01_爬虫基础知识回顾
Posted shy-kevin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01_爬虫基础知识回顾相关的知识,希望对你有一定的参考价值。
技术选型,爬虫能做什么?
1、Scrapy VS requests+beautifulsoup
- requests和beautifulsoup都是库,Scrapy是框架。
- scrapy框架可以加入requests和beautifulsoup。
- scrapy是基于twisted,性能是最大的优势。
- scrapy方便扩展,提供了很多内置的功能。
- scrapy内置的css和xpath selector非常方便,beautifulsoup最大的缺点就是慢。
2、爬虫能做什么?
- 搜索引擎(百度、google、垂直领域搜索引擎)。
- 推荐引擎(今日头条、一点资讯)。
- 机器学习的数据样本。
- 数据分析(如金融数据分析)、舆情分析。
正则表达式
- 贪婪模式:正则表达式一把趋向于最大长度的匹配,也就是所谓的贪婪匹配。
- 非贪婪匹配:就是匹配到结果就好,较少的匹配字符。
- 默认是贪婪模式,在两次后面直接加上一个问号
?就是非贪婪模式。
1、特殊字符(原始字符串‘booby123‘)
-
^:^b以b开头的字符串 -
.???: 匹配任意字符串 -
*??: 任意长度(次数),≥0 -
(): 要取出的信息就用括号括起来 -
?: 非贪婪模式(从左边开始匹配),尽可能少的匹配所搜索的字符串‘.*?(b.*?b).*‘----从左至右第一个b和的二个b之间的内容(包含b) -
+:+ 前面的字符至少出现一次 -
{}: 前面字符出现的次数 -
+:?出现至少一次 -
{2}?:限定字符出现次数,2次 -
{2,5}:?出现2-5次之间,后者需大于前者 -
|?:或”的关系,例如:“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”或"zood"。 -
():提取字符串里的值,(1)“第一个字符串值” -
[]:满足中括号内任意字符就行,进入后皆无特殊含义[.*]、区间[0-9]、具体数值[123]、不等于1[^1] -
s:为空格 S非空格 -
w:大小写字、数字以及下划线,等于:[A-Za-z0-9_] -
W:匹配下划线在内的任何单词字符,[^A-Za-z0-9_] -
w:和上一个相反 -
[u4E00-u9FA5]:匹配所有中文 -
d?:匹配数字 -
D:匹配所有非数字
2、正则表达式的运用
①贪婪模式
line = "boooobaaaooobbbbby123"
regex_str = ".*?(b.*b).*" #贪婪模式,从右边选择b,.*(一个或者没有),再到左边最前面一个b。
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#group(1)表示匹配括号里面的第一组,所以输出:boooobaaaooobbbbb
②非贪婪模式
line = "boooobaaaooobbbbby123"
regex_str = ".*?(b.*?b).*" #非贪婪模式,从左边选择b,.*(一个或者没有),再到后面第一个b
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#group(1)表示匹配括号里面的第一组,所以输出:boooob
③年月日正则案例
line = "XXX出生于2001年6/1"
line = "XXX出生于2001-6-1"
line = "XXX出生于2001-06-01"
line = "XXX出生于2001年6月1日"
line = "XXX出生于2001-6-1"
line = "XXX出生于2001-06-01"
line = "XXX出生于2001-06"
regex_str = ".*(d{4}[年-]d{1,2}([月 / -]d{1,2}|[月 / - ]$|$))" #[月日时],满足于具体数字月、日、时就可以
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
深度优先和广度优先原理
1、深度优先和广度优先
- 深度优先:递归算法,默认模式(A、B、D、E、I、C、F、G、H)
- 广度优先:层次算法,队列实现(A、B、C、D、E、F、G、H、I)
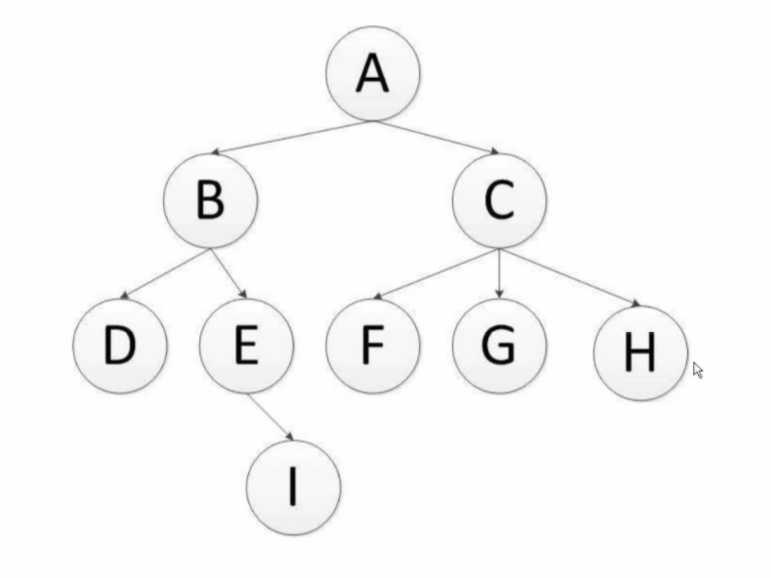
2、深度优先过程
深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。二叉树的深度优先遍历的非递归的通用做法是采用栈,要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历。具体说明如下:
- 先序(根)遍历:对任一子树,先访问根,然后遍历其左子树,最后遍历其右子树。
- 中序(根)遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树。
- 后序(根)遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
DFS的Python算法描述:
def depth_tree(tree_node):
"""
# 深度优先过程
:param tree_node:
:return:
"""
if tree_node is not None:
print(tree_node._data)
if tree_node._left is not None:
return depth_tree(tree_node._left)
if tree_node._right is not None:
return depth_tree(tree_node._right)
注:scrapy默认是通过深度优先来实现的。
3、广度优先过程
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。广度优先遍历的非递归的通用做法是采用队列。
BFS的算法描述:
def level_queue(root):
"""
# 广度优先过程
:param root:
:return:
"""
if root is None:
return
my_queue = []
node = root
my_queue.append(node)
while my_queue:
node = my_queue.pop(0)
print(node.elem)
if node.lchild is not None:
my_queue.append(node.lchild)
if node.rchild is not None:
my_queue.append(node.rchild)
区别:
通常深度优先搜索法遍历时不全部保留结点,遍历完后的结点从栈中弹出删去,这样,一般在栈中存储的结点数就是二叉树的深度值,因此它占用空间较少。所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。 但深度优先搜素算法有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些。
url去重方法
1、爬虫去重的策略
- 将访问过的url保存到数据库中。
- 将访问过的url保存到set中,只要O(1)的代价就可以查询url。(但是如果有1亿个url,那么很容易爆内存
)逻辑如下:- 100000000 * 2byte * 50个字符 / 1024 / 1024 / 1024 ≈ 9G
- 使用
bitmap方法,将访问过的URL通过hash函数映射到某一位。(但是容易发生哈希冲突,,即不同url哈希值相同。)1亿bit = 12.5MB内存 - bloomfilter方法对bitmap进一步优化,对bitmap进行了改进.,通过多个哈希函数,,减少冲突的可能性。
彻底搞清楚unicode和utf8编码
1、字符串编码
- 计算机本身只能处理数字,文本转换为数字才能处理。计算机中8个bit作为一个字节,所以一个字节能表示最大的数字就是255。
- 计算机是美国人发明的,所以一个字节可以表示所以字符了,所以ASCII(一个字节)编码就成为美国人的标准编码。
- 但是ASCII处理中文明显是不够的,中文不止255个汉字,所以中国制定了GB2312编码,用两个字节表示一个汉字。GB2312还把ASCII包含进去了,同理日文韩文等等上百个国家为了解决这个问题都发展了一套字节的编码,标准就越来越多,如果出现多种语言混合显示就一定会出现乱码。
- 于是unicode出现了,将所有语言统一到一套编码里。
- ASCII和unicode编码:
- 字母A用ASCII编码十进制65,二进制01000001
- 汉字"中"已超出了ASCII编码的范围,用unicode编码是20013,二进制01001110 00101101
- A用unicode编码中只需要前面补0,二进制是 00000000 01000001
- 乱码问题解决了,但是如果内容全是英文,unicode编码比ASCII需要多一倍的存储空间,同时如果传输需要多一倍的传输。
- 所以出现了可变长的编码“utf-8”,把英文变长一个字节,汉字3个字节。特别生僻的变成4-6字节。如果传输大量的英文,utf-8作用就很明显。
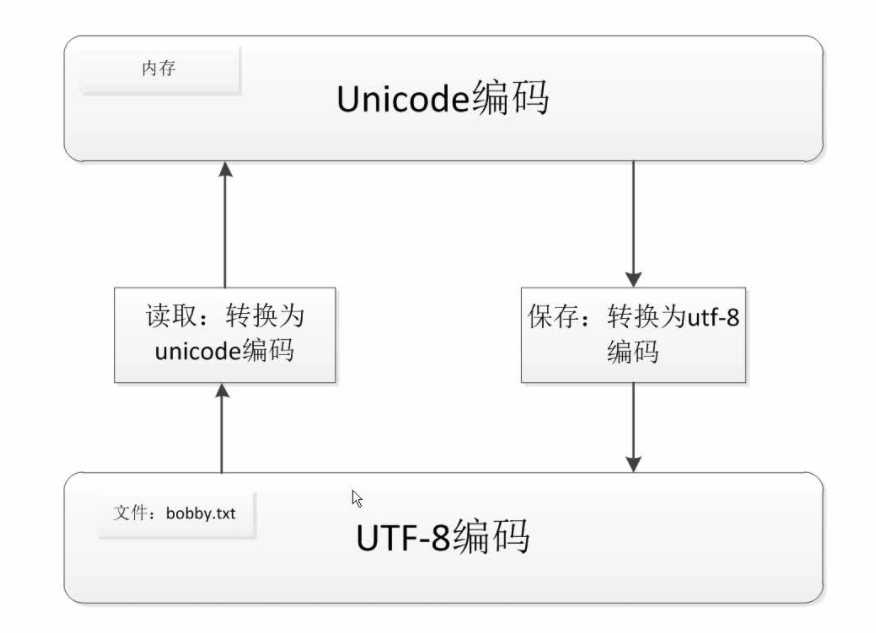
2、Python3的默认采用Unicode编码
decode的方法是将bytes类型转换为str类型(解码)encode的方法是将str类型转换为bytes类型(编码)
stingc = "我爱python"
print(stingc.encode(‘utf-8‘))#encode的方法是将str类型转换为bytes类型
string = stingc.encode(‘utf-8‘)
print(string.decode(‘utf-8‘))#encode的方法是将str类型转换为bytes类型(编码)
以上是关于01_爬虫基础知识回顾的主要内容,如果未能解决你的问题,请参考以下文章
python---基础知识回顾(模块sys,os,random,hashlib,re,json,xml,shutil,configparser,logging,datetime,time,集合,(代码