请教网页里的特定数据怎么抓取?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了请教网页里的特定数据怎么抓取?相关的知识,希望对你有一定的参考价值。
如图,是因为网页有屏蔽吗?求python的代码抓取
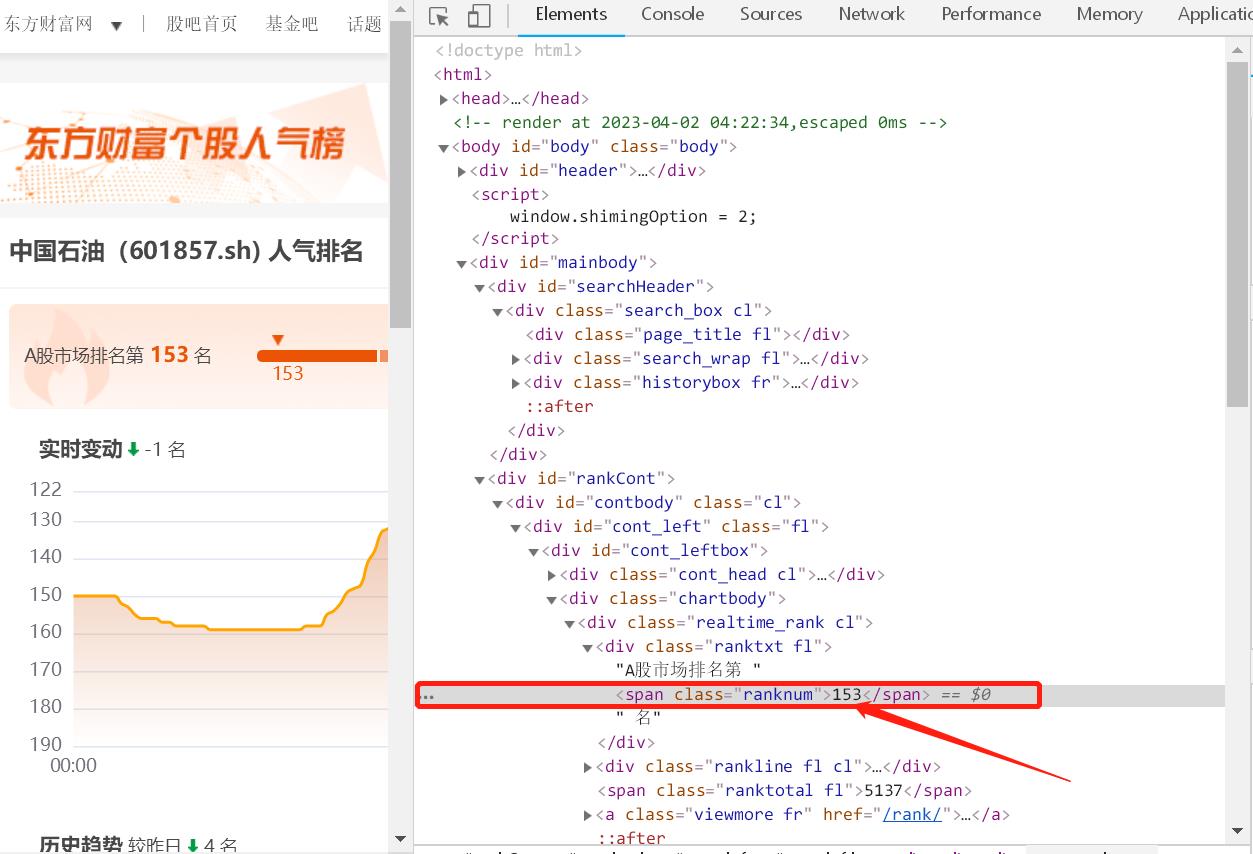
1. 使用 Python 的 Requests 库请求网页,然后使用 Beautiful Soup 库进行页面解析,提取目标数据。
2. 使用 Selenium 库模拟浏览器操作,通过 CSS Selector 或 XPath 定位特定元素,提取目标数据。
3. 使用 Scrapy 爬虫框架,在爬虫脚本中定义提取规则,自动抓取网页并提取目标数据。
需要注意的是,进行网页抓取时,应遵守网站的 Robots 协议,不要过于频繁地进行抓取,以免给网站带来负担。此外还需要注意数据的使用方式是否符合法规和道德规范。追问
可以帮我把这几句代码写出来吗?我要的这个数字
参考技术A 抓取网页中的特定数据可以使用爬虫技术,以下是一些简单的步骤:1. 找到目标网页的URL。
2. 使用Python等编程语言中的爬虫工具(如Beautiful Soup)来获取网页的html内容。
3. 对HTML内容进行解析,使用特定的标签和属性找到需要的数据。
4. 提取数据并存储到数据文件或者数据库中。
需要注意的是,抓取网页数据需要遵守相关法律法规,尊重网站所有者的权益,不得非法盗取或滥用数据。
自动抓取页面生成接口的方法
自动抓取页面生成接口的方法?答:自动抓取页面生成接口的方法:第一步,将web前端页面的表格文件传输到后台并进行分布式存储,保障数据的容灾能力、备份以及后期的弹性扩展;第二步,对表格文件的数据信息进行分析和识别,并添加传入参数;
第三步,将添加传入参数后的数据导入数据库,自动生成接口信息;
第四步,web界面调用自动生成的接口,获取返回的数据信息即可得到查询结果。 参考技术A 1、使用爬虫抓取页面,爬虫可以通过网页的URL地址来获取网页的内容,然后将网页内容转换成文本或者特定格式的数据;
2、使用解析器对爬取的网页内容进行解析,解析器可以根据网页的结构和内容,把网页内容解析成特定格式的数据;
3、将解析后的数据按照特定的格式封装成接口,以便外部系统调用;
4、使用接口测试工具对接口进行测试,保证接口的可用性。 参考技术B 第一步,将web前端页面的表格文件传输到后台并进行分布式存储,保障数据的容灾能力、备份以及后期的弹性扩展;
第二步,对表格文件的数据信息进行分析和识别,并添加传入参数;
第三步,将添加传入参数后的数据导入数据库,自动生成接口信息;
第四步,web界面调用自动生成的接口,获取返回的数据信息即可得到查询结果。 提前分配好权限,规定excel表格的格式,从web端进行人机交互,将excel表格自动上传到后台服务器内进行程序处理,自动化的生成接口。
查看更多 参考技术C 根据我们的研究,自动抓取页面生成接口的方法是使用爬虫工具抓取网页内容,然后开发者根据所需的数据对爬取的内容进行解析,最后将结果转换成接口的形式。
以上是关于请教网页里的特定数据怎么抓取?的主要内容,如果未能解决你的问题,请参考以下文章
请教,怎么将mysql里的大数据同步到 sqlserver2008里