PyTorch深度学习:60分钟入门(Translation)
Posted cathy_mu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch深度学习:60分钟入门(Translation)相关的知识,希望对你有一定的参考价值。
这是https://zhuanlan.zhihu.com/p/25572330的学习笔记。
- Tensors
Tensors和numpy中的ndarrays较为相似, 因此Tensor也能够使用GPU来加速运算。
from __future__ import print_function import torch x = torch.Tensor(5, 3) # 构造一个未初始化的5*3的矩阵 x = torch.rand(5, 3) # 构造一个随机初始化的矩阵 x # 此处在notebook中输出x的值来查看具体的x内容 x.size() #NOTE: torch.Size 事实上是一个tuple, 所以其支持相关的操作* y = torch.rand(5, 3) #此处 将两个同形矩阵相加有两种语法结构 x + y # 语法一 torch.add(x, y) # 语法二 # 另外输出tensor也有两种写法 result = torch.Tensor(5, 3) # 语法一 torch.add(x, y, out=result) # 语法二 y.add_(x) # 将y与x相加 # 特别注明:任何可以改变tensor内容的操作都会在方法名后加一个下划线‘_‘ # 例如:x.copy_(y), x.t_(), 这俩都会改变x的值。 #另外python中的切片操作也是资次的。 x[:,1] #这一操作会输出x矩阵的第二列的所有值
http://pytorch.org/docs/master/torch.html
tensors的100+种用法。
- CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA?是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
-
Numpy桥
将Torch的Tensor和numpy的array相互转换简直就是洒洒水啦。注意Torch的Tensor和numpy的array会共享他们的存储空间,修改一个会导致另外的一个也被修改。
# 此处演示tensor和numpy数据结构的相互转换 a = torch.ones(5) b = a.numpy() # 此处演示当修改numpy数组之后,与之相关联的tensor也会相应的被修改 a.add_(1) print(a) print(b) # 将numpy的Array转换为torch的Tensor import numpy as np a = np.ones(5) b = torch.from_numpy(a) np.add(a, 1, out=a) print(a) print(b) # 另外除了CharTensor之外,所有的tensor都可以在CPU运算和GPU预算之间相互转换 # 使用CUDA函数来将Tensor移动到GPU上 # 当CUDA可用时会进行GPU的运算 if torch.cuda.is_available(): x = x.cuda() y = y.cuda() x + y
PyTorch中的神经网络
接下来介绍pytorch中的神经网络部分。PyTorch中所有的神经网络都来自于autograd包
首先我们来简要的看一下,之后我们将训练我们第一个的神经网络。
Autograd: 自动求导
autograd 包提供Tensor所有操作的自动求导方法。
这是一个运行时定义的框架,这意味着你的反向传播是根据你代码运行的方式来定义的,因此每一轮迭代都可以各不相同。
以这些例子来讲,让我们用更简单的术语来看看这些特性。
- autograd.Variable 这是这个包中最核心的类。 它包装了一个Tensor,并且几乎支持所有的定义在其上的操作。一旦完成了你的运算,你可以调用 .backward()来自动计算出所有的梯度。
你可以通过属性 .data 来访问原始的tensor,而关于这一Variable的梯度则集中于 .grad 属性中。
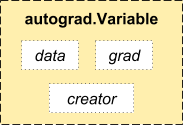
- 还有一个在自动求导中非常重要的类 Function。
Variable 和 Function 二者相互联系并且构建了一个描述整个运算过程的无环图。每个Variable拥有一个 .creator 属性,其引用了一个创建Variable的 Function。(除了用户创建的Variable其 creator 部分是 None)。
如果你想要进行求导计算,你可以在Variable上调用.backward()。 如果Variable是一个标量(例如它包含一个单元素数据),你无需对backward()指定任何参数,然而如果它有更多的元素,你需要指定一个和tensor的形状想匹配的grad_output参数。
from torch.autograd import Variable x = Variable(torch.ones(2, 2), requires_grad = True) y = x + 2 y.creator # y 是作为一个操作的结果创建的因此y有一个creator z = y * y * 3 out = z.mean() # 现在我们来使用反向传播 out.backward() # out.backward()和操作out.backward(torch.Tensor([1.0]))是等价的 # 在此处输出 d(out)/dx x.grad
最终得出的结果应该是一个全是4.5的矩阵。设置输出的变量为o。我们通过这一公式来计算:
,
,
,因此,
,最后有
你可以使用自动求导来做许多疯狂的事情。
x = torch.randn(3) x = Variable(x, requires_grad = True) y = x * 2 while y.data.norm() < 1000: y = y * 2 gradients = torch.FloatTensor([0.1, 1.0, 0.0001]) //float是类型。 y.backward(gradients) //这行什么意思 x.grad //这行呢?
以上是关于PyTorch深度学习:60分钟入门(Translation)的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch深度学习:60分钟入门(Translation)
PyTorch深度学习60分钟快速入门 Part1:PyTorch是什么?
PyTorch深度学习60分钟快速入门 Part0:系列介绍