TOP100summit 2017:亚马逊Echo音箱能够语音识人,华人工程师揭秘设计原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TOP100summit 2017:亚马逊Echo音箱能够语音识人,华人工程师揭秘设计原理相关的知识,希望对你有一定的参考价值。
本文编辑:Cynthia
2017年,人工智能的消费产品落地聚焦在了智能音箱上,谷歌、亚马逊纷纷推出智能音箱产品,国内的阿里巴巴推出天猫精灵,小米推出小米AI音箱。智能音箱通过语音可以发出指令,未来可能成为智能家居的入口,通过语音控制家里的其他智能设备。

几个月前谷歌的语音识别应用推出支持个性化语音识别功能,而本周三,也就是10月11日,亚马逊的Echo音箱也具备了这项功能。
当不同的人对着音箱说话时,可以自动识别身份,提供比如个人专属的音乐播放列表、个性化购物等功能。总之,可以通过声音来识别人,让语音控制更进一步。
亚马逊Echo音箱背后是亚马逊的Alexa智能语音技术,陈亚是一位华人工程师,是亚马逊Alexa机器学习团队的资深工程师,负责语音识别、语义理解模型的搭建及优化。关于Alexa的技术内涵壹佰案例特意与陈亚进行了交流。
语音识人的技术原理
如果在很多人的空间里,让Alexa知道是谁在说话,使用的是铆钉语音检测的思路,开始通过Alexa来唤醒系统,使用一个RNN从中提取锚定嵌入,记录语音特征,接下来用另一个RNN从后续的请求语句中提取语音特征,基于此得到一个端点决策。
陈亚介绍,Alexa是首个通过语音指令驱动的AI语音助理软件,只需要呼叫“Aleca”,就可以对已经连接数百个应用的Alexa下达工作指令,比如播放音乐、查找资料、启动其他智能设备或者购物等。
现在Alexa并不只是一个语音识别工具,已经变成了一个很成熟的操作系统,未来有可能取消传统的手机屏幕,通过语音就可以进行操作。

Alexa的深度学习技术原理
Alexa的开发进行了大规模的深度学习,一个人成长到16岁耳朵听声音的时间大概只有14016小时,而Alexa的深度学习是将几千个小时的真实语音训练数据存储到S3中,使用EC2云上的分布式GPU集群来训练深度学习模型。
在训练模型方面,Alexa使用几个逼近算法减少更新规模,随着GPU线程的增加,训练速度也会加快,每一秒可以处理大约90分钟的语音。人耳16年可以听1.4万个小时的语音,而Alexa使用3小时就可以完成。
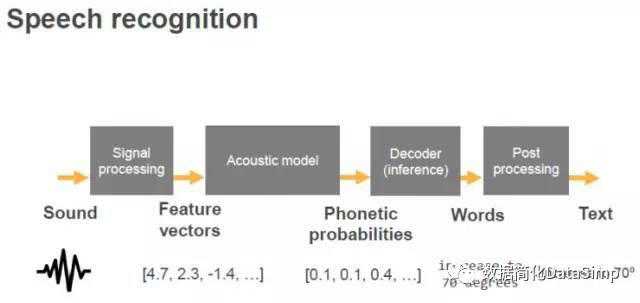
Alexa的语音识别系统主要包括信号处理、声学模型、解码器以及后处理等4大模块,首先将收集的声音进行信号处理,再将语音信号转化到频域,从10毫秒的语音中提取特征向量提供给声学模型,声学模型负责把音频分成不同的音素,解码器可以得出概率最高的一串词串,经过后处理把单词组合成容易读取的文本。
Alexa与其他语音识别应用的优势
陈亚介绍到,Alexa之所以能够占据终端市场70%的市场份额,是因为亚马逊客户至上的文化信仰。Alexa能够取得成功,是因为从产品设计到开发管理模式等方面都坚持客户至上的原则,进行用户体验革新,降低智能家居门槛,建立Alexa生态。
即将在11月9日开幕的第六届TOP100全球软件案例研究峰会上,陈亚将以分享嘉宾的身份出席,从产品设计的角度分享亚马逊用户至上理念引导的产品设计思路,以及亚马逊对人工智能和机器学习的探索经验。

更多TOP100案例信息及日程请前往[官网]查阅。4天时间集中分享2017年最值得学习的100个研发案例实践。本平台共送出10张开幕式单天免费体验票,数量有限,先到先得。
以上是关于TOP100summit 2017:亚马逊Echo音箱能够语音识人,华人工程师揭秘设计原理的主要内容,如果未能解决你的问题,请参考以下文章
TOP100summit 2017:投资千亿成立达摩院,揭秘阿里在人工智能领域的探索
TOP100summit2017:豆瓣耿新跃---站在公司整体目标下看技术管理
TOP100summit2017:网易云通信与视频CTO赵加雨:外力推动下系统架构的4个变化趋势
TOP100summit2017:网易测试总监钱蓓蕾——新时代测试正走向精英化自动化智能化