习方式还属于监督性学习,科学家们还是希望将来可以实现半监督或弱监督式学习,这样更类似人类的学习认知方式。
在这条道路上,还有很多有趣的东西,比如示例级别(instance level)的图像语义分割问题也同样热门。该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来)。
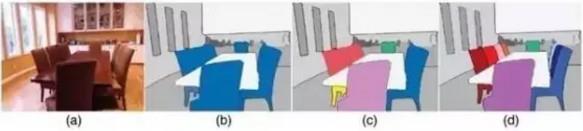
另外,在目前的计算技术水平下(硬件软件),使用 FCN 训练建模的时间大约需要三周,这也说明在这个领域里还有很多值得探索和需要解决的问题。
对此有兴趣的同学们自己去继续研究吧,你可以的,哈哈!
曾有一个业界大牛说过这样一段话,送给大家:
“华人在计算机视觉领域的研究水平越来越高,这是非常振奋人心的事。我们中国错过了工业革命,错过了电气革命,信息革命也只是跟随状态。但人工智能的革命,我们跟世界上的领先国家是并肩往前跑的。能身处这个时代浪潮之中,做一番伟大的事业,经常激动的夜不能寐。”
最后,我也想说点什么与君共勉,人的一生,每个阶段做每个阶段的事情,就像庄稼,春种秋收,春天不抓住机会好好扎根,汲取营养,努力生长,到了秋天,只有被遗弃的下场,而那时想再好好汲取营养已经晚了,大自然不会因为你没生长饱满没做好准备就为你停留等待,无论你长成何种样子,都要被一同收割。命运总体是公平的,欠下的始终要还,有多少人,此生再无力偿还,所以,不要欠。身处这个阶段的时候,一定要好好珍惜,这是我们唯一能做的。求学,钻研,为人,处事,交友……无一不是如此。劝君莫惜金缕衣,劝君惜取少年时。花开堪折直须折,莫待无花空折枝。我很庆幸我对人工智能感兴趣,而我又恰好为计算机专业,做自己喜欢的事情本身就是一件快乐的事情。
年轻没有失败,奋斗创造未来。AI浪潮业已来临,Are you ready?
以上是关于图像语义分割的前世今生的主要内容,如果未能解决你的问题,请参考以下文章