一个完整的大作业:淘宝口红销量top10的销量和评价
Posted 09方俊晖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个完整的大作业:淘宝口红销量top10的销量和评价相关的知识,希望对你有一定的参考价值。
网站:淘宝口红搜索页
https://s.taobao.com/search?q=%E5%8F%A3%E7%BA%A2&sort=sale-desc
先爬取该页面前十的口红的商品名、销售量、价格、评分以及评论数,发现该网页使用了json的方式,使用正则表达式匹配字段,抓取我们
所需要的信息。启用用户代理爬取数据,预防该网站的反爬手段,并把结果存入到csv文件中,效果如下。
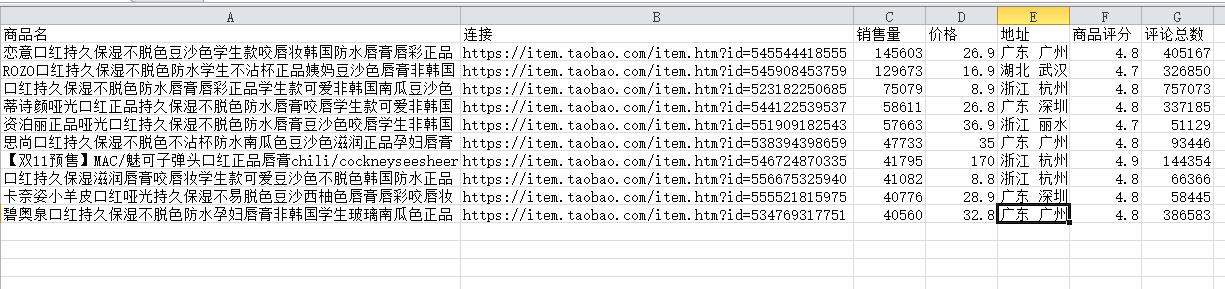
成功爬取到淘宝口红top10的基本信息后,发现评论并不在同一页面上,并且该页面存在着进入评论页的关键字,爬取下来后放入一个列表中,然后用循环整个列表和页数,使用
正则表达式,匹配评论的关键字,成功爬取淘宝top10口红的评论进十万条,如下图所示。


完整的源代码如下:
from urllib import request
import re
import csv
import time
itemId=[]
sellerId=[]
links=[]
titles=[]
# ,\'商品评分\',\'评论总数\'
def get_product_info():
fileName = \'商品.csv\'
comment_file = open(fileName, \'w\', newline=\'\')
write = csv.writer(comment_file)
write.writerow([\'商品名\', \'连接\', \'销售量\', \'价格\', \'地址\',\'商品评分\',\'评论总数\'])
comment_file.close()
fileName2 = \'评价.csv\'
productfile = open(fileName2, \'w\', newline=\'\')
product_write = csv.writer(productfile)
product_write.writerow([\'商品id\',\'商品名\',\'时间\', \'颜色分类\', \'评价\'])
productfile.close()
def get_product():
global itemId
global sellerId
global titles
url = \'https://s.taobao.com/search?q=%E5%8F%A3%E7%BA%A2&sort=sale-desc\'
head = {}
# 写入User Agent信息
head[
\'User-Agent\'] = \'Mozilla/5.0 (Linux; android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (Khtml, like Gecko) Chrome/18.0.1025.166 Safari/535.19\'
# 创建Request对象
req = request.Request(url, headers=head)
# 传入创建好的Request对象
response = request.urlopen(req, timeout=30)
# 读取响应信息并解码
html = response.read().decode(\'utf-8\')
# 打印信息
pattam_id = \'"nid":"(.*?)"\'
raw_title = \'"raw_title":"(.*?)"\'
view_price = \'"view_price":"(.*?)"\'
view_sales = \'"view_sales":"(.*?)"\'
item_loc = \'"item_loc":"(.*?)"\'
user_id = \'"user_id":"(.*?)"\'
all_id = re.compile(pattam_id).findall(html)
all_title = re.compile(raw_title).findall(html)
all_price = re.compile(view_price).findall(html)
all_sales = re.compile(view_sales).findall(html)
all_loc = re.compile(item_loc).findall(html)
all_userid = re.compile(user_id).findall(html)
print("开始收集信息")
try:
for i in range(10):
this_id = all_id[i]
this_title = all_title[i]
this_price = all_price[i]
this_sales = all_sales[i]
this_loc = all_loc[i]
this_userid = all_userid[i]
id = str(this_id)
title = str(this_title)
price = str(this_price)
sales = str(this_sales)
loc = str(this_loc)
uid = str(this_userid)
link = \'https://item.taobao.com/item.htm?id=\' + str(id)
shoplink = \'https://dsr-rate.tmall.com/list_dsr_info.htm?itemId=\' +str(id)
head = {}
# 写入User Agent信息
head[
\'User-Agent\'] = \'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\'
# 创建Request对象
req2 = request.Request(shoplink, headers=head)
# 传入创建好的Request对象
response2 = request.urlopen(req2, timeout=30)
# 读取响应信息并解码
html2 = response2.read().decode(\'utf-8\')
gradeAvg = \'"gradeAvg":(.*?,)"\'
rateTotal = \'"rateTotal":(.*?,)"\'
all_gradeAvg = re.compile(gradeAvg).findall(html2)
all_rateTotal = re.compile(rateTotal).findall(html2)
this_gradeAvg = all_gradeAvg
this_rateTotal = all_rateTotal
gradeAvg = str(this_gradeAvg)[2:-3]
rateTotal = str(this_rateTotal)[2:-3]
# print("平均分:" + gradeAvg)
# print("评论总数:" + rateTotal)
# print("商品名:" + title)
# print("连接:" + link)
# print("销售量:" + sales)
# print("价格:" + price)
# print("地址:" + loc)
itemId.append(id)
sellerId.append(uid)
titles.append(title)
comment_file = open(\'商品.csv\', \'a\', newline=\'\')
write = csv.writer(comment_file)
write.writerow([title, link, sales, price, loc,gradeAvg,rateTotal])
comment_file.close()
except (req.ConnectionError, IndexError, UnicodeEncodeError, TimeoutError) as e:
print(e.args)
except response.URLError as e:
print(e.reason)
except IOError as e:
print(e)
# HTTPError
except response.HTTPError as e:
print(e.code)
print("商品基本信息收集完毕")
def get_product_comment():
# 具体商品获取评论
# 前十销量商品
global title
for i in range(10):
print("正在收集第{}件商品评论".format(str(i + 1)))
for j in range(1,551):
# 商品评论的url
detaillinks="https://rate.tmall.com/list_detail_rate.htm?itemId="+itemId[i]+"&sellerId="+sellerId[i]+"¤tPage="+str(j)
head = {}
# 写入User Agent信息
head[\'User-Agent\'] = \'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\'
req1 = request.Request(detaillinks, headers=head)
# 传入创建好的Request对象
response1 = request.urlopen(req1,timeout=30)
# 读取响应信息并解码
html1 = response1.read().decode(\'gbk\')
# 打印信息
# 评论
rateContent = \'"rateContent":"(.*?)"\'
# 时间
rateDate = \'"rateDate":"(.*?)"\'
# 颜色
auctionSku = \'"auctionSku":"(.*?)"\'
all_date = re.compile(rateDate).findall(html1)
all_content = re.compile(rateContent).findall(html1)
all_sku = re.compile(auctionSku).findall(html1)
# 获取全部评论
try:
for k in range(0, len(all_content)):
this_date = all_date[k]
this_content = all_content[k]
this_sku = all_sku[k]
date = str(this_date)
content = str(this_content)
sku = str(this_sku)
# print("时间:" + date)
# print(sku)
# print("评价:" + content)
productfile = open(\'评价.csv\', \'a\', newline=\'\')
product_write = csv.writer(productfile)
product_write.writerow([itemId[i] + "\\t", titles[i], date, sku, content])
productfile.close()
except (req1.ConnectionError, IndexError, UnicodeEncodeError, TimeoutError) as e:
print(e.args)
# URLError产生的原因:网络无连接,即本机无法上网;连接不到特定的服务器;服务器不存在
except response1.URLError as e:
print(e.reason)
# HTTPError
except response1.HTTPError as e:
print(e.code)
except IOError as e:
print(e)
print("第{}件商品评论收集完成".format(str(i+1)))
if __name__ == "__main__":
start=time.time()
get_product_info()
get_product()
# get_product_comment()
end=time.time()
total=end-start
print(\'本次爬行用时:{:.2f}s!\'.format(total))
from urllib import request
import re
import csv
import time
itemId=[]
sellerId=[]
links=[]
titles=[]
# ,\'商品评分\',\'评论总数\'
def get_product_info():
fileName = \'商品.csv\'
comment_file = open(fileName, \'w\', newline=\'\')
write = csv.writer(comment_file)
write.writerow([\'商品名\', \'连接\', \'销售量\', \'价格\', \'地址\',\'商品评分\',\'评论总数\'])
comment_file.close()
fileName2 = \'评价.csv\'
productfile = open(fileName2, \'w\', newline=\'\')
product_write = csv.writer(productfile)
product_write.writerow([\'商品id\',\'商品名\',\'时间\', \'颜色分类\', \'评价\'])
productfile.close()
def get_product():
global itemId
global sellerId
global titles
url = \'https://s.taobao.com/search?q=%E5%8F%A3%E7%BA%A2&sort=sale-desc\'
head = {}
# 写入User Agent信息
head[
\'User-Agent\'] = \'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\'
# 创建Request对象
req = request.Request(url, headers=head)
# 传入创建好的Request对象
response = request.urlopen(req, timeout=30)
# 读取响应信息并解码
html = response.read().decode(\'utf-8\')
# 打印信息
pattam_id = \'"nid":"(.*?)"\'
raw_title = \'"raw_title":"(.*?)"\'
view_price = \'"view_price":"(.*?)"\'
view_sales = \'"view_sales":"(.*?)"\'
item_loc = \'"item_loc":"(.*?)"\'
user_id = \'"user_id":"(.*?)"\'
all_id = re.compile(pattam_id).findall(html)
all_title = re.compile(raw_title).findall(html)
all_price = re.compile(view_price).findall(html)
all_sales = re.compile(view_sales).findall(html)
all_loc = re.compile(item_loc).findall(html)
all_userid = re.compile(user_id).findall(html)
print("开始收集信息")
try:
for i in range(10):
this_id = all_id[i]
this_title = all_title[i]
this_price = all_price[i]
this_sales = all_sales[i]
this_loc = all_loc[i]
this_userid = all_userid[i]
id = str(this_id)
title = str(this_title)
price = str(this_price)
sales = str(this_sales)
loc = str(this_loc)
uid = str(this_userid)
link = \'https://item.taobao.com/item.htm?id=\' + str(id)
shoplink = \'https://dsr-rate.tmall.com/list_dsr_info.htm?itemId=\' +str(id)
head = {}
# 写入User Agent信息
head[
\'User-Agent\'] = \'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\'
# 创建Request对象
req2 = request.Request(shoplink, headers=head)
# 传入创建好的Request对象
response2 = request.urlopen(req2, timeout=30)
# 读取响应信息并解码
html2 = response2.read().decode(\'utf-8\')
gradeAvg = \'"gradeAvg":(.*?,)"\'
rateTotal = \'"rateTotal":(.*?,)"\'
all_gradeAvg = re.compile(gradeAvg).findall(html2)
all_rateTotal = re.compile(rateTotal).findall(html2)
this_gradeAvg = all_gradeAvg
this_rateTotal = all_rateTotal
gradeAvg = str(this_gradeAvg)[2:-3]
rateTotal = str(this_rateTotal)[2:-3]
# print("平均分:" + gradeAvg)
# print("评论总数:" + rateTotal)
# print("商品名:" + title)
# print("连接:" + link)
# print("销售量:" + sales)
# print("价格:" + price)
# print("地址:" + loc)
itemId.append(id)
sellerId.append(uid)
titles.append(title)
comment_file = open(\'商品.csv\', \'a\', newline=\'\')
write = csv.writer(comment_file)
write.writerow([title, link, sales, price, loc,gradeAvg,rateTotal])
comment_file.close()
except (req.ConnectionError, IndexError, UnicodeEncodeError, TimeoutError) as e:
print(e.args)
except response.URLError as e:
print(e.reason)
except IOError as e:
print(e)
# HTTPError
except response.HTTPError as e:
print(e.code)
print("商品基本信息收集完毕")
def get_product_comment():
# 具体商品获取评论
# 前十销量商品
global title
for i in range(10):
print("正在收集第{}件商品评论".format(str(i + 1)))
for j in range(1,551):
# 商品评论的url
detaillinks="https://rate.tmall.com/list_detail_rate.htm?itemId="+itemId[i]+"&sellerId="+sellerId[i]+"¤tPage="+str(j)
head = {}
# 写入User Agent信息
head[\'User-Agent\'] = \'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\'
req1 = request.Request(detaillinks, headers=head)
# 传入创建好的Request对象
response1 = request.urlopen(req1,timeout=30)
# 读取响应信息并解码
html1 = response1.read().decode(\'gbk\')
# 打印信息
# 评论
rateContent = \'"rateContent":"(.*?)"\'
# 时间
rateDate = \'"rateDate":"(.*?)"\'
# 颜色
auctionSku = \'"auctionSku":"(.*?)"\'
all_date = re.compile(rateDate).findall(html1)
all_content = re.compile(rateContent).findall(html1)
all_sku = re.compile(auctionSku).findall(html1)
# 获取全部评论
try:
for k in range(0, len(all_content)):
this_date = all_date[k]
this_content = all_content[k]
this_sku = all_sku[k]
date = str(this_date)
content = str(this_content)
sku = str(this_sku)
# print("时间:" + date)
# print(sku)
# print("评价:" + content)
productfile = open(\'评价.csv\', \'a\', newline=\'\')
product_write = csv.writer(productfile)
product_write.writerow([itemId[i] + "\\t", titles[i], date, sku, content])
productfile.close()
except (req1.ConnectionError, IndexError, UnicodeEncodeError, TimeoutError) as e:
print(e.args)
# URLError产生的原因:网络无连接,即本机无法上网;连接不到特定的服务器;服务器不存在
except response1.URLError as e:
print(e.reason)
# HTTPError
except response1.HTTPError as e:
print(e.code)
except IOError as e:
print(e)
print("第{}件商品评论收集完成".format(str(i+1)))
if __name__ == "__main__":
start=time.time()
get_product_info()
get_product()
# get_product_comment()
end=time.time()
total=end-start
print(\'本次爬行用时:{:.2f}s!\'.format(total))
以上是关于一个完整的大作业:淘宝口红销量top10的销量和评价的主要内容,如果未能解决你的问题,请参考以下文章