一致性哈希算法的理解与实践
Posted hongmingover
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性哈希算法的理解与实践相关的知识,希望对你有一定的参考价值。
一致性哈希算法的理解与实践
过往记忆大数据 2019-03-05
本文原文(点击下面 阅读原文即可进入):https://yikun.github.io/2016/06/09/一致性哈希算法的理解与实践/
在维基百科中,是这么定义的
一致哈希是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
引出
我们在上文中已经介绍了一致性Hash算法的基本优势,我们看到了该算法主要解决的问题是:当slot数发生变化时,能够尽量少的移动数据。那么,我们思考一下,普通的Hash算法是如何实现?又存在什么问题呢?
那么我们引出一个问题:假设有1000w个数据项,100个存储节点,请设计一种算法合理地将他们存储在这些节点上。
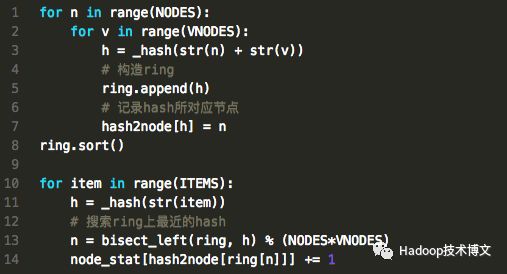
看一看普通Hash算法的原理: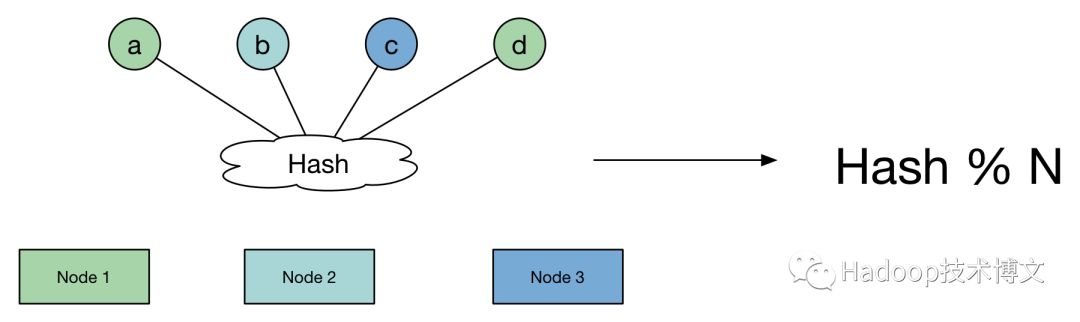
算法的核心计算如下
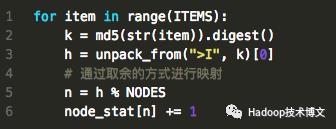
具体的完整实现请参考normal_hash.py(https://github.com/Yikun/hashes/blob/master/normal_hash.py),输出是这样的:
Ave: 100000
Max: 100695 (0.69%)
Min: 99073 (0.93%)
从上述结果可以发现,普通的Hash算法均匀地将这些数据项打散到了这些节点上,并且分布最少和最多的存储节点数据项数目小于1%。之所以分布均匀,主要是依赖Hash算法(实现使用的MD5算法)能够比较随机的分布。
然而,我们看看存在一个问题,由于该算法使用节点数取余的方法,强依赖node的数目,因此,当是node数发生变化的时候,item所对应的node发生剧烈变化,而发生变化的成本就是我们需要在node数发生变化的时候,数据需要迁移,这对存储产品来说显然是不能忍的,我们观察一下增加node后,数据项移动的情况:

详细实现代码在normal_hash_add.py输出是这样的:
Change: 9900989 (99.01%)
翻译一下就是,如果有100个item,当增加一个node,之前99%的数据都需要重新移动。
这显然是不能忍的,普通哈希算法的问题我们已经发现了,如何对其进行改进呢?没错,我们的一致性哈希算法闪亮登场。
登场
我们上节介绍了普通Hash算法的劣势,即当node数发生变化(增加、移除)后,数据项会被重新“打散”,导致大部分数据项不能落到原来的节点上,从而导致大量数据需要迁移。
那么,一个亟待解决的问题就变成了:当node数发生变化时,如何保证尽量少引起迁移呢?即当增加或者删除节点时,对于大多数item,保证原来分配到的某个node,现在仍然应该分配到那个node,将数据迁移量的降到最低。
一致性Hash算法的原理是这样的:
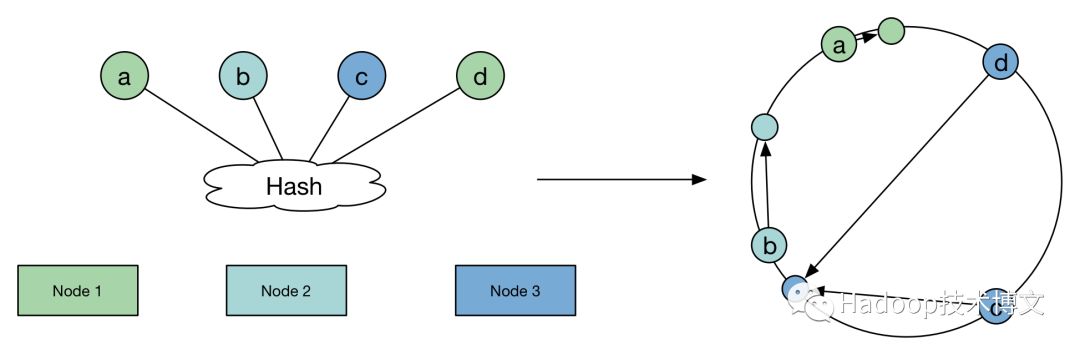
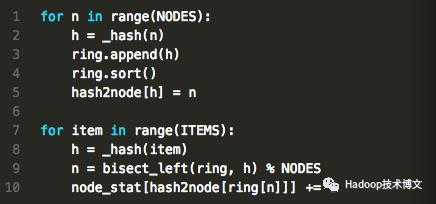
我们依然对其进行了实现consist_hash_add.py(https://github.com/Yikun/hashes/blob/master/consist_hash_add.py),并且观察了数据迁移的结果:
Change: 58897 (0.59%)
虽然一致性Hash算法解决了节点变化导致的数据迁移问题,但是,我们回过头来再看看数据项分布的均匀性,进行了一致性Hash算法的实现consist_hash.py(https://github.com/Yikun/hashes/blob/master/consist_hash.py):
Ave: 100000
Max: 596413 (496.41%)
Min: 103 (99.90%)
这结果简直是简直了,确实非常结果差,分配的很不均匀。我们思考一下,一致性哈希算法分布不均匀的原因是什么?从最初的1000w个数据项经过一般的哈希算法的模拟来看,这些数据项“打散”后,是可以比较均匀分布的。但是引入一致性哈希算法后,为什么就不均匀呢?数据项本身的哈希值并未发生变化,变化的是判断数据项哈希应该落到哪个节点的算法变了。
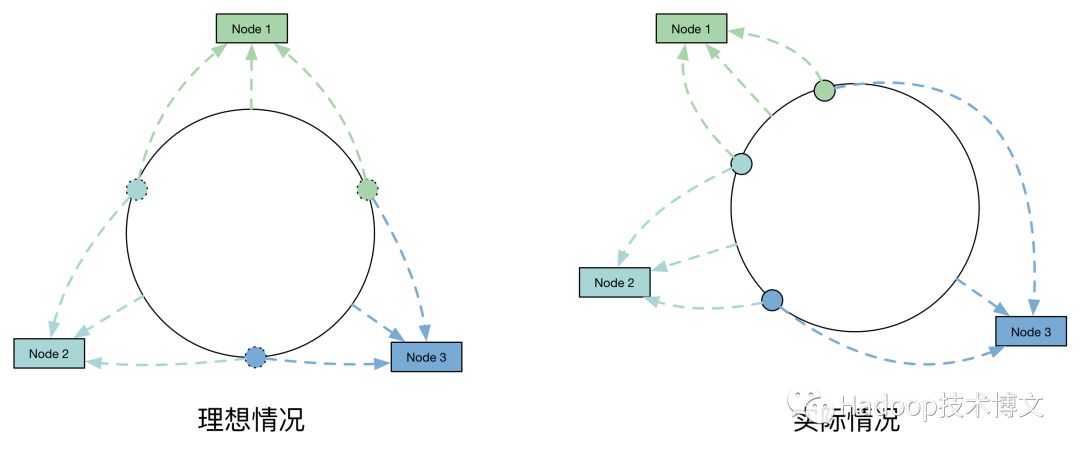
因此,主要是因为这100个节点Hash后,在环上分布不均匀,导致了每个节点实际占据环上的区间大小不一造成的。
改进-虚节点
当我们将node进行哈希后,这些值并没有均匀地落在环上,因此,最终会导致,这些节点所管辖的范围并不均匀,最终导致了数据分布的不均匀。
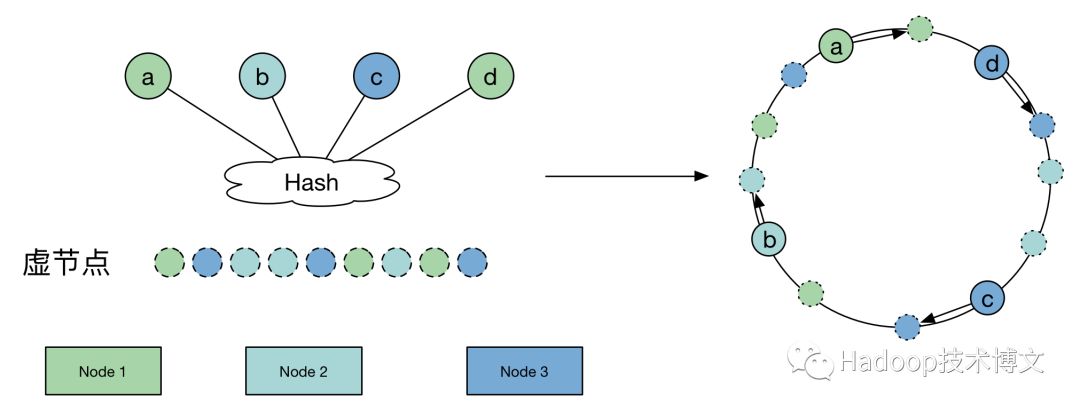
详细实现请见virtual_consist_hash.py(https://github.com/Yikun/hashes/blob/master/virtual_consist_hash.py)
输出结果是这样的:
Ave: 100000
Max: 116902 (16.90%)
Min: 9492 (90.51%)
因此,通过增加虚节点的方法,使得每个节点在环上所“管辖”更加均匀。这样就既保证了在节点变化时,尽可能小的影响数据分布的变化,而同时又保证了数据分布的均匀。也就是靠增加“节点数量”加强管辖区间的均匀。
同时,观察增加节点后数据变动情况,详细的代码请见virtual_consist_hash_add.py(https://github.com/Yikun/hashes/blob/master/virtual_consist_hash_add.py):
100000
101000
Change: 104871 (1.05%)
另一种改进
然而,虚节点这种靠数量取胜的策略增加了存储这些虚节点信息所需要的空间。在OpenStack的Swift组件中,使用了一种比较特殊的方法来解决分布不均的问题,改进了这些数据分布的算法,将环上的空间均匀的映射到一个线性空间,这样,就保证分布的均匀性。

代码实现见part_consist_hash.py(https://github.com/Yikun/hashes/blob/master/part_consist_hash.py)

Ave: 100000
Max: 157298 (57.30%)
Min: 77405 (22.59%)
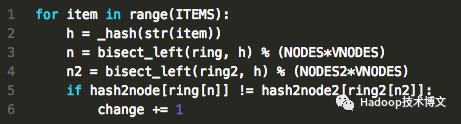
可以看到,数据分布是比较理想的。如果节点数刚好和分区数相等,理论上是可以均匀分布的。而观察下增加节点后的数据移动比例,代码实现见part_consist_hash_add.py(https://github.com/Yikun/hashes/blob/master/part_consist_hash_add.py)
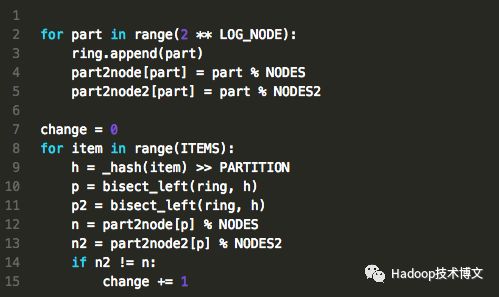
结果如下所示:
Change: 2190208 (21.90%)
可以看到,移动也是比较理想的。
以上是关于一致性哈希算法的理解与实践的主要内容,如果未能解决你的问题,请参考以下文章