爬虫:网页里元素的xpath结构,scrapy不一定就找的到
Posted 沧海一粟,何以久远
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫:网页里元素的xpath结构,scrapy不一定就找的到相关的知识,希望对你有一定的参考价值。
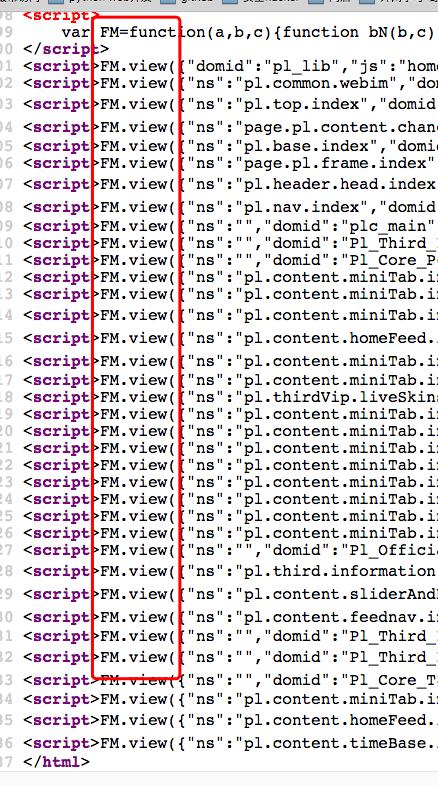
这种情况原因是html界面关联的js文件可能会动态修改DOM结构,这样浏览器完成了动态修改DOM,在 浏览器上看到的DOM结构,就和后台抓到的DOM结构不通
举例:新浪微博发的微博,在浏览器通过firebug的插件FirePath可以很容易计算出xpath

通过Firefinder可以查看xpath的匹配情况

但是查看页面的源代码,可以发现,微博的内容都是包含在js里的FM.view里的,这些会被js动态生成DOM,但是抓取返回的内容都是下面这些内容,是还没有生成DOM的
以上是关于爬虫:网页里元素的xpath结构,scrapy不一定就找的到的主要内容,如果未能解决你的问题,请参考以下文章