TOP100summit:分享实录Twitter 新一代实时计算平台Heron
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TOP100summit:分享实录Twitter 新一代实时计算平台Heron相关的知识,希望对你有一定的参考价值。
本篇文章内容来自2016年TOP100summit Twitter technical lead for Heron Maosong Fu 的案例分享。
编辑:Cynthia
Maosong Fu:Technical Lead for Heron at Twitter
导读:人们需要处理的数据规模和对结果的响应速度需求增长得越来越快,但摩尔定律逐渐失效,系统设计者再也无法简单地通过硬件升级来获得巨大的性能提升。这时,我们希望可以把过去的单机任务分割给许多计算机进行并行处理。我们需要分布式系统,从资源的分布式管理、分布式消息分发、分布式计算到分布式存储等等。而大规模实时计算,出于低时延、高吞吐、计算准确的考虑,日益变成了一个愈发值得关注的问题。为此,Twitter开发了新一代实时计算平台Heron,来针对性解决这些问题。
一、问题的提出
大规模运行实时计算任务,首要的问题是:如何降低开发实时计算任务的门槛,使得开发可以实时处理海量数据的程序,像开发单线程程序那么简单。此前,我们使用自主研发的分布式实时计算框架Storm(于2011年开源并且成为业界最流行的实时计算框架),很好地解决了这个问题。
但随着Twitter的数据规模不断提高,我们遇到了新的需求和挑战,包括:每分钟数十亿的事件;大规模处理具有次秒级延迟和可预见的行为;在故障情况下,具有很高的数据准确性;具有很好的弹性,可以应对临时流量峰值和管道阻塞;易于调试;易于在共享基础设施中部署。
如何低时延、高吞吐,并且满足上述需求地处理这些海量数据是一个重大的挑战。
为此,我们考虑过以下方案:
● 改进Storm
● 使用业界流行的开源或者商业方案
● 重新根据需求设计实现一个实时计算框架
这三个方案的成本是依次上升的,所以我们的尝试也是从前往后的。
首先我们对Storm进行了大量的改进,改进主要针对拓展性和稳定性。成果包括:使得Storm单集群可以容纳之前5倍的机器。但如果要继续改进,需要更改底层的设计和实现,代价很高,不亚于重新设计实现一个实时计算框架。
我们也考察过业界流行的开源方案和商业方案。当时业界最流行的就是Storm。而其他框架并不能很好地满足我们在扩展性、吞吐量和延迟方面的需求。而且,其它系统也不兼容Storm的API,需要重写所有实时计算任务,这样一来,迁移成本会大大增加。业界也没有很好的适合Twitter这种实时流量巨大的商业方案。
最后我们决定,基于之前的经验和当前的需求,重新设计实现一个兼容Storm API的实时计算框架Heron。
二、实践过程
以下是Heron的主要设计目标:
● 资源隔离 – 实时计算任务中的每一个节点和计算单元,应该确保能够使用且只使用它们分配的那些资源。这使得Heron在共享的基础设施上也保证资源分配以及资源隔离。
● 兼容性 – Heron与Apache Storm的API和数据模型是完全兼容的,降低在两个系统的迁移成本。
● 场景保证–Heron支持at-most-once,at-least-once,exactly-once等场景。并且在各种语义下,也可以通过不同的配置实现不同的取舍,如在exactly-once的场景下,可以通过配置选择低开销但恢复时间长、高开销但恢复时间短以及混合模式。
● 性能 – 许多Heron的设计选择使得Heron获得了比Storm更高的吞吐量和更低的延迟,同时还提供了增强的可配置性来微调可能的延迟/吞吐量的折中。
● 效率 – Heron的构建目标是以最小的资源使用量达到上述所有目标。
● 提供新的功能,如反压机制 – 在Heron这类分布式系统中,不能保证所有的系统组件以相同的速度执行。Heron有内置的反压机制来确保拓扑在组件缓慢的情况下可以自适应。
Heron的整体架构如图1和图2。用户可以使用Storm API来实现topologies,并提交给资源调度器。资源调度器将一个topology按照打包算法(Packing Algorithm)分拆成多个容器来运行:其中一个容器运行Topology master,负责管理topology;剩余的每个容器都会运行,一个流管理器(stream manager)负责数据路由、一个指标管理器(metrics manager)用来搜集和报告各种指标;多个 Heron instances(运行user-defined spout/bolt代码)进程;以及其他守护进程。资源调度器会自动根据集群的可用资源来调度各个容器。此外,我们使用Zookeeper来同步Topology的元数据。

图1:Heron架构
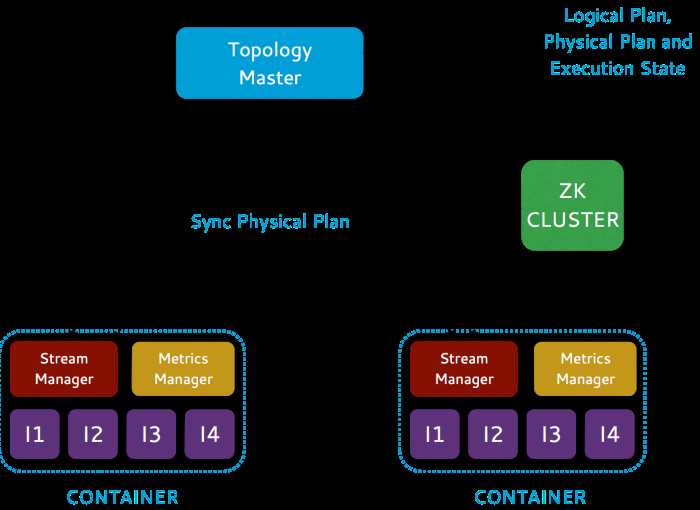
图2:拓扑架构
2.1 Topology(拓扑)运行时组件
Heron Topology运行时包括以下组件:
– Topology Master
– Stream Manager
– Heron Instance
– Metrics Manager
Topology Master
Topology Master(TM) 管理Topology的整个生命周期,从提交直到最终被杀死。当Heron部署一个Topology时,它启动了一个TM和多个containers。这个TM创建了一个唯一的临时ZooKeeper节点使得其可以被其他容器发现;同时这个节点的唯一性也保证这个拓扑只有这一个TM。这个TM也负责构建Topology的元数据,传递给不同组件。
Stream Manager
Stream Manager(SM) 管理组件间元组的路由。一个拓扑中的每个Heron实例连接到它的本地SM,同时在一个给定的拓扑中所有的SM互相连接形成了一个网络。图3是SM网络的图示:
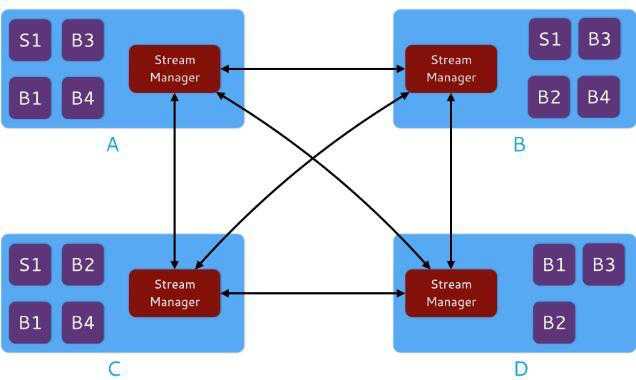
图3 SM网络图示
除了作为数据流的路由引擎外,SM还负责在需要时在拓扑中实现反压机制。图4是反压的图示:
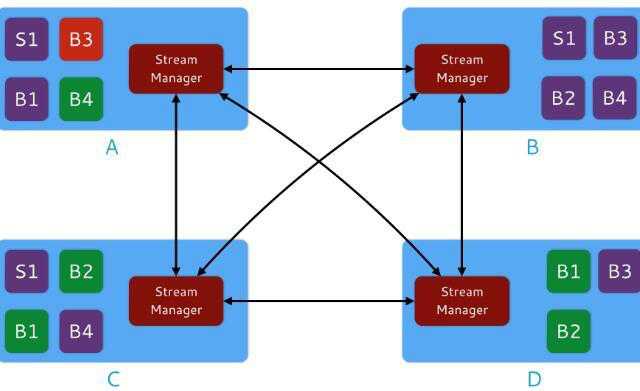
图4 反压图示
上图中,假定bolt B3(在container A中)所有输入都来自spout S1。B3比其他组件运行更慢。结果是:container A的SM会拒绝来自容器C和D的输入,因为那样会导致那些容器的缓冲溢出,进而导致进程崩溃。
在这种情况下,Heron的反压机制起效。容器A中的SM会向其他所有SM发送一条消息,通知数据源头减小数据流量。如图5。
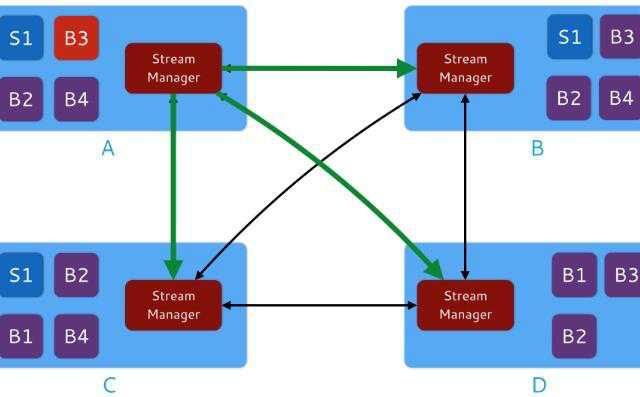
图5 Heron的反压机制起效
一旦落后的bolt(B3)恢复正常,容器A的SM会通知其他SM,这个Toplogy的流路由就会恢复正常。
Heron Instance
一个Heron Instance(HI)是处理独立spout或bolt任务的进程,支持简单的调试和分析。目前,Heron只支持Java,所以所有HI都是JVM进程,但是未来会改变。
Metrics Manager
每个拓扑运行一个Metrics Manager(MM),用于收集和导出一个container中所有组件的运行参数指标。然后把这些运行参数指标度量发给Topology Master和或者其他指标收集器,如Scribe, Graphite,等等。
我们也允许用户可以实现自己的指标收集器(Metrics Sink),使Heron支持其他系统。
2.2 Heron特色:
● Off the shelf scheduler
我们对业界流行的资源调度器进行了抽象,使得Heron可以轻松地运行在现有的各种资源调度框架上,如:Mesos、YARN、Docker等等。这样可以利用先有的资源调度框架而不需专门为Heron部署一个集群,大大降低了部署和维护的成本。
● Handling spikes and congestion
Heron 具有反压机制,即在执行时的一个topology中动态地调整数据流,使得当任务上下流处理速度不一致的情况下,仍能够很好地运行,不丢失数据保证分析结果正确性。这在流量峰值和管道堵塞时非常有用。
● Easy debugging
每个任务是进程级隔离的,从而很容易理解行为、性能和文件配置。此外,Heron内置如图6所示的UI,可自动展示相应参数,便于快速和有效地排除故障问题,显示逻辑计划、物理计划和多种实时运行参数指标。
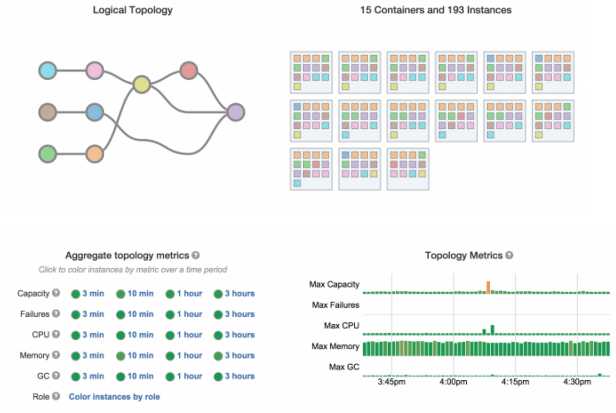
图6:Heron UI
● Compatibility with Storm
Heron提供了完全兼容Storm的特性,无需再为新系统花太多的时间和资源进行调研。另外,不要更改任何代码就可在Heron中运行现有的Storm topologies,实现轻松地迁移。
● Scalability and latency
Heron能够处理大规模的topologies,且满足高吞吐量和低延迟的要求。此外,该系统可以处理大量的topologies。
2.3 Heron性能
比较Heron和Storm,样本流是150,000个单词,如图7所示:
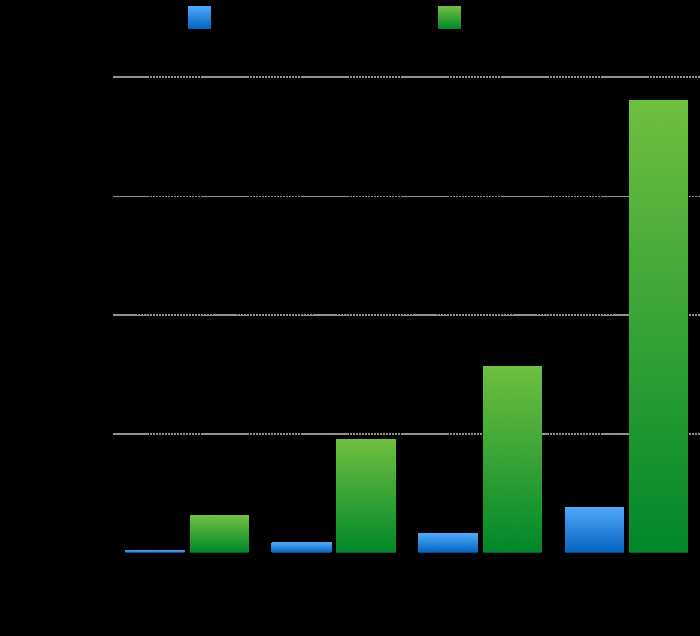
图7. Throughput with acks enabled
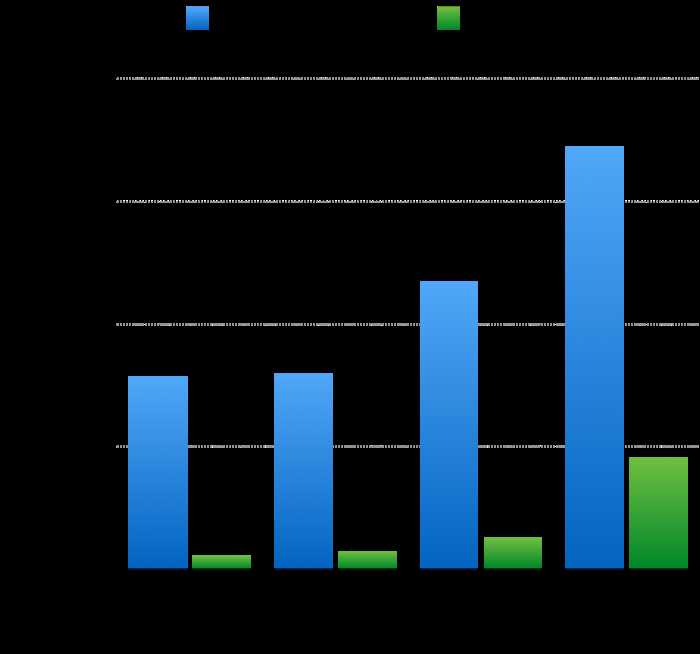
图8. Latency with acks enabled
如图7所示,Heron和Storm的吞吐量呈现线性增长的趋势。然而在所有的实验中,Heron吞吐量比Storm高10–14倍。同样在端至端延迟方面,如图8所示,两者都在增加,可Heron延迟比Storm低5–15倍。
除此之外,Twitter已经运行topologies的规模大概是数百台的机器,其中许多实现了每秒产生数百万次事件的资源处理,完全没有问题。有了 Heron,众多topologies的每秒集群数据可达到亚秒级延迟。在这些案例中,Heron实现目标的资源消耗能够比Storm更低。
2.4 Heron at Twitter
在Twitter,Heron作为主要的流媒体系统,运行数以百万计的开发和生产topologies。由于Heron可高效使用资源,在迁移Twitter所有的topologies后,整体硬件减少了3倍,导致Twitter的基础设置效率有了显著的提升。
更多TOP100案例信息及日程请前往[官网]查阅。包含产品、团队、架构、运维、大数据、人工智能等多个技术专场,4天时间集中分享2017年国内外最值得学习的100个研发案例实践。本平台共送出10张开幕式单天免费体验票,数量有限,先到先得。免费体验票申请入口
以上是关于TOP100summit:分享实录Twitter 新一代实时计算平台Heron的主要内容,如果未能解决你的问题,请参考以下文章
TOP100summit:分享实录-美团点评 业务快速升级发展背后的系统架构演进
TOP100summit:分享实录-QQ空间10亿级直播背后的技术优化
TOP100summit 2017:案例分享魅族持续交付平台建设实践
TOP100summit 2017:投资千亿成立达摩院,揭秘阿里在人工智能领域的探索