TOP100summit 2017:案例分享魅族持续交付平台建设实践
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TOP100summit 2017:案例分享魅族持续交付平台建设实践相关的知识,希望对你有一定的参考价值。

本篇文章内容来自第10期魅族开放日魅族运维架构师林钟洪的现场分享。
编辑:Cynthia
一、自动化建设历程
1.1 魅族互联网发展的时间线
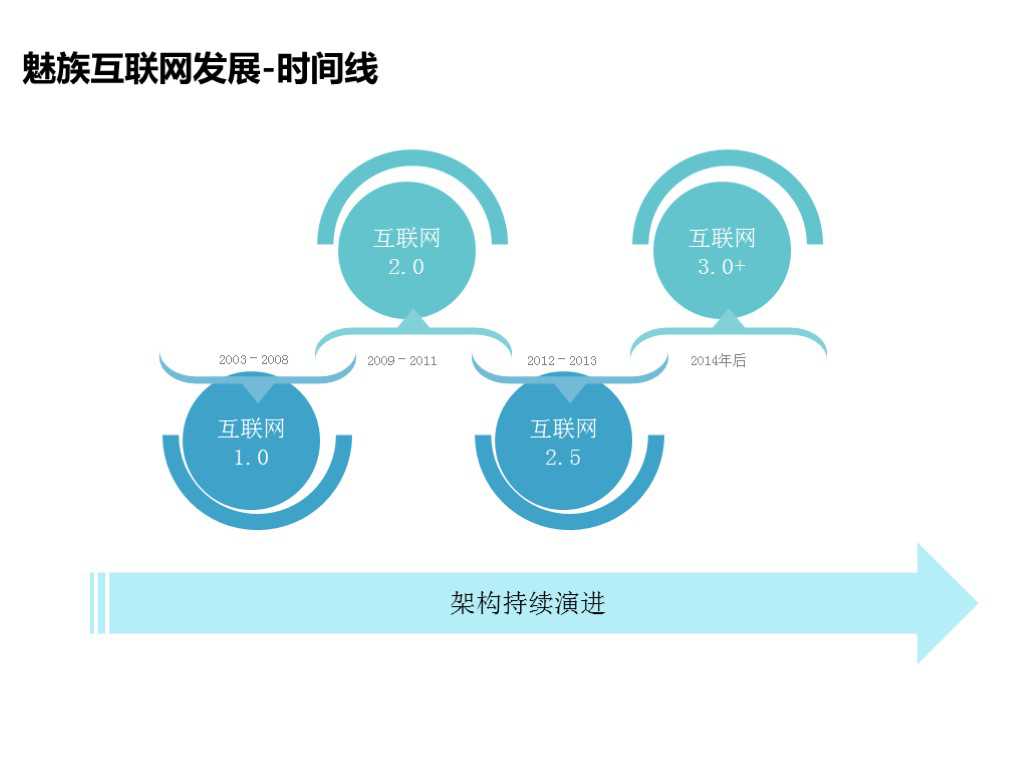
2003-2008年被称之为“互联网1.0时代”。2003年,源于对音乐的梦想,魅族成立。2006年,魅族成为中国音乐播放器第一品牌,主营业务是MP3,当时其互联网业务只有官网和BBS,这部分业务单个IDC就搞定了。
2009-2011年被称之为“互联网2.0时代”。2008年,魅族发布M8智能手机,并将业务从音乐播放器转移到手机业务上,互联网业务除了原来的官网和BBS之外,还增加了云端服务。从这个时候起,魅族有了真正意义上的开发、运维。数据库也有了主从的拷贝,但业务运行还是在单个IDC上。
2012-2013年被称之为“互联网2.5时代”。2011年魅族发布M9手机,开始进军安卓平台,互联网主要功能是对手机部件的更新和应用迭代。互联网业务扩展到官网、BBS以外的电商、微博、微信等活动,架构方面有了数据库的分布、分表、路由,缓存上有了Redis集群,以及分布式存储MFS。
2014年以后进入“互联网3.0+时代”。我们的主要业务有游戏中心、应用中心、多媒体、O2O等。这个时期有一个比较重要的标识:魅族互联网业务成为主营业务之一。
1.2 发展给运维带来的挑战
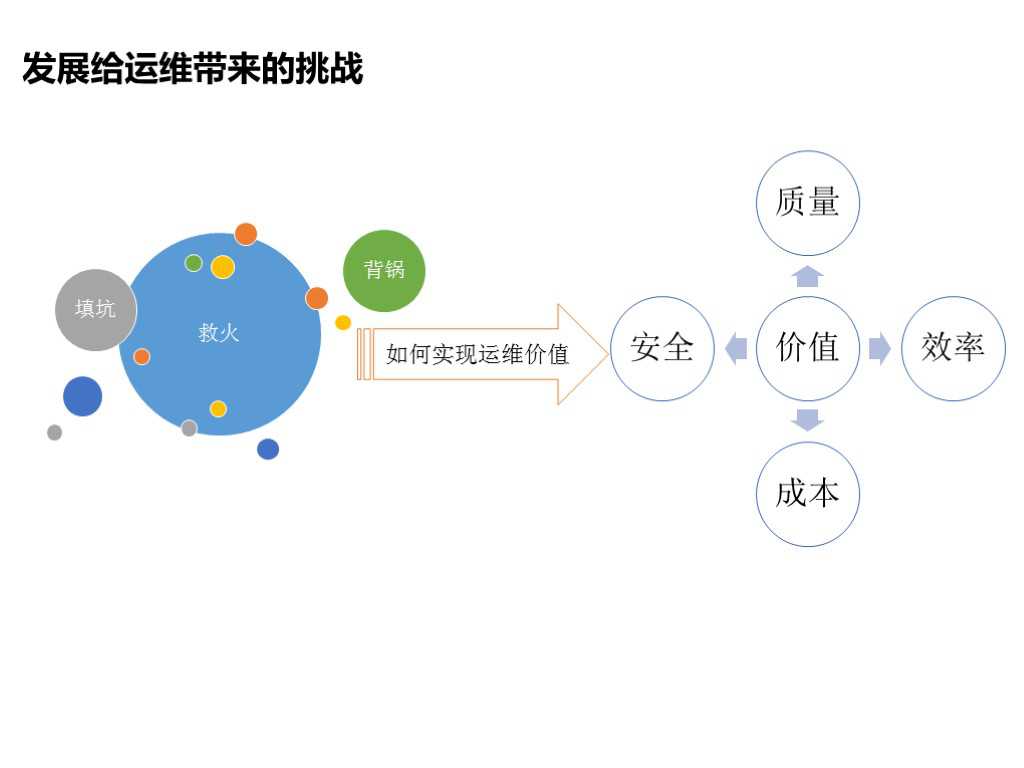
随着互联网1.0-3.0的演变,我们的业务也在快速增长。业务的急速增长给运维带来了许多挑战。
● 质量上:我们踩过很多坑,包括硬件和架构方面。业务可用性低,监控体系不完善,监控混乱,覆盖率低,经常出现漏报、误报、错报,监控变的不可信。
● 效率上:变更多,交付多,没有把流程和自动化结合起来,效率低下。
● 成本上:工作不透明,没有一个容量评估体系来帮助我们评估每一个业务需要多少容量。
● 在这种情况下,运维填坑、救火、背锅是常事。
如何实现运维价值,改变这种现状成为首要目标。我们实践主要从效率、安全、质量和成本四个方面来体现。
● 质量方面最好的体现方式就是可用性。可用性指标很多,有直接的和间接的:直接的从监控上可以得到系统可用性、服务可用性、应用程序可用性等;间接的可以对标一些体验性指标,比如速度,也可以对标一些业务上的指标,比如手机短信到达率。
● 效率方面主要是服务器的交付、线上的变更,以及积极发现故障等。
● 成本方面是主要针对业务整体的调度和交付能力进行优化改进。
● 安全是互联网重要的基石,在安全方面我们定制了一些策略和规范。
对应这四个维度,我们有四个支撑团队:质量方面有运维优化团队、效率方面有运维开发团队、成本方面有运维基础团队、安全方面有运维安全团队。
1.3运维平台现状
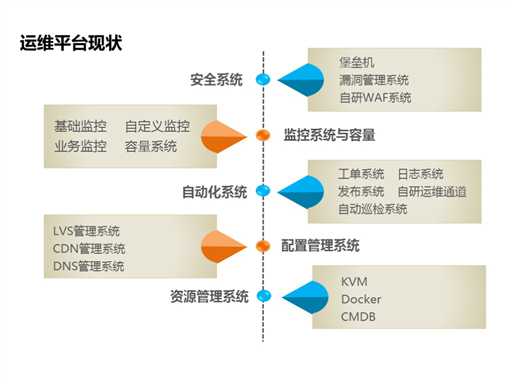
同时我们也开发了一些系统,从功能上来看有资源管理系统、配置管理系统、自动化系统、监控系统与容量和安全系统。如图所示。
● 资源管理系统,我们通过KVM、Docker建立了一个云平台,基于云平台组成虚拟计算和网络的资源管理系统,通过CMDB进行管控;
● 配置管理系统,我们建立了LVS、CDN和DNS管理系统,对应开发一些API。这样做的好处是我们可以精细化权限,集中在一个平台上做管控;
● 自动化管理系统包括工单、日志、发布系统,自研运维通道和自动巡检系统。这些都给运维的交付和变更带来了效率上的提升;
● 监控方面我们建立了基础监控、自定义监控、业务监控和容量系统。容量系统可以帮助我们评估一个业务用了多少资源、容量如何;
● 我们有一个堡垒机,所有运维登录都要在堡垒机上做一个管控,这样可以审计用户操作。我们还自研了一个可以自动发现漏洞的平台——WAF系统,能够把漏洞转化到漏洞管理平台,在上面进行迭代和修复。
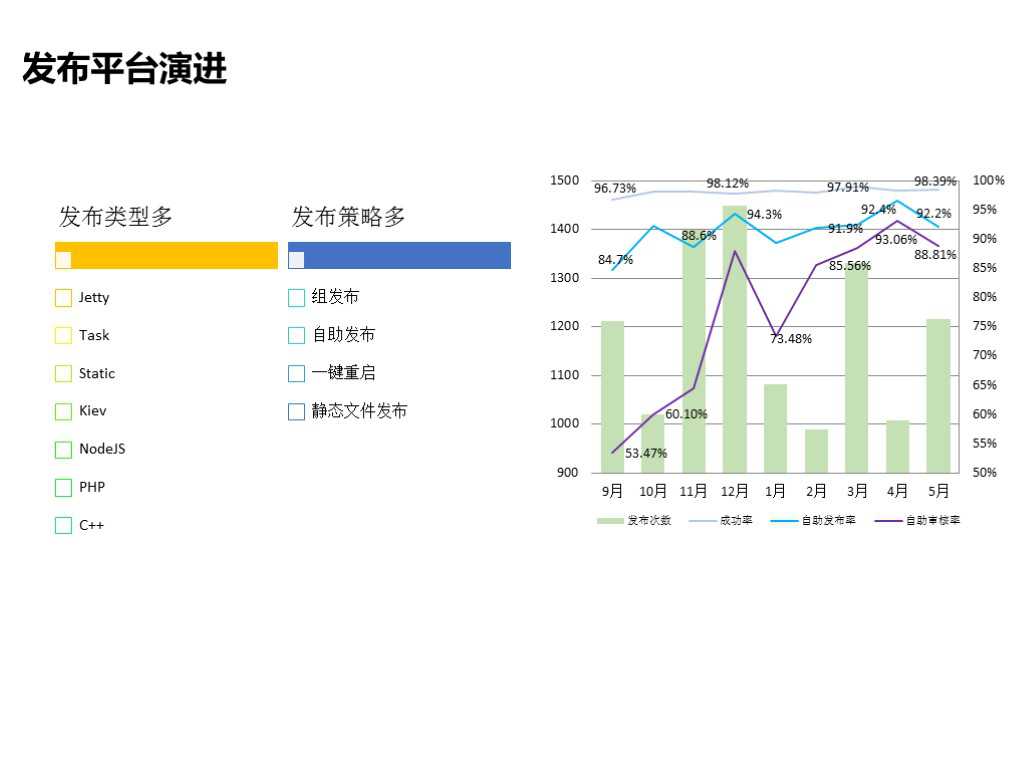
1.4 发布平台演进
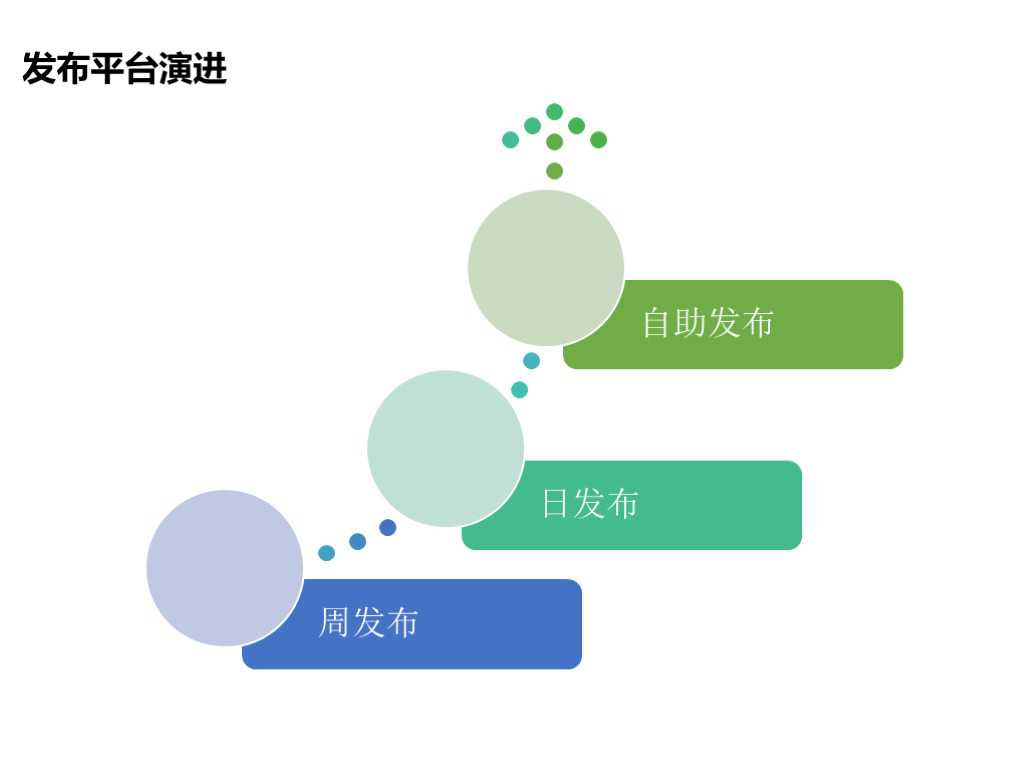
我们的发布平台经历了周发布、日发布和自主发布的发展历程。一开始我们的业务比较简单,发布是通过人力来实现的,后来业务越来越多,人力无法达到,就出现了一些自动化工具,可以向服务器下发脚本或命令、任务等。这样做可以解决一部分问题,但整体发布效率和成功率还是非常低的,而且还可能存在一些人为的误操作。
在发布平台上,我们结合业务树和业务模块做了一些规范和标准,有效地提升了发布成功率和容错性。为了使发布更加灵活,我们把审核权限下发到业务,由业务负责人进行审核,整个发布流程不再需要业务运维参与其中。
我们的发布有一些特点,比如发布策略多,有组发布、自助发布、一键重启、静态文件发布等;发布类型也很多,包括常用的Jetty、php、C++等。经过演进,我们的发布成功率一直保持在98%以上,自助发布率也在稳步上涨,可以看到大概有90%的业务在迭代发布过程中是不需要运维参与的。
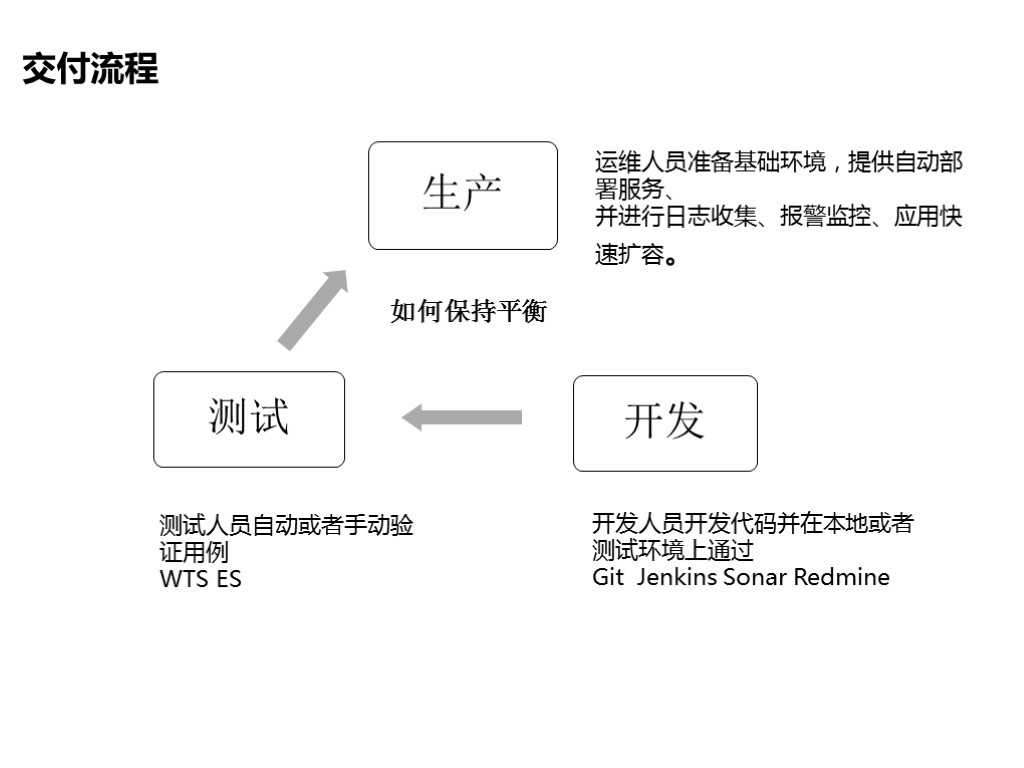
1.5 交付流程
我们的交付流程大概分为生产、测试、开发三个环境。
● 开发人员开发代码并在本地自测
● 提交代码到Git,通过 Jenkins打包,进行一些静态扫描并在redmin上填写测试单;
● 测试人员自动或者手动验证用例;
● 运维人员准备基础环境,提供自动部署服务、并进行日志收集、报警监控、应用快速扩容。
这是一个微妙的平衡,这种平衡要求我们有一套完善的技术栈和环境,团队技术框架和人员也要尽可能的稳定,这种情况下,是没有什么问题的,但是如果这个平衡被打破了,比如有一些流程没有被遵守,或者说有一些相关的人员离职、我们的架构变化的比较快,这个时候整个平衡就会被打破,交付变得不可完成。
1.6交付中存在的问题
交付过程中存在哪些问题呢?
首先是质量,我们通过代码的质量跟踪可以看到它有没有通过单元测试、覆盖率如何、Bug数如何;其次是效率,我们有自动化部署、自动化测试、自动化构建,但这些分布在不同的部门,没有和流程打通,这就造成第三个问题:沟通成本高,交付复杂。最后还可能有安全问题,比如代码够不够安全、有没有经过安全测试等。
1.7 我们追求的价值
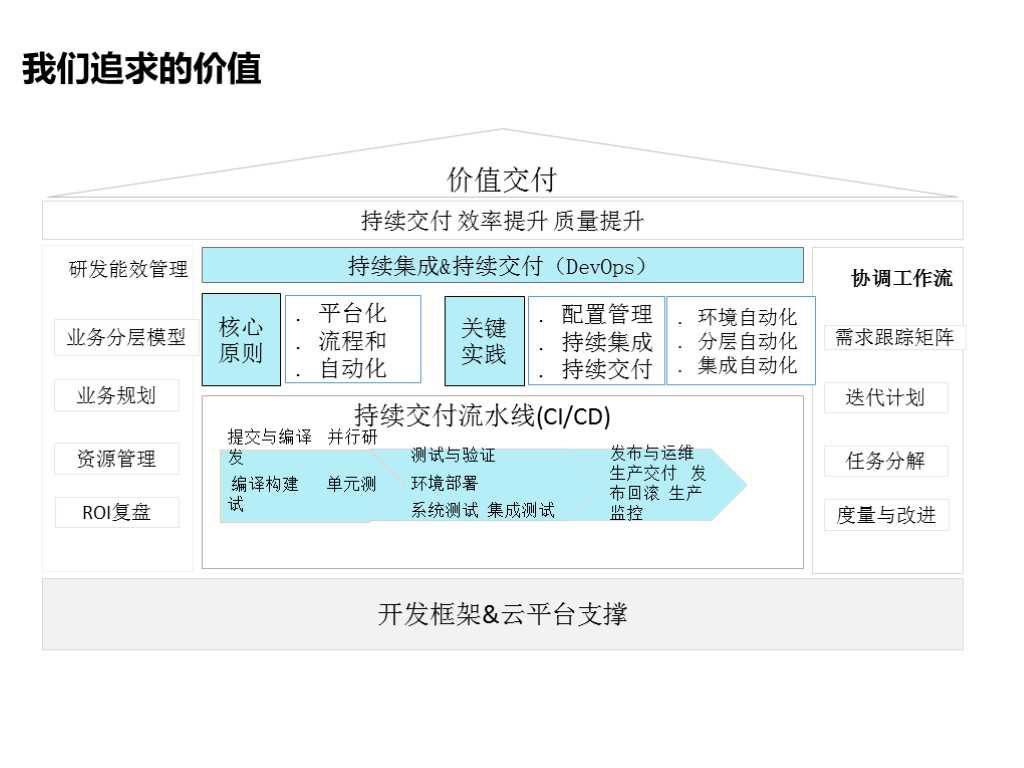
我们追求的是价值交付,这也是魅族持续交付平台建设的指引。
首先在最底层是一些开发框架,云平台能保证我们环境,保证交付所有的系统都是标准化的,
开发架构这里有技术委员会定义和推广的一系列基础服务和架构,这就保证了有一套基础的技术栈和环境自动化的流程。
持续交付流水线的核心原则是把一些标准化的流程自动化。过程当中有提测和编译阶段,有并行的研发、编译构建、单元测试;在测试与验证阶段有环境部署、系统测试、集成测试;在发布与运维阶段有生产交付、发布和生产监控等,这一系列过程都可以在这个流水线上完成。这个系统是多用户的,支持开发、运维、测试进行协调操作,这样对整个团队的协作也起到了促进作用。
二、持续交付平台
2.1 演进-标准化
自动化平台的演进分为标准化、自动化、智能运维三个阶段。
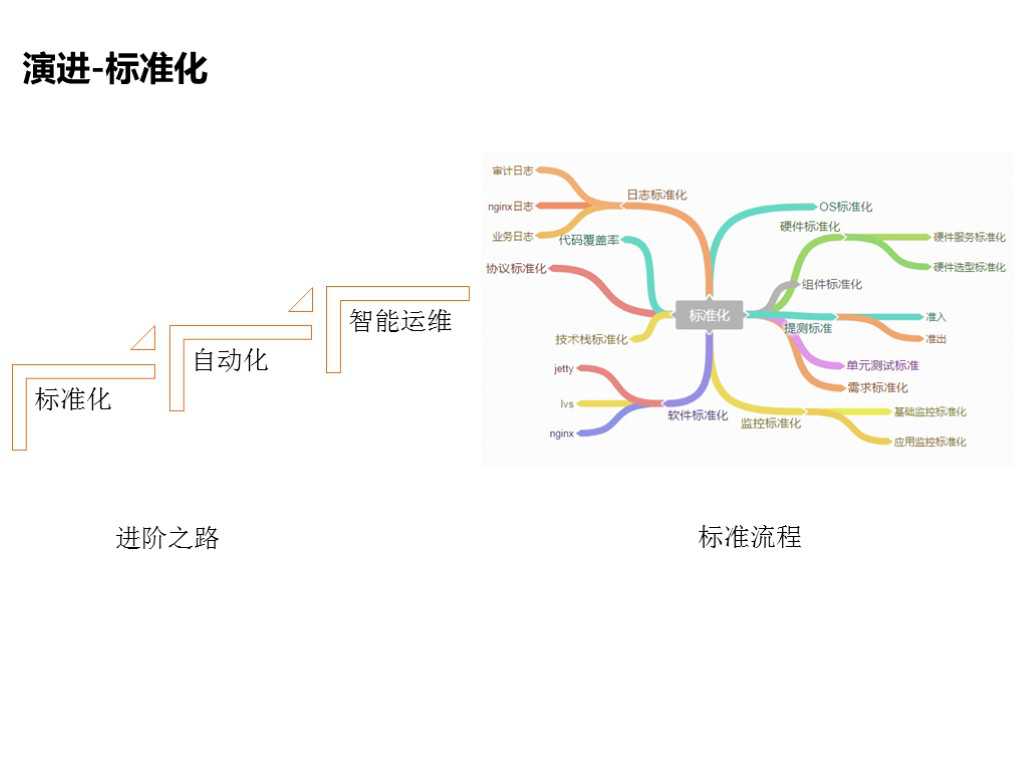
标准化方面包括监控标准化、应用监控标准化、技术栈标准化(其中用了什么协议)、硬件标准化、质量标准化等。自动化主要是测试自动化,在测试阶段包括的东西更多,比如单元测试、通过率及测试的准入准出条件(是不是允许一些bug)等。
2.2 演进-技术选型
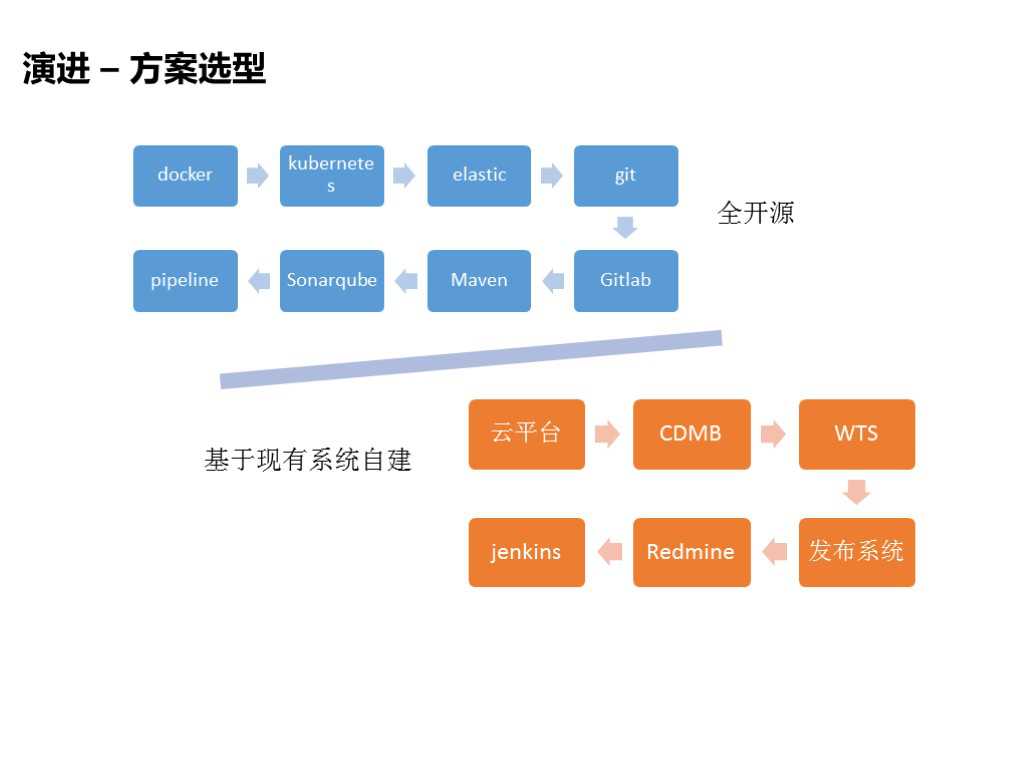
我们在建立持续交付平台的过程中有两个方案:
第一种,全开源的方案,我们可以用docker做环境自动化的标准的东西,我们的日志可以使用ES,这种方案可能对我们现有的系统的冲击比较大,我们要使用一套全新的东西。
第二种,基于现有系统自建。基于我们现有的云平台加上我们的一些发布平台这些东西进行规范和标准。
我们选择了基于现有系统自建的方案,对我们来说阻力比较大。
首先我们需要对接很多系统,这些系统分散在各个职能部门,有PMO、测试、运维等,要推动这些不同的职能部门和相关的人员做出改变,阻力是非常大的;
其次,我们现有的一些系统,在开发的时候可能用了不同的规范,像我们的运维这边发布平台可能都会有规范,比如每个机房有哪些服务器,服务器上跑了什么模块,哪些机器有生产环境,都是基于我们的业务树来运行。
但是开发这边使用的各个平台都是全开源的,比如之前使用的jekins都是全开源的,完全就没有进行改造,这个时候就会有问题,它里面的名字之类的标识完全都是自定义的,很难和我们的业务树对应起来,想改造确实是比较麻烦。
2.3 演进-统一入口
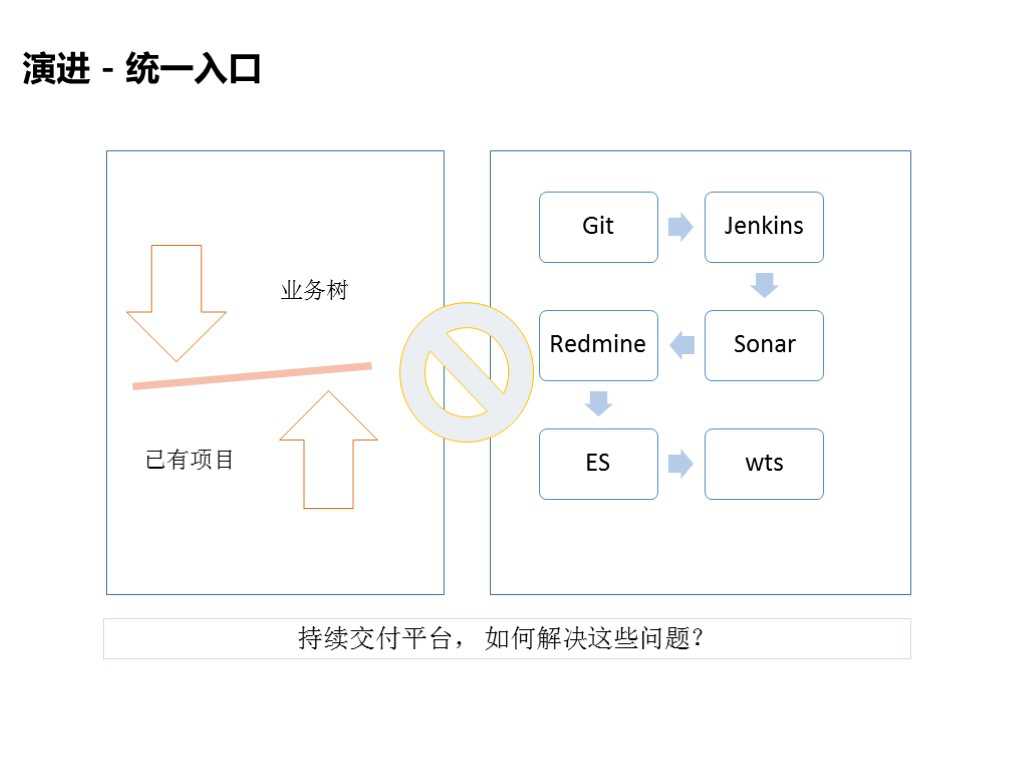
在持续平台中首先要有一个统一入口,像前面提到的Jenkins,用来打包,我们可以调用它的API,打包之后植入到系统中。
还有之前做的需求管理、bug跟踪的信息,我们会把这些信息录入到系统中,一旦得到一些信息我们就可以知道一个需求遗留吧多少个bug、修复情况如何。
另外,这是一个多用户系统,我们还要把这些系统人员同步到系统当中,把他们信息都录入进去。
2.4 持续集成流程
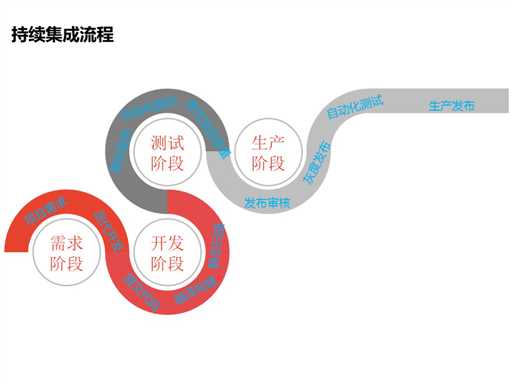
如图所示,持续集成的流程是:首先把需求列入到需求阶段,开发负责人对这些需求进行评估和预测,评估出一个迭代日期;然后进入开发阶段,开发代码,提交代码然后到编译;编译进行静态扫描,这当中包含代码的覆盖率;然后到测试阶段,把代码部署到测试环境,进行代码测试,包括安全性测试、性能测试,有时还会做一些人工验证,如果有问题流程会被打回,开发人员重新提交代码,重新走一遍准入流程,如果没有问题就进入到生产阶段;开发负责人或者运维人员进行审核,通过审核之后,会先把代码发布到灰度环境,用自动化的程序来验证它的安全性是怎么样,接口通过率怎么样,如果都没有问题才会放到生产发布。从需求到发布的阶段,整个它的工作流程或者生命周期的管理都会在这一个平台上进行管控,整个交付流程就有一个可视化的进度管理。
2.5 发布流程
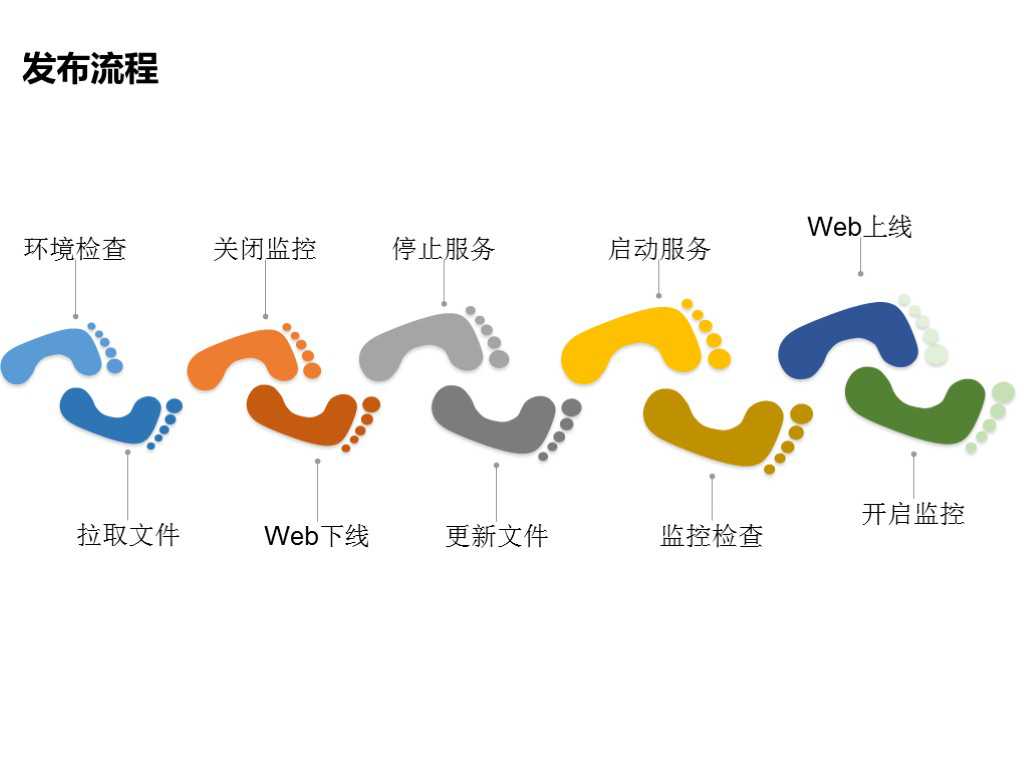
我们单独看一下发布流程,
第一步,环境监测,包括我们发布的服务器上相关的环境,比如它的用户是不是存在,目录是不是存在,还有相关的权限;
第二步,文件拉取,从打包平台拉取要发布的包;
第三步,关闭监控,我们都知道发布的时候可能会造成短暂的服务不可用,或者发布期间不会有误报,那么我们可能会针对发布的机器做一些关闭监控的操作;
第四步,web下线,保证没有流量进来;
第五步,停止服务,保证文件不被访问占用;
第六步,更新文件,对文件进行更新;
第七步,启动服务,恢复web服务;
第八步,健康检查,根据健康检测我们能确定并保证我们的服务运行正常;
第九步,web上线,健康检测以后我们会把我们的web服务加入ios集群上;
第十步,开启监控,最后总的发布就完成。
发布的时候,我们因应业务环境可使用串行发布和并行发布,这样在保证我们发布的成功率的前提下,也能提升发布效率。
2.6 产品研发模式
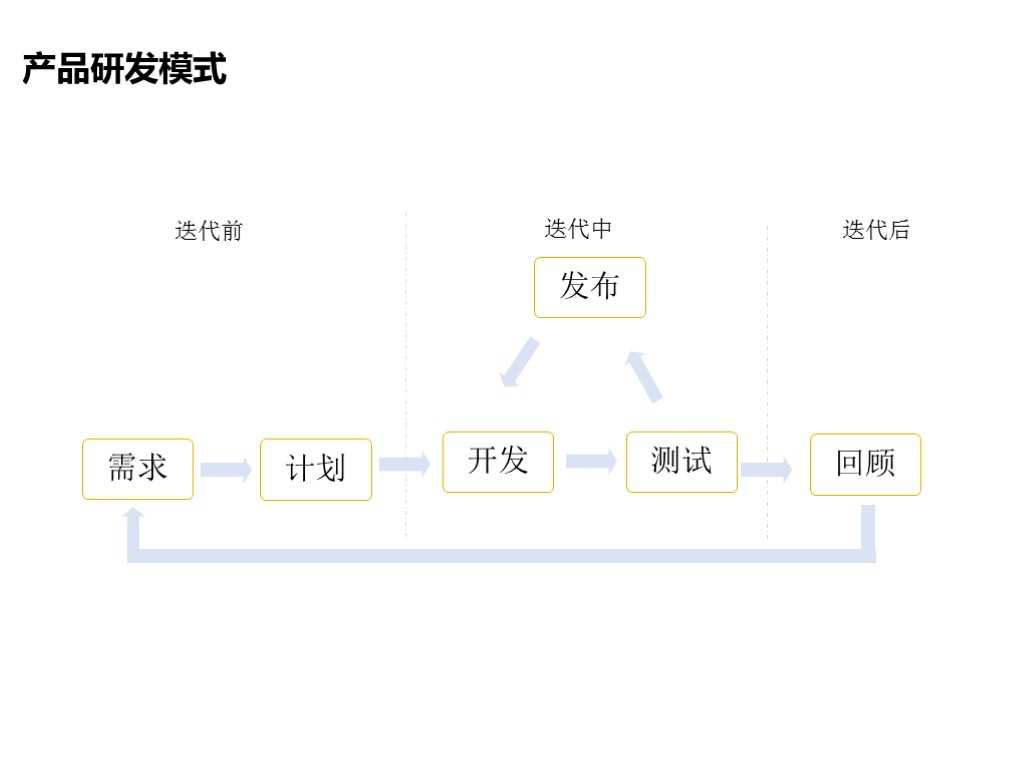
有了持续交付平台就能保证满足互联网研发的模式,比如经常被用到的极速迭代,在平台上可以满足迭代性的需求还有迭代后的回顾。
2.7 数据驱动
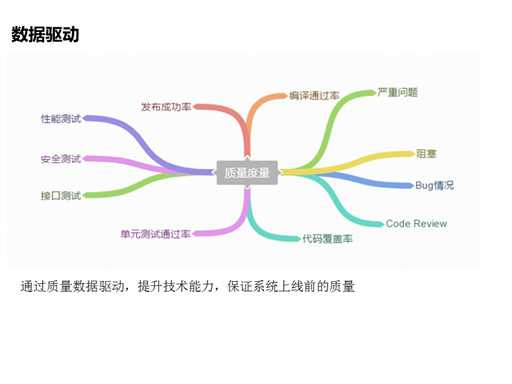
完成了这些以后我们会有价值数据的驱动和输出,首先这里会有几方面的数据,在代码的一些规范性上面,可以知道严重问题是多少、阻隔问题有多少,在代码的可读性上,有重复率,还有一些接口和单元测试,单元测试的覆盖率怎么样,通过率怎么样,还有性能测试的一些数据,安全测试的一些数据,甚至我们的人员构建的成功率之类的,还有发布的一些成功率,还有发布的效率。这样就可以知道一个项目它从开始到现在它所有的质量数据的变化,通过这些质量数据的驱动能提升技术的能力,把系统上线前质量是OK的,当然我们还可以根据这些数据来考核我们的相关的子系统。
三、展望运维智能化
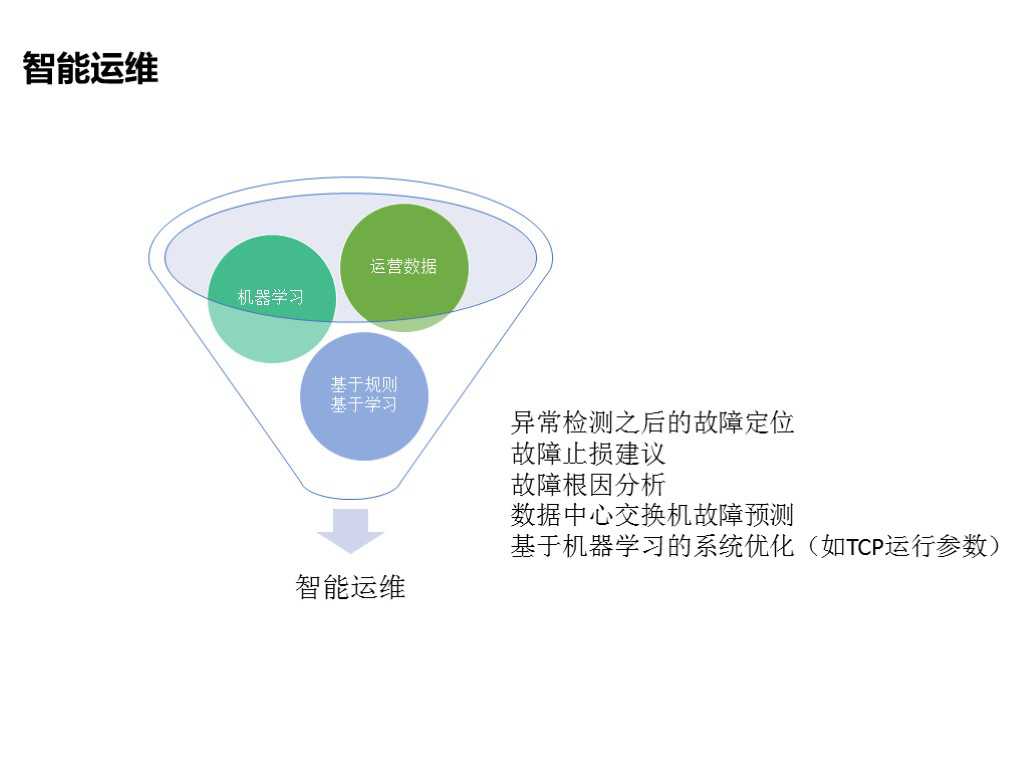
回头看一下我们平台的三个阶段,标准化、自动化、智能化,智能运维是根据收集上来的数据进行学习,从而达到预测和分析的目的。
这里我们最常见的就是预测和分析,比如根据我们的预报数据的统计说我们最近硬盘的换盘率特别高,这样是不是可以预测一下我们的数据硬盘什么时候损坏。
其次还有可以根据一些数据进行效率上的提升,比如说像故障方面,在故障的发现和定位上有一个比较有力的支持,或者达到故障预测。
还有就是数据中心的故障的预测,因为这个东西在当时肯定是全瘫痪了,那么像这种故障能否做到事前的预测,这就是我们现在要解决或者想进一步解决的一些问题。
11月9-12日,北京国家会议中心,第六届TOP100全球软件案例研究峰会,魅族科技主题桌面负责人谭林英将分享《手机厂商如何做互联网产品》。
TOP100全球软件案例研究峰会已举办六届,甄选全球软件研发优秀案例,每年参会者达上2000人次。包含产品、团队、架构、运维、大数据、人工智能等多个技术专场,现场学习谷歌、微软、腾讯、阿里、百度等一线互联网企业的最新研发实践。
更多TOP100案例信息及日程请前往官网查阅。4天时间集中分享2017年最值得学习的100个研发案例实践。本平台共送出10张开幕式单天免费体验票,数量有限,先到先得。
免费体验票申请入口:www.top100summit.com/?qd=juejin
以上是关于TOP100summit 2017:案例分享魅族持续交付平台建设实践的主要内容,如果未能解决你的问题,请参考以下文章
TOP100summit2017:豆瓣耿新跃---站在公司整体目标下看技术管理
TOP100summit:分享实录爆炸式增长的斗鱼架构平台的演进
TOP100summit:分享实录-美团点评 业务快速升级发展背后的系统架构演进
TOP100summit:分享实录-QQ空间10亿级直播背后的技术优化