scrapy 库--框架
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy 库--框架相关的知识,希望对你有一定的参考价值。
1.scrapy:
scrapy 爬虫框架 爬虫框架 : 1 实现爬虫功能的一个软件结构和功能组件集合; 2 半成品,能够帮助用户实现专业的网络爬虫;

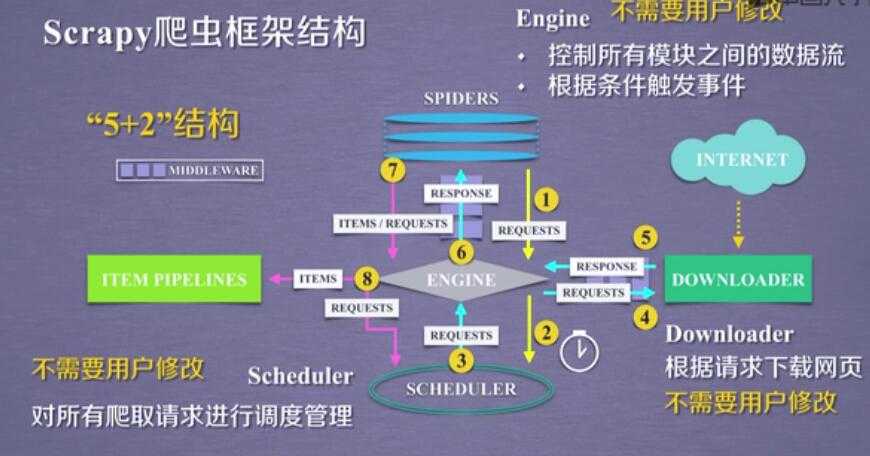
2.scrapy的 5+2 结构:
scrapy框架
5 个骨架结构: ENGINE + ITEM PIPELINE(出口) + SPIDERS(入口) + SCHEDULER + DOWNLOADER
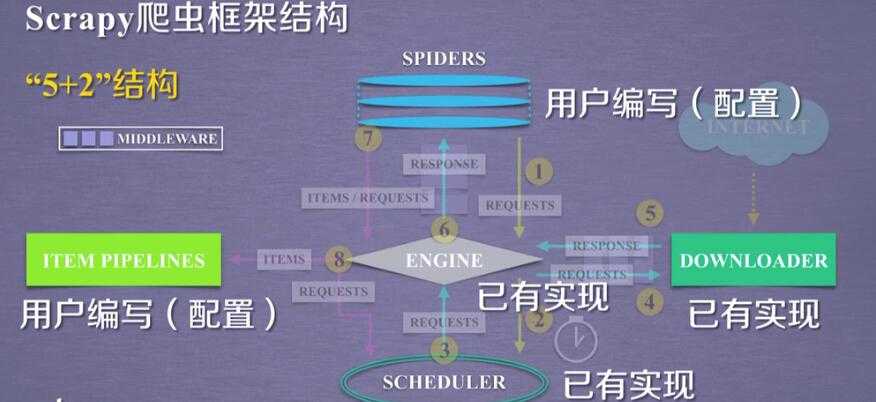
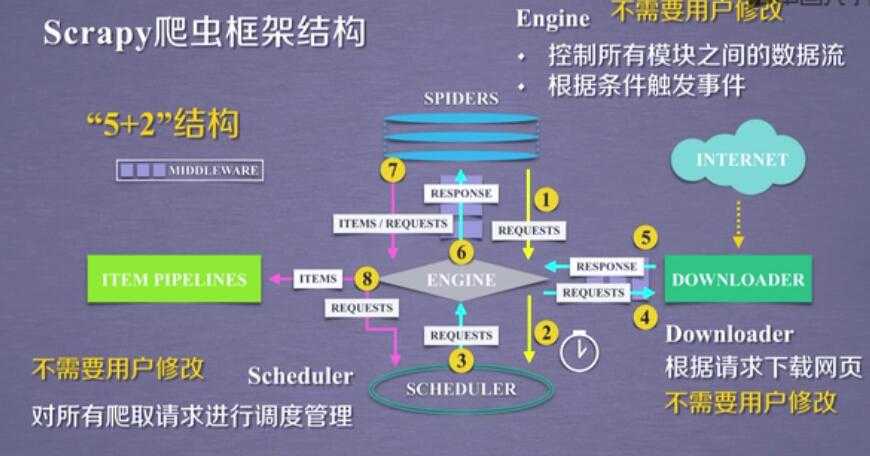
2 个中间配置:
Downloader Middleware ==== 可以配置 scheduler ---downloader 之间的 数据

Spider Middleware ==== Itempipe---spider

3个数据流:spdiers-->> (requests) engine--->> scheduler
scheduler--->>engine(requests)--->>downloader
spiders(respnse)<<----- engine(response) <<------ downloader
spiders--->>(items,requests)---->>> item pipe
----->> scheduler
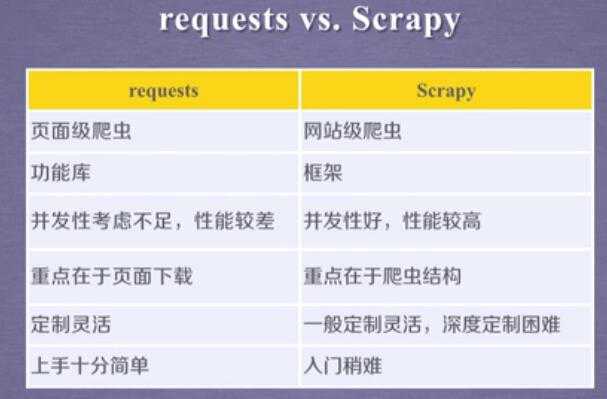
3.scrapy vs requests:


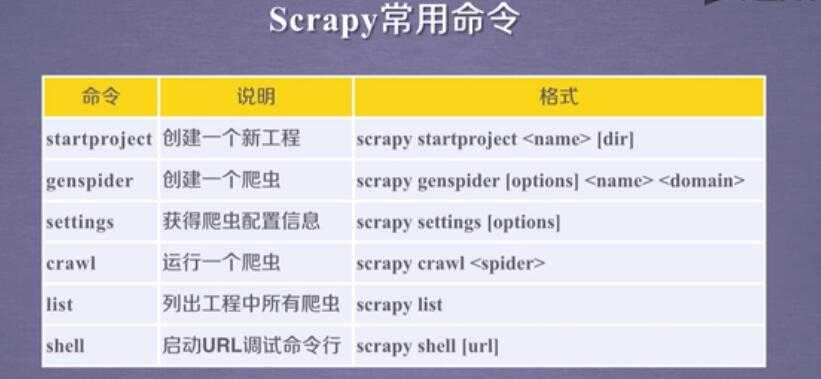
4.scrapy的命令:
scrapy 命令行: scrapy xxx
startproject ---genspider--- crawl ----


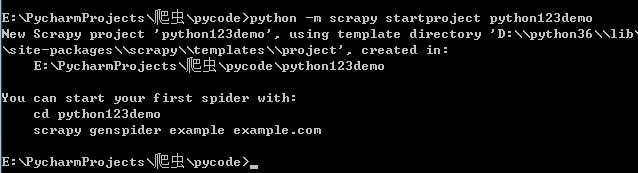
5.创建scrapy工程:
1 创建一个scrapy工程和spider模板 :
cmd---python -m scrapy startproject python123demo


2 产生一个爬虫 编写spider :
python -m scrapy genspider demo python123.io
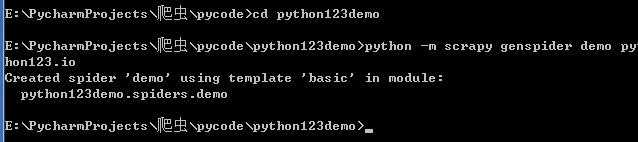

3 配置产生的spider爬虫
配置demo.py 爬虫文件
4 运行爬虫,获取网页
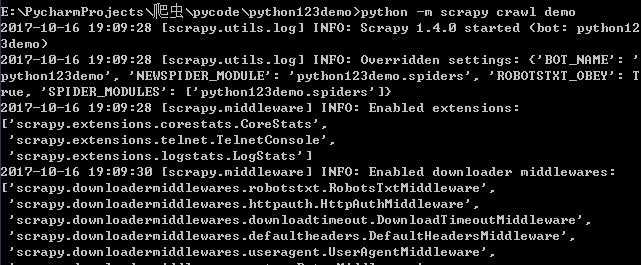
Scrapy的使用步骤:
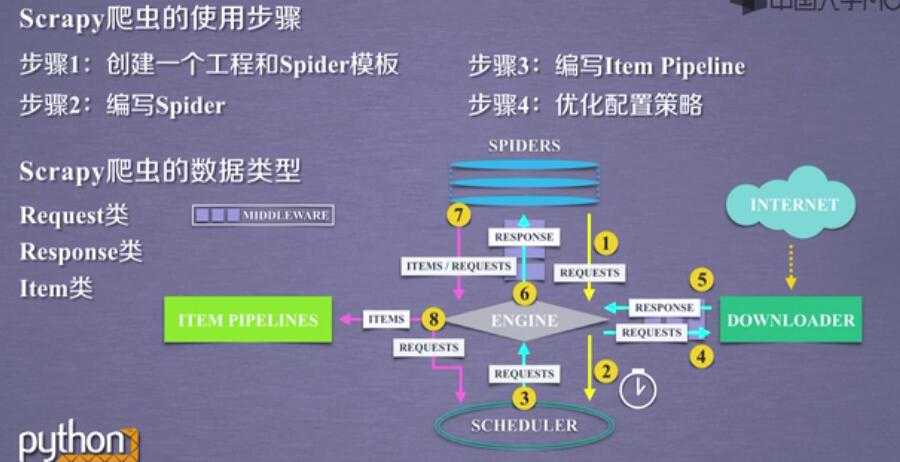
Scrapy 数据类型:





scrapy中的yield关键字:


scrapy爬虫提取数据的方法:

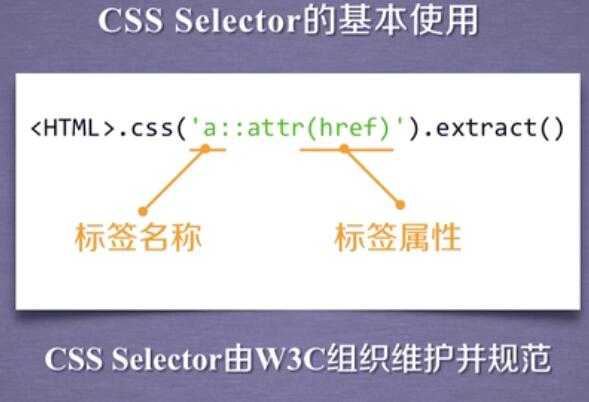
以上是关于scrapy 库--框架的主要内容,如果未能解决你的问题,请参考以下文章