什么情况下使用large training data会非常有效
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么情况下使用large training data会非常有效相关的知识,希望对你有一定的参考价值。
收集大量的数据可能比算法的优劣更重要
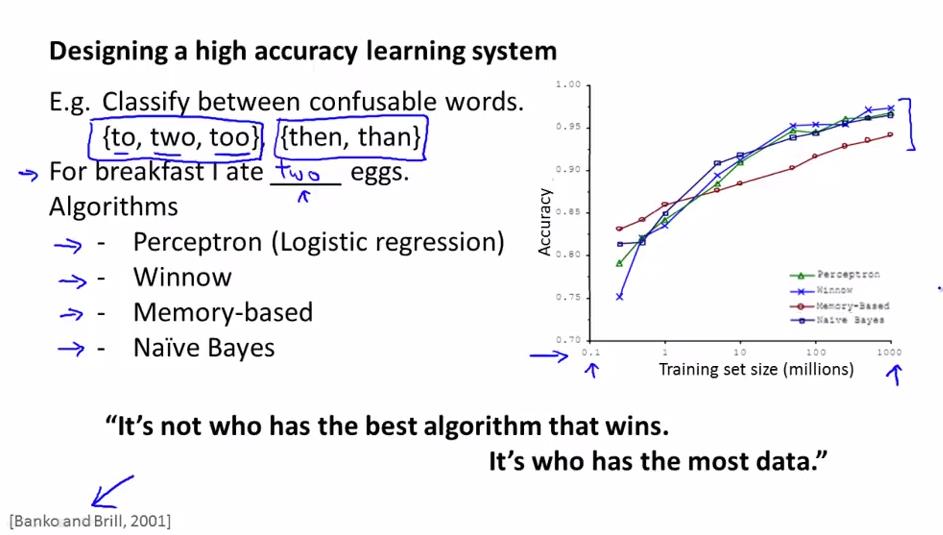
Banko和Brill在2001年做了一个研究,是关于在句子中对易混单词进行识别,画出了上图的右边的那个图,这个图显示了对于不同的算法,它们的表现相似,但是随着training set size的增加,不同的算法的性能都增加。这个说明了一个较劣势的算法,如果它有大量的数据的话,在这个例子中,它的表现会对优秀的算法只有少量的数据要好。了解到这个情况,我们就知道了,在特定的情况下(数据量的提升对改进算法有效),我们应该把精力放在收集大量的数据上,而不是用来选择某个算法。
在业界,有一句话,是"不是有最好算法的人赢了,而是有最多数据的人赢了",说明了收集大量数据的重要性。
之前我们了解到在有些情况下,收集大量的数据是没有用的(如high bias下,随着数据量的增加,算法性能并不会变好)
那么在什么情况下收集大量的数据是有用的呢?

大量数据有用的前提条件: feature能够给我们的预测提供足够的信息
如何来判断x是否给我们提供了足够的信息(useful test): 提供x的这些信息,去看看如果是这方面的专家(人),能否可以预测出y值。
例如:对于填词的那个例子,提供了X(需要填写的词周转的词),一个英语方面的专家能够正确预测出这里应该填哪个单词吗?-----是可以的,前提条件成立,这个说明大量的数据对我们的算法是有好处的。
对于房子价格预测的例子,提供了X(只是房子的面积),一个销售房产的专家也不能够正确预测房子的价格,因为不知道其它房子的信息(如所处地区,新旧,房间数等等)-----前提条件不成立,说明我们收集大量的数据是没有用的,因为这个算法处于high bias(features太少)的情况。
大量数据有用的一些讨论

我们使用了一个有很多参数的算法(即features提供了足够的信息),那么这个算法能画出很复杂的曲线,即能很好的拟合我的training data,即J(training)很小;
这时如果我们使用大量的traning set的话,算法就不会过拟合了,这样我们的J(test)与J(training)相近的大小(因过拟合的话,J(test)大J(training)小,它们之间有一段gap),又因为J(training)很小,所以J(test)也很小。=》说明了我们使用大量的数据对于有很多参数的算法来说是有效的。
另一方面说明:算法有很多参数=>low bias;using large training set(unlikely to overfit)=>low variance。我们的目的就是得到low bias与low variance的算法。
总结
- 拿到一个X(features),想想如果是一个在这方面的专家,能够根据X来正确预测出Y值吗?=>判断信息是否足够
- 如果我的算法的parameters足够多(信息足够多),这时我们增大训练集的数量是非常有效的,能够提高我的算法的性能。
以上是关于什么情况下使用large training data会非常有效的主要内容,如果未能解决你的问题,请参考以下文章
GPT-2隐私泄露论文阅读:Extracting Training Data from Large Language Models
论文笔记:On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
ON LARGE BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA
ON LARGE BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA
LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
r 移动列的功能来自http://stackoverflow.com/questions/18339370/reordering-columns-in-a-large-dataframe