TOP100summit:分享实录爆炸式增长的斗鱼架构平台的演进
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TOP100summit:分享实录爆炸式增长的斗鱼架构平台的演进相关的知识,希望对你有一定的参考价值。
本篇文章内容来自2016年TOP100summit斗鱼数据平台部总监吴瑞城的案例分享。
编辑:Cynthia
吴瑞诚:斗鱼数据平台部总监
曾先后就职于淘宝、一号店。
从0到1搭建公司大数据平台、平台规划和团队建设。
目前负责斗鱼实时/离线数据处理、个性推荐系统、BI&DW和搜索引擎。
背靠开源生态,应用短平快的方式,支撑起一个亿级用户的在线直播平台。
致力于数据平台产品化、智能化、云化。
对高可用高并发的大数据平台架构和SOA架构有深入的理解和实践。
导读:2016年是直播行业的元年,斗鱼在两年内发展成为拥有亿级用户和百万级主播的直播平台,快速增长的同时也为技术带来了高并发请求和海量数据的挑战。同时公司系统技术栈多、项目迭代周期快、系统规模呈爆炸式增长。在这种背景下,斗鱼网站的架构平台该如何进行优化,才能支撑起如此迅猛的业务发展?斗鱼的平台技术会在哪些方面持续革新?
本文详解斗鱼技术团队通过对斗鱼基础架构平台的不断改造与优化,形成当前能支撑千万级用户同时在线观看的架构平台。适用于希望了解直播平台基础架构、单体应用的服务化改造、直播平台在支撑大型赛事活动所做的准备。
一、问题的提出
斗鱼网站2014年上线至今,顺应直播行业趋势的发展,完成对交易系统、会员系统、统一登录系统、弹幕系统、任务系统的重构,并持续对架构进行优化,针对客户使用体验拆分系统、提高研发效率、强化系统稳定性和扩展性。优化主要针对以下三个方向:
● 偿还技术债--多语言技术栈交互,临时方案导致版本过多、逻辑错综复杂;
● 系统可扩展性--服务与服务、服务与资源之间解耦;
● 服务化--微服务、服务治理、容器化。
二、实践过程
2.1 斗鱼架构平台整体介绍
2015年初,斗鱼网站系统架构主要分为两大功能模块:Web站和移动端,这两大模块最初是从网站的单个工程中拆分出来的,是一个典型意义上的单体应用,也就是Martin Fowler指的monolithic application,这样的系统主要有以下问题:
● 各个业务模块错综复杂,代码复用率低,临时方案和功能开关多,导致代码可维护性较差;
● 功能开发效率较低,容易踩坑,容易伤士气;
● 网站健壮性较差。
斗鱼去年(2015年)系统架构如图1所示:
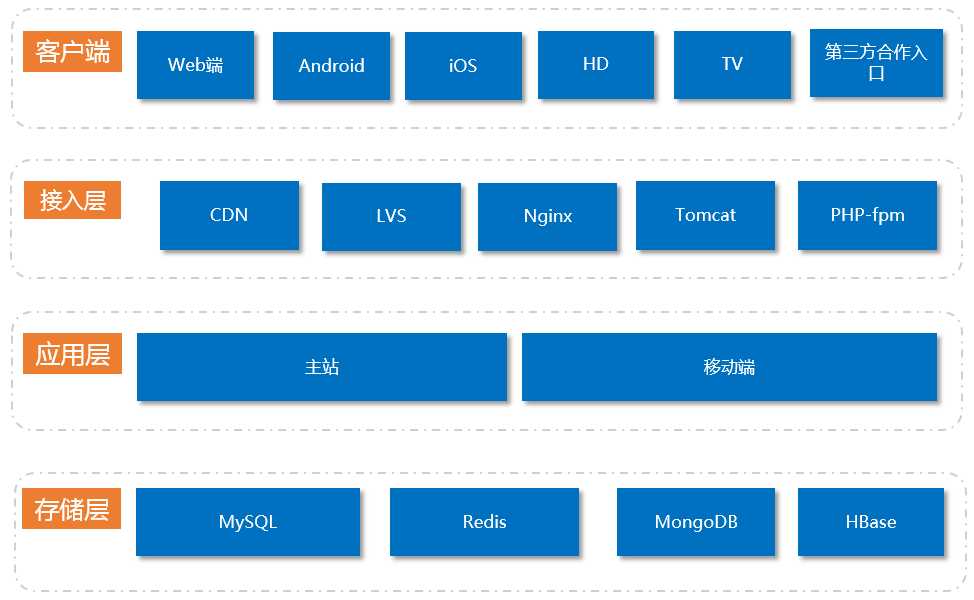
图1:斗鱼2015年系统架构
这个阶段的系统会存在诸多瓶颈,随着网站用户量的激增,斗鱼全站的DAU超过2000万,整体架构的服务化改造刻不容缓。
在原应用层中,剥离业务逻辑,只负责应用的流量接入,具体的业务逻辑将由服务层承担;在服务层中,按照业务功能,完成会员系统、房间系统、交易系统、个性推荐服务、弹幕系统、礼物系统等多个功能单元服务改造。
这样就形成了当前的系统架构(图2):
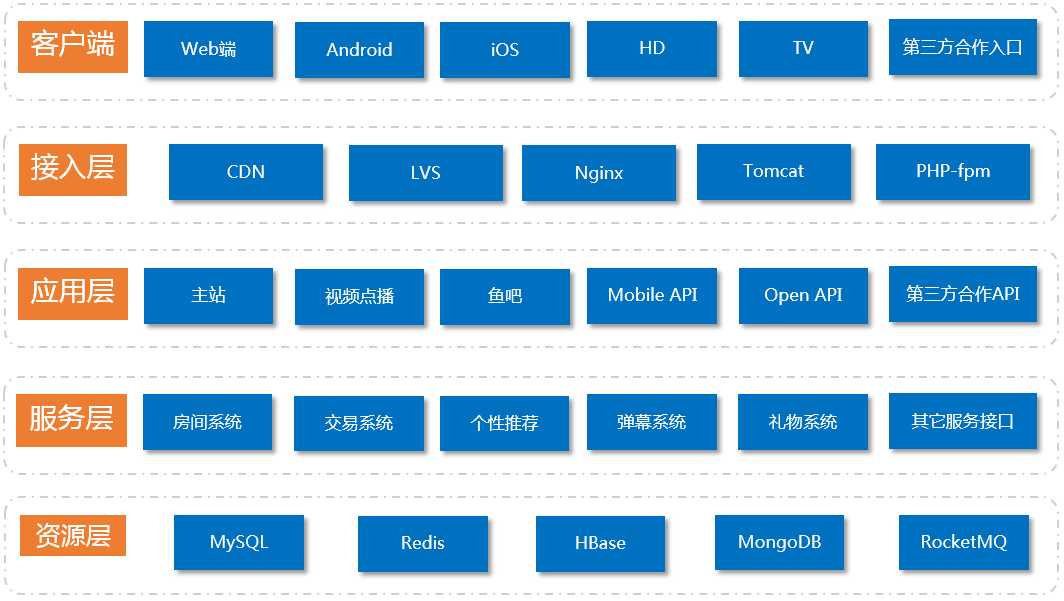
图二:斗鱼当前(2016.12)系统架构
在大型活动赛事时,每个功能单元的逻辑复杂度、承担的访问量差别巨大,为了能扛住活动期间的峰值,需要对各个功能单元进行容量预估和扩容,这样会直接验证服务化改造的效果。
2.2 斗鱼配置中心
整个服务化进程中,会需要多个核心的基础组件,先介绍一个核心组件——我们最先启动的配置中心。
在没有配置中心时的状态是这样:
● 配置散落在各工程中,盘根错节,配置改动成本大;
● Dev、Test、Stg、Prod多套配置;
● 资源环境安全隐患;
● 无法进行服务降级。
梳理出配置中心的痛点,列出配置中心的基本目标是:
● 统一维护配置,方便新增及更改配置;
● 多套环境配置隔离。
围绕这个目标,通过两个版本的迭代,实现了以下特性:
● 动态配置 ——自动拉取、手动更新、对象动态重构
● 高可用——mysql主从、本地加密Snapshot
● 数据源——MySQL、Redis、MongoDB等
● 集群配置——Kafka、HBase、Zookeeper、ES等
● 配置项可继承
此外,对于中小公司,安全隐患不容乐观,所以出于安全策略的考量,还实现了:
● 配置中心秘钥安全认证
● 配置服务添加IP白名单
● 配置服务访问频率
在设计阶段,针对已开源的Diamond(淘宝)和Disconf(百度),主要从配置存储、推拉模型、配置读写、容灾模式、安全性、配置、数据模型、集群数据同步方面做了详细对比,对比发现两套开源系统涉及技术栈较多、二次开发成本较大,与现有系统集成的风险较大。
加之,配置中心并不复杂,风险可控,并且自研的优势还有人员培养,自身对系统全貌能做到足够熟悉,后续新增功能特性和日常维护比较得心应手。事实证明,自研的选择完全符合设计阶段的预期。
配置中心架构如图3:
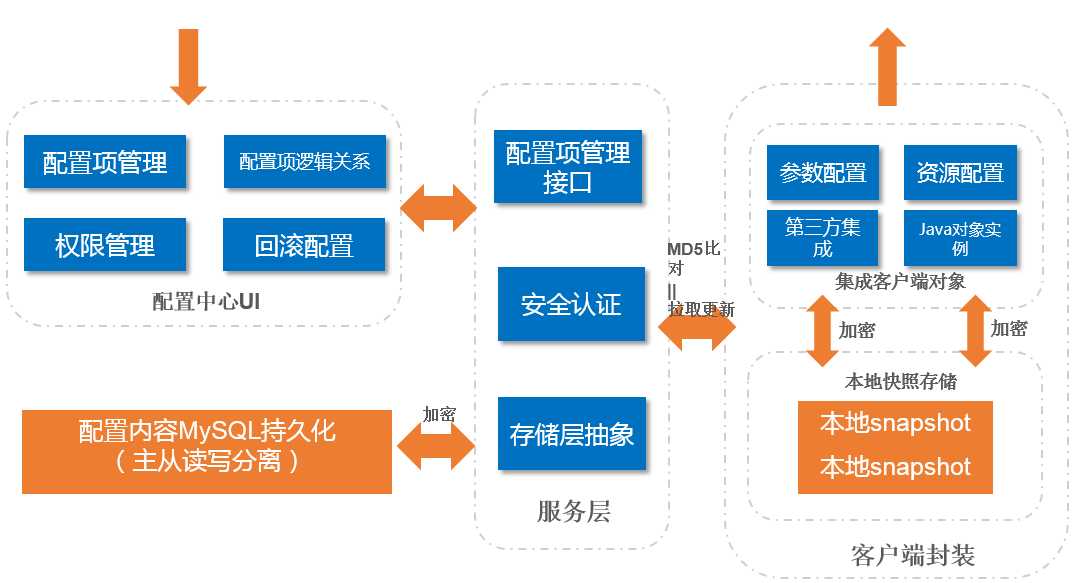
图3:配置中心系统架构
整个配置中心主要分为四大部分:
● 配置中心UI:配置项内容维护、配置项权限管理、配置项逻辑关系(继承);
● 服务层:配置服务接口、安全认证、配置项持久化;
● 存储层:配置内存通过MySQL主从存储,中间有通过Redis实现缓存;
● 客户端:应用本地保存配置snapshot加密文件,提升安全性和可用性,通过配置项MD5比对判断是否更新,拉取配置后动态更新本地对象实例。
在应用代码中,只需以下代码即可集成配置中心:
PropertiesConfigClient configClient = new
PropertiesConfigClient(
live/prod, //配置组
project, //配置所属工程
config-file, //配置文件
refresh-interval); //更新频率
configClient.getRequiredInt("data.query.page.size");//需使用配置项
当前,配置中心迭代中的版本主要是抽象资源类型,这样可以通过配置中心识别出服务依赖的资源,包括接口、缓存、存储等,并在此基础上做服务依赖的全监控。
对于配置项修改后的实时推送特性,拉取模式现阶段够用,暂时还没有改造需求。如果需要新增,可以集成Zookeeper,通过Zookeeper的事件推送机制,并配合改造配置中心客户端的接收模式即可实现。
2.3 斗鱼统一日志监控系统
有了配置中心,可以以此实现服务的开关和降级。但是在赛事活动期间,除了配置中心,还需要监控系统来识别系统状态。
为什么需要做统一日志监控系统?初衷包括:
● 技术语言多样、临时方案导致版本过多、逻辑错综复杂;
● 服务层级不多,但是量大,接口失败后如何快速定位;
● 开源组件二次开发能力弱;
● 需要短平快的实现方式。
梳理出了最关心的监控指标,主要包括:
● 接口访问量监控
● HTTP 500监控
● 接口响应时间监控
● 视频流监控
● 系统错误日志监控
● 资源层监控
● 服务器性能监控
梳理过程中,我们发现:
● 接口访问量监控、HTTP 500监控、接口响应时间监控、视频流监控可以通过nginx或者Web Server的log取到;
● 系统错误日志监控能通过应用日志取到;
● 资源层监控和服务器性能监控可以通过Zabbix监控实现。
方案设计阶段,主要对比了以下两个方案:
● 日志分段处理方案:在日志本地按时间区间分段切分日志文件,通过rsync将分段日志汇总,解析并做聚合计算,结果导入MySQL或者Redis,日志内容导入HBase,供查询定位。
● ELK(Elastic Search+Logstash+Kibana)方案:通过Logstash(日志收集Agent)tail抽取方式收集日志,写到ES(Elastic Search,以下简称ES)集群,然后通过Kibana来查询日志。
参与方案设计的同事倾向日志分段处理方案,主要是对各个组件都较熟悉,每一步都可控。但是考虑到实时性得不到保证,并且开发成本高,所以决定搭测试环境小范围试用,最后发现ELK绝对神器。
当前监控系统架构图如图4:
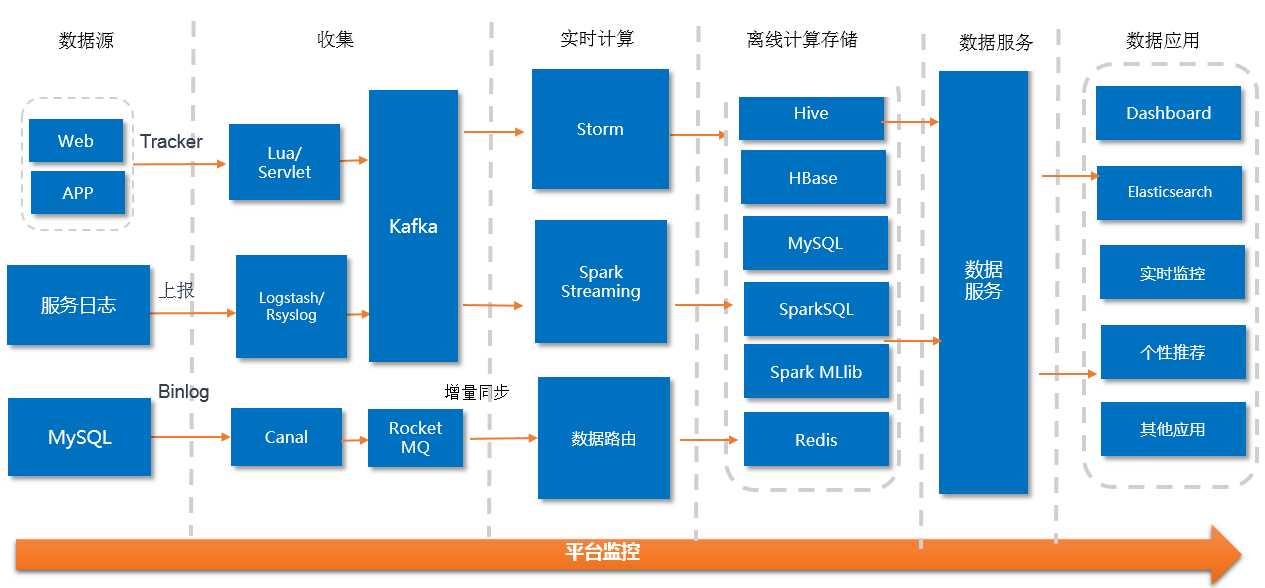
图4:监控系统架构图
从架构图中可以看到关于统一日志监控系统相关的数据流,对于CPU敏感的日志宿主机,使用Rsyslog作为Agent来实现日志收集。并且,在Agent中精简任务,只做最简单的日志抽取。快速写入到Kafka集群中。日志数据从Kafka出来后有两路去向:一路是经由日志内容解析,按照ES的index mapping解析日志,然后写入ES集群;一路经过实时计算系统(基于Storm实现),做聚合计算,得到指定粒度Metric的值,同样写入ES,需要在Dashboard中展示的指标会写入Redis。
基于ELK,通过在基础中间件中改造AOP日志的格式,还实现了满足基本功能的全调用链监控,具体的AOP日志格式如图5:
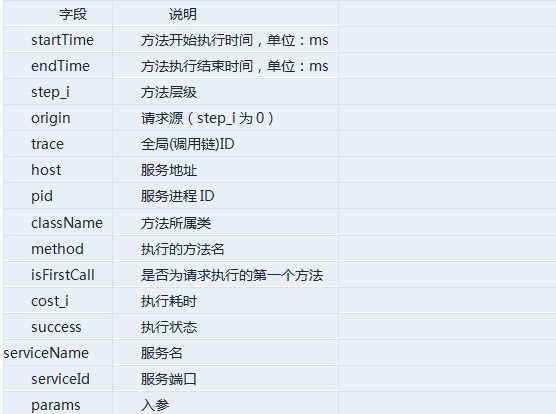
图5 AOP日志格式
这套日志格式主要是参考Google 的Dapper论文,关键是trace_id(全局唯一的方法调用ID,通常特定规则生成的UUID)和span_id(方法调用的层级ID),通过这两个ID串联起整个RPC调用链。在日志中记录RPC相关的所有方法调用信息,包括服务名;方法开始时间和结束时间,用以计算方法耗时;方便定位服务进程的host、pid和服务端口;定位问题时需要的入参。没有记录出参的主要原因是出参过大,并且通过入参中的业务字段,能定位是在哪一级出的问题,现阶段够用。
关于ELK的一些使用经验主要有:
● ELK vs. TSDB
日志系统最初Metric存储是使用的基于OpenTSDB实现的一套存储展现系统,后来在OpenTSDB的使用中碰到一些问题,例如HBase资源冲突、数据压缩、区间查询精度等问题,另一方面ES的使用足够省心,后来Metric存储也逐渐以ES为主。
● 日志内容的解析
最开始是在Agent中实现,tail抽取后逐条解析,这样会大大降低日志的抽取效率。接入Kafka中间层后,改由使用Logstash从Kafka中读取并解析,Logstash内部存在CPU效率低的问题,再改用Hangout(携程开源的Java版Logstash,主要是因为Logstash的CPU效率较低)。当前发现吞吐量仍然不理想,正在改用原生Java多线程和Spark Streaming两种方式来完成日志解析。
● Elastic Search日志集群使用
斗鱼现有6个ES集群、120个实例,物理机配置32C/128G/6T*12,日均日志量约10T,使用CMS的GC策略;堆大小使用官方推荐的32G,适当增加-Xmn大小;对于大物理机采用3实例同机部署;为提升写入吞吐量,读写分离(配置ES截取呢拓扑);尽量设置成不分词,即设置成not_analyzed;设置合理refresh时间间隔,index_refresh_interval;多集群通过搭建Proxy层来实现统一入口和权限控制。
2.4 大型赛事活动的运维保障
每次大型赛事活动的运维保障,就是一次平台架构的大考。斗鱼是怎样做赛事运维保障的呢?
首先,识别出最核心的服务。换言之就是要挑出那些不接受不可用的核心功能,主要包括:
● 直播视频——斗鱼内容输出的最核心功能;
● 直播间列表——进入直播视频的关键入口;
● 超管功能——保障内容监管的有效执行;
● 弹幕服务——其他行业不常见,但是是直播中主要互动形式。本质是消息推动,但不同点是需要将用户发布的弹幕内容广播给当前同一直播间的所有观众,量级放大N级,需要将流量分发,减轻机房网络带宽压力;
● 交易——这个无需解释。
其次,针对各个核心功能进行容量评估,评估出需要预留的资源规模,主要包括:
● CDN——下文会单独列出;
● 缓存——业务功能依赖的各级缓存,包括Nginx缓存、OpenResty的ngx.share.DICT、Redis/Memcached、进程内缓存,尽可能兜住用户请求,不穿透到MySQL;
● 资源隔离——尽量从物理上隔离;
● 降级——主要是各类开关,基于配置中心的网关开关、Web Server开关、接口开关、缓存开关等;
● 监控——监控赛事期间线上全站和赛事直播间的水位状态;
● 机房——机房网络状态、主从灾备机房网络状态;
● HTTPS——直播行业第一家实现全站HTTPS,保证终端用户体验。
第三,CDN是保障的关键支撑,主要包括静态文件CDN和视频流CDN,视频流是本文讨论的主要内容。主要包括以下准备内容:
● 接入多家CDN厂商,通过统一入口调度,可以针对不同网络状况实现流量切换;
● 需要预备多条推拉流线路,保障主播推流和用户拉流可用;
● 建立CDN-SLA,建立包括视频卡顿率、首屏时间、视频延迟等监控指标的CDN质量评估体系;
● 与CDN厂商同步所有赛事信息,开通赛事热线,做好相应值班安排。
三、效果评价和总结
● 经过一年多架构改造,斗鱼拥有能支撑起千万级用户同时在线观看的能力;
● ELK的版本更新快,需要及时跟进官方大版本,并根据业务特点,不断进行优化和调整。随着熟悉程度的不断加深,会考虑更多的二次开发方案,提升日志系统的整体吞吐能力和性能;
● 持续跟进开源社区优秀组件的发展,例如Flink、Spark Streaming、Elastic Stack等,因地制宜引入合适技术框架提升系统承载能力;
● 现阶段系统服务化的能力仍不健全,在服务治理、服务容量预估、服务扩容方向还有很长的路要走,服务化会持续推进,朝着控制技术债雪球、提升系统可扩展性、系统服务化的方向,持续发力。
更多TOP100案例信息及日程请前往[官网]查阅。包含产品、团队、架构、运维、大数据、人工智能等多个技术专场,4天时间集中分享2017年最值得学习的100个研发案例实践。本平台共送出10张开幕式单天免费体验票,数量有限,先到先得。
以上是关于TOP100summit:分享实录爆炸式增长的斗鱼架构平台的演进的主要内容,如果未能解决你的问题,请参考以下文章
TOP100summit:分享实录-QQ空间10亿级直播背后的技术优化
TOP100summit:分享实录-美团点评 业务快速升级发展背后的系统架构演进
TOP100summit 2017:案例分享魅族持续交付平台建设实践