爬虫入门01我第一只由Reuests和BeautifulSoup4供养的Spider
Posted 一只爱蜜蜂的小学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫入门01我第一只由Reuests和BeautifulSoup4供养的Spider相关的知识,希望对你有一定的参考价值。
【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
广东职业技术学院 欧浩源 2017-10-14
1、引言
在数据量爆发式增长的大数据时代,网络与用户的沟通本质上就是数据的交换。网络爬虫可以完成传统搜索引擎不能做的事情,利用爬虫程序在网络上爬取数据,经过数据清洗和分析,使非结构化的数据转换成结构化的数据,其结果可以存储到数据库,也可以进行数据的可视化,还能根据分析数据的基础获得想要的结果。
网络爬虫的入门并没有想象中那么困难,困难的是你有没有勇气踏出第一步。本文将以一个具体例子,详细介绍利用Requests和BeautifulSoup技术实现网络爬虫的技术要点和实现步骤。
2、网络爬虫的基本实现流程
网络爬虫,就是抓取网页数据的程序。
网络爬虫的实现流程包括三个部分:获取网页、解析网页、存储数据。
首先确定需要爬取的网页URL地址,通过程序向该地址发送请求,该网址响应之后则会返回整个网页的数据。得到该数据之后,通过专门的解析器和数据分析算法从中提取感兴趣的数据。如果这些数据是你需要的,就可以把它们存储到文档或数据库中,如果获得的是另外一个URL地址,那么就可以继续进行网页爬取和数据分析,只到得到满意的结果为止。
3、第一个网络爬虫的任务

爬虫任务:将"豆瓣电影TOP250"的网页数据爬取下来,把其他的电影名称、豆瓣评分和对应链接抽取出来,形成一个可视化列表,再将其保存到一个文本文件中。
实现思路:通过Requests库向指定的URL地址发送HTTP请求,从而把整个网页的数据爬取下来,接着通过BeautifulSoup模块对页面数据进行解析从而将需要的信息抽取出来,最后通过文件操作将数据存储到指定的文本文件中。
4、网页内容的抓取
要获取网页的内容,首先要确定该页面的URL地址。这个可以通过浏览“豆瓣电影TOP250”的页面获得。通过引入Requests库可以很容易的想服务器发出请求。在进行后续工作之前,必须先测试一下,能否顺利从服务器获取到页面的数据。关于Requests库的详细用法可见【网络爬虫入门02】。
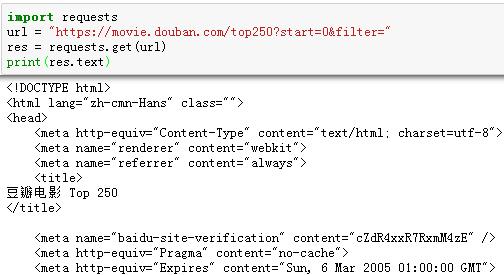
上述的代码已经可以让我们顺利的把“豆瓣电影TOP250”的页面数据爬取下来了。虽然只有区区几行,实际上,已经实现一个网络爬虫了。现在很多网站对于非正常请求是拒绝访问的。所以,必须给爬虫穿上一个合法的外衣。最理想的做法是,将爬虫的访问模拟成浏览器的请求。在requests发送请求的时候,把一个合法的请求头发送过去,就可以将爬虫的访问伪装成一个浏览器的合法访问了。
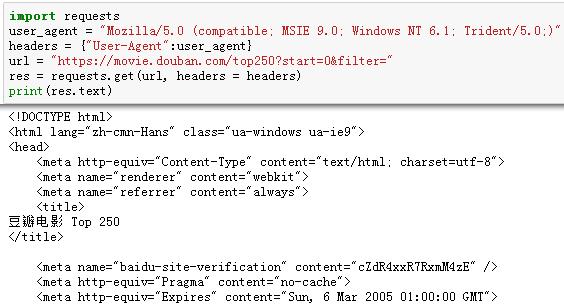
现在只是实现了单一页面的爬取。如果要让爬虫能后自动的将所有的页面数据都爬取下来,我们就要分析每个页面的ULR地址的关联度并发现其中的规律。我们将前面4页的URL取下来,然后分析研究。

通过观察每页URL地址的信息,可以发现其中大部分的内容都是一样的,只有其中的一个数字发生变化。实际上,每页的URL地址可以简化一下的:

从上面的内容可以看出,每一页的URL地址中只有最后一个数据变化,而且每页之间的数值大小都是25。因此,可以通过一个循环,实现全部页面的连续爬取。
5、网页内容的解析
我们需要的是页面中感兴趣的数据,而不是整个页面的全部信息。所以,要通过对页面内容的解析和分析,把目标数据抽取出来。实现这个过程有多种方法,在这里我们选用BeautifulSoup模块作为解析器,其详细的描述请见【网络爬虫入门03】。
对页面内容进行分析的第一步不是编写代码,而是分析爬取下来的页面代码,找到目标数据所在的位置,并对其进行定位,然后才能对其准确的抽取。

通过分析发现:
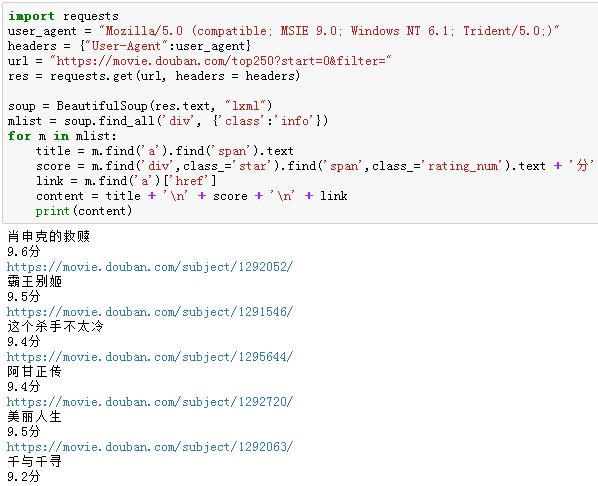
1. 每部电影的信息都包含在‘div’标签,而且class的值为‘info’里面。
2. 在这个tag中,第一个‘a’标签中的第一个‘span’标签的字符串信息为电影名称。
3.在这个tag中,第一个‘a’标签中的‘href’属性值就是电影的相关链接。
4. 在这个tag中,class属性值为‘star’的‘div’标签中,class属性值为‘rating_num’的标签的字符串信息为豆瓣评分。
我们找到了目标数据的定位信息后,在上面爬取的单一页面的基础上,进行编码验证是否能准确获得目标信息。
6、网页数据的存储
通过爬虫获取的数据,经过解析后形成有价值的信息。我们需求把这些数据存储起来,可以存储在文件中也可以存储在数据库中。对于入门初学这来说,先学会把爬取的数据存储在指定的文本文件中。
在我们这个爬虫中,把数据存储到本地E盘的“movie_top250.txt”文件中。具体由Python的文件操作语句来实现,相当的简单,只有两句话:
with open(\'e:\\\\movie_top_250.txt\',\'a+\') as f:
f.write(content)
7、爬虫的完整实现代码
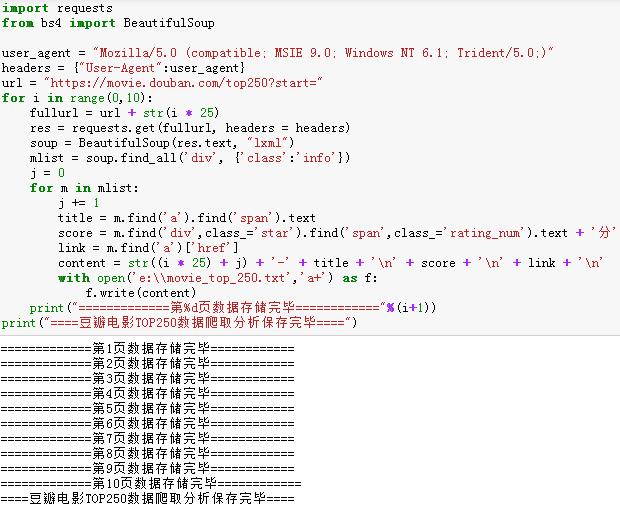
打开保存信息的文件,你可以看到:

8、小结
没错,用Python实现网络爬虫就是那么简单!网络爬虫可以帮你收集和处理大量数据,让你可以一次查看几千甚至几万个网页,并通过数据分析获得目标结果。Python语言拥有强大的第三方库,从Requests和BeautifulSoup入手学习网络爬虫是一个非常不错的选择。
9、附件:源码。
import requests from bs4 import BeautifulSoup user_agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;)" headers = {"User-Agent":user_agent} url = "https://movie.douban.com/top250?start=" for i in range(0,10): fullurl = url + str(i * 25) res = requests.get(fullurl, headers = headers) soup = BeautifulSoup(res.text, "lxml") mlist = soup.find_all(\'div\', {\'class\':\'info\'})
j = 0 for m in mlist:
j += 1 title = m.find(\'a\').find(\'span\').text score = m.find(\'div\',class_=\'star\').find(\'span\',class_=\'rating_num\').text + \'分\' link = m.find(\'a\')[\'href\'] content = str((i*25) + j) + \'-\' + title + \'\\n\' + score + \'\\n\' + link + \'\\n\' with open(\'e:\\\\movie_top_250.txt\',\'a+\') as f: f.write(content) print("============第%d页数据存储完毕============"%(i+1)) print("======豆瓣电影TOP250数据爬取分析保存完毕======")
以上是关于爬虫入门01我第一只由Reuests和BeautifulSoup4供养的Spider的主要内容,如果未能解决你的问题,请参考以下文章