Python爬虫笔记:爬虫基本入门
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫笔记:爬虫基本入门相关的知识,希望对你有一定的参考价值。
最近在做一个项目,这个项目需要使用网络爬虫从特定网站上爬取数据,于是乎,我打算写一个爬虫系列的文章,与大家分享如何编写一个爬虫。这是这个项目的第一篇文章,这次就简单介绍一下Python爬虫,后面根据项目进展会持续更新。
一、何谓网络爬虫
网络爬虫的概念其实不难理解,大家可以将互联网理解为一张巨大无比的网(渔网吧),而网络爬虫就像一只蜘蛛(爬虫的英文叫spider,蜘蛛的意思,个人认为翻译为网络蜘蛛是不是更形象呢哈哈),而这只蜘蛛便在这张网上爬来爬去,如果它遇到资源,那么它就会抓取下来。至于想抓取什么资源?这个由你自己来进行定义了,你想抓取什么就抓取什么,你具有绝对主宰能力,理论上讲你可以通过网络爬虫从互联网上获取任何你想要并且存在与互联网上的信息。
二、浏览网页的过程
为了理解爬虫,我们应该了解浏览网页的过程,其实说白了,爬虫其实就是利用计算机模拟人类浏览网页。那么浏览网页的过程是什么呢?
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了。
因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的获取。
三、URL的含义
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)。
②第二部分是存有该资源的主机IP地址(有时也包括端口号)。
③第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据,准确理解它的含义对爬虫学习有很大帮助。
四、环境的配置
理论上你可以采用任何一种语言编写网络爬虫,不过这里我给大家分享的是利用Python编写爬虫。因为Python的灵活、美丽以及对网络编程的强大支持,使之成为网络爬虫编程语言的首选。安装Python很简单,这里就不再赘述,从官网下载一个安装包自己安装就OK了、编辑器就用它自带的IDLE吧,安装完之后,右键数遍就会出现IDLE。如图:
五、爬虫初体验
说了这么多,先来感受下一个爬虫吧,这里我们直接抓取一个网页例如:http://www.cnblogs.com/ECJTUACM-873284962/
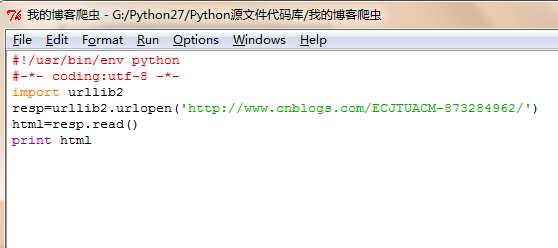
这个网页是我的官方博客,我们要将其内容抓取下来,其实只需要两句代码就能完成,需要使用urllib2库,代码如下:
然后打印结果如下:
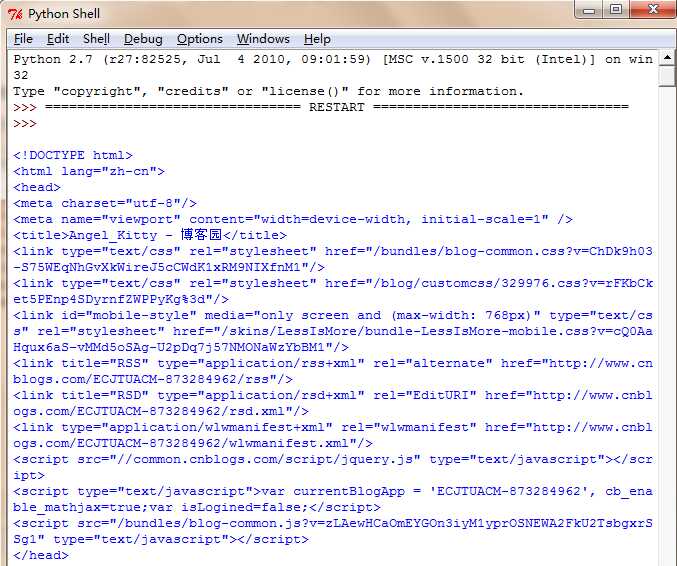
可以看到,将我博客首页的网页内容全部抓取下来了,你可以点击链接访问我的博客,看是否与其内容一致。
其实爬虫就是这么简单,只要明白其中的原理,一切都不是问题。今天只是初步体验爬虫,后续会不断进阶,分享更多爬虫知识。
以上是关于Python爬虫笔记:爬虫基本入门的主要内容,如果未能解决你的问题,请参考以下文章