理解一致性哈希算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解一致性哈希算法相关的知识,希望对你有一定的参考价值。
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
一致性哈希算法性质
良好的分布性系统中的一致性哈希算法需要满足以下的条件
1.平衡性
平衡性是指哈希的结果能够均匀的分配到所有的节点中,这样使得所有的节点都能得到充分的利用。
2.单调性
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。(这段翻译信息有负面价值的,当缓冲区大小变化时一致性哈希(Consistent hashing)尽量保护已分配的内容不会被重新映射到新缓冲区。)
哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况
3.分散性
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到一部分。当终端希望通过哈希过程将内容映射到缓冲区,由于终端看到的缓冲范围不一致,从而导致哈希的结果不一致,最终结果是将相同内容映射到不同的缓冲区内,这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4.负载
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
一致性哈希算法实现
1.利用环形空间
把数据通过一定的hash算法处理后映射到环上,同时也将服务器通过hash算法处理后映射到同一个环上(画图太难了,不干了。。。)
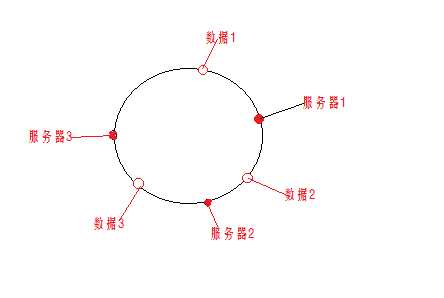
2.数据路由到节点
根据数据和服务器节点之间的距离,顺时针方向,数据缓冲到最靠近的服务器上。
新增节点和删除节点,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。package com.test;
import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; import java.util.SortedMap; import java.util.TreeMap; /** * Created by Lin on 2017/10/17. */ public class ConsistentHash { //服务器列表 private static String [] listServers = {"192.168.0.0","192.168.0.1","192.168.0.2","192.168.0.3","192.168.0.4"}; //key为服务器hash值,value为服务器地址 private static SortedMap<Integer,String> sorteMapServers = new TreeMap<>(); public static void main(String[] args) { init();
//添加删除节点动作可手动操作看结果 String [] keys = {"test1","test2","test3","test4"}; for (int i = 0; i < keys.length; i++){ System.out.println("["+keys[i]+"]的hash值为:"+getHash(keys[i])+",被路由到节点["+getServer(keys[i])+"]"); } } //程序初始化,将所有的服务加入sorteMap中 public static void init(){ for (int i = 0; i < listServers.length;i++){ int hash = getHash(listServers[i]); System.out.println("["+listServers[i]+"]加入集合,其hash值为"+hash); sorteMapServers.put(hash,listServers[i]); } System.out.println("------------------------------------------------------------------"); } //获取hash值 public static int getHash(String key){ MessageDigest md5 = null; if (md5 == null) { try { md5 = MessageDigest.getInstance("MD5"); } catch (NoSuchAlgorithmException e) { throw new IllegalStateException("no md5 algrithm found"); } } md5.reset(); md5.update(key.getBytes()); byte[] bKey = md5.digest(); //具体的哈希函数实现细节--每个字节 & 0xFF 再移位 int result = ( (bKey[3] & 0xFF) << 24) | ( (bKey[2] & 0xFF) << 16 | ( (bKey[1] & 0xFF) << 8) | (bKey[0] & 0xFF)); return Math.abs(result); } //得到路由的节点 public static String getServer(String str){ int hash = getHash(str); //获取大于该hash的所有节点 SortedMap<Integer,String> subMap = sorteMapServers.tailMap(hash); if(!subMap.isEmpty()){ //获取大于该hash的节点集合的第一个key return sorteMapServers.get(subMap.firstKey()); }else{ //没有大于该hash节点的就获取所有节点集合的第一个节点 return sorteMapServers.get(sorteMapServers.firstKey()); } } }
注意,删除节点时下一个节点需要承担被删除节点的所以压力,因此缺少平衡性 ,所以这并不能满足一致性哈希算法的平衡性
引入虚拟节点保持一致性哈希算法的平衡性(下面copy别人的,说得肯定比我写得清楚,代码其实与上面的差不多)
这就要引入一个“虚拟节点”的概念了,上面是一台memcached一个节点,并且是从小到大排序的。这样的话,一台坏了,只能由下一台来承担任务。试想一下,如果我一台服务器有多个“虚拟节点”,“虚拟节点”计算出来的hash也有大有小; 1号服务器计算出来的多个“虚拟节点”,有点比2号服务器的“虚拟节点”大,有的又比它小。这样的话,每台服务器都计算出“虚拟节点”,再把所有“虚拟节点”从小到大排序成集群圈会怎样? 这样的话,每台服务器的“虚拟节点”就会平均分布到集群圈的各个区,1号的服务器的“虚拟节点”的右边不只可能是2号服务器的节点了,它还可以是3号,4号,5号或其他号服务器的节点。 假设有3台memcached服务器(假设是a,b,c),每台有10个虚拟节点,那么它们的集群圈排布就可以是这样的(反正是乱的就对了) c-5,c-0,c-8,b-3,c-4,c-1,c-6,c-2,c-9,b-4,a-5,a-3,a-6,c-3,b-8,a-2,a-1,a-9,a-4,a-7,b-0,b-7,b-2,a-8,b-9,b-5,c-7,a-0,b-1,b-6 使用“虚拟节点”,在key落点的时候,操作还是不变的,我们“最右规则”取一个节点,不过这次是个“虚拟节点”,我们还需要通过这个“虚拟节点”搜索反正它的真正服务器信息,然后就可以add key或get key了 好处:使用“虚拟节点”的情况下,当一台服务器坏了,缓存不命中率还是1/(n-1),但是这台坏掉的服务器的任务是平均分配到其他服务器的(因为它的虚拟节点的右边可能是其他任何一台服务器的虚拟节点)。
以上是关于理解一致性哈希算法的主要内容,如果未能解决你的问题,请参考以下文章