侃一侃编译原理的“文法”
Posted 于果alpha技术博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了侃一侃编译原理的“文法”相关的知识,希望对你有一定的参考价值。
如果你敲累了代码,想喝喝咖啡,顺便看点儿可以当佐料的文章那本文应该比较适合现在的你。(•̀ᴗ•́)و ̑̑
我们一天天都在和代码打交道,但是你了解代码的运行原理么?为什么你的一行代码就能被执行出五花八门的效果嘞?
其实代码这玩意儿就是一门语言。是的,你可以看成和中文、英文等语言平等的存在。是语言就得有语言的解析规则,不懂得规则自然无法理解语言的意思。就跟看没字幕的美剧一样,真是痛苦。╮(╯﹏╰)╭
中文有中文的语义、语法、句子、句法、文法,那么编程语言也有自己的语言系统。
我们知道,我们写的代码被编译器或者解释器所执行,那它们是按照什么文法来理解你的代码呢?这就是文法。
本文也不会深入去解析文法,不然可以直接转语言学了(笑~)。本文只是简单介绍文法的一些概念。如果您喝着咖啡,看完之后,能有些许收获,微微一笑,那本文的目的也就达到了。^_^
工欲善其事必先利其器。在谈文法之前,我们先介绍几个概念。
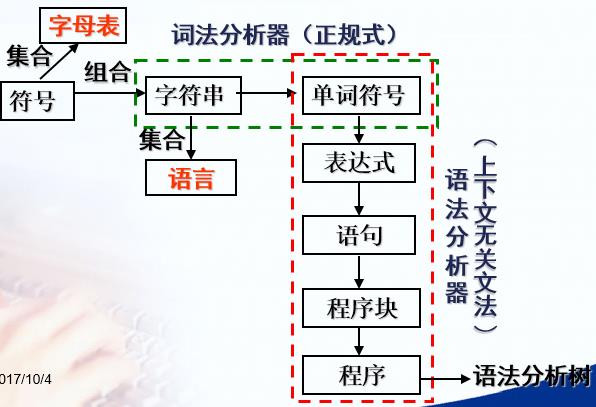
一.文法涉及的几个简单概念
假设Σ是一个有限的字母表集合,它的每一元素都是一个符号。Σ上的一个符号串就是指由Σ中的符号组成的一个有限序列。如果一个符号串不包含任何符号,就叫它空串,记为ε。现在再定义一个集合U和V的连接积的概念:
UV = {αβ | α∈U,β∈V}
比如A = {a,b},B = {1,2},则AB={a1,a2,b1,b2}。很简单的概念,是不是?
那么相信你也能知道V1,V2等的幂的概念了。
还有几个:

ok,定义结束,现在来谈谈咱们本次的主角——文法。一个比较拗口的定义,
文法是描述语言的语法结构的形式规则(即语法规则)。
这啥意思啊?可能你一脸黑人问号……

其实,就是指怎么由一堆符号组成一个有含义的句子的规则和协议。
所谓的上下文无关文法就是文法的一种,它所定义的语法单位是完全上下文无关的。比如我们在程序语言 中,碰到一个算数表达式时,我们完全可以对它“就事论事”,不用去考虑它上下有啥东西。当然,在自然语言(中文、英文等)中,一个语法单位(字、词、句子)肯定和上下文环境有关,不然当年我们中文考试的阅读理解题也就不会出现“根据上下文,解释xx句子的含意”了。(ˇˍˇ) 想~
所以说,上下文无关文法不能用来描述自然语言,但是对于当今的程序语言来说,上下文无关文法基本够用了。下文中的“文法”,如果没有特殊说明,都是之指“上下文无关文法”。
下面类比自然语言的具体例子,谈谈我们今天要说的文法。
一个英文句子:
He gave me a book.
这个句子满足英语的语法规则,是一个语法正确的句子。如果我们用“→”表示“由...组成”或者“定义为”,按照我们中学的语法,可以分解一下这个句子:

这样,通过这样的一个个规则(又叫“产生式”),就把一个句子分解到了单词的层次。或者这么说,有了这些规则,我们可以这么干:

我们可以画一个更形象的图(语法分析树)来说明这种推导。
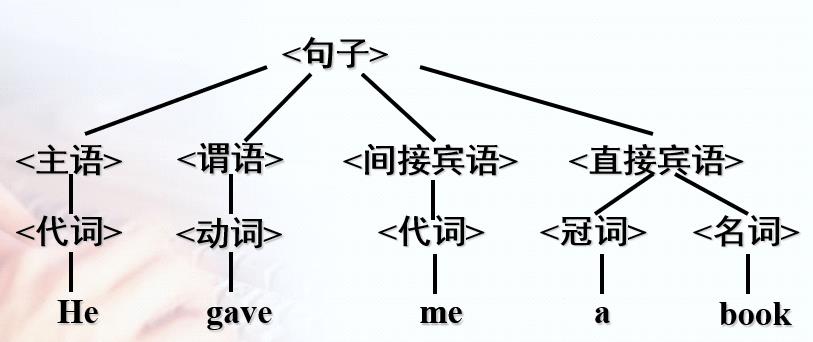
上面定义英文句子的规则就可以说是一个上下文无关文法。其中,<句子>被称为开始符号,<主语><谓语><代词>之类的被称为非终结符号,He、gave之类的被称为终结符号。
归纳起来,一个上下文无关文法G包括四个部分:终结符号,非终结符号,开始符号,产生式。
终结符号就是一门语言中最基本的符号。在程序语言中,基本字、标识符、常数、运算符号等都算终结符号。
非终结符号更像一个抽象的集合,比如“算数表达式”、“赋值句”都可以看做非终结符号。
产生式就是推导规则。
下面上精确定义:

二.递归定义的例子
有时候,只用一个产生式是不足以定义一个语法单位的,需要几个产生式的相互配合。有时候会需要递归的形式。举个栗子:

假设要定义一类含有+、*的算术表达式,这个定义可以这么说:
- 变量是一个算术表达式;
- 如果E1和E2是算术表达式,那么E1+E2、E1*E2、(E1)也是算术表达式。
我们用产生式的形式描述它:
- E→i
- E→E+E
- E→E*E
- E→(E)
其中 E 代表算术表达式, i 代表变量。这四个产生式的全体才定义了什么是“算术表达式”。后三个都是递归的形式。
还可以简化为:E→i | E+E | E*E | (E)。其中的“|”代表“或”,是一种元语言符号。
三.文法与语言的推导
假设G是一个文法,S是开始符号,如果S经过零步或者若干步推出α,那么称α是一个句型。只包含终结符号的句型是一个句子。文法G产生的所有句子构成一门语言,记为L(G)。
那么怎么从文法推导出它代表的语言嘞?
为了方便,我们引入一些符号。

方法:把产生式看成替换规则,把当前符号串中的非终结符号用其产生式右边的符号来替换。

再看有文法G2->语言L(G2)例子。

推导过程如下:

语言L(G2)-> G2 的例子。

由上面的两个例子我们可以知道,一个文法可以唯一确定一个语言,但是一个语言不一定唯一对应一个文法。
四.语法分析树与二义性
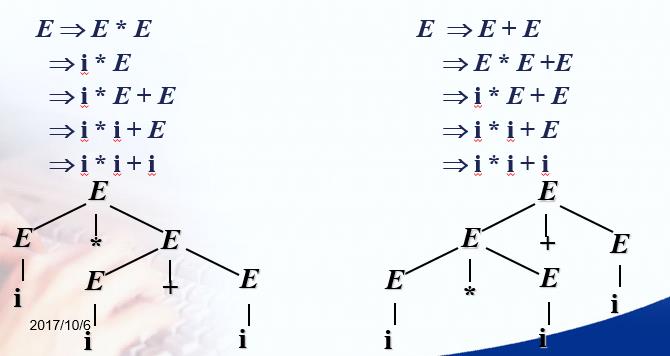
我们发现从一个句型到另一个句型的推导过程不是唯一的。例如从E+E->i+i,存在两个推导过程:
- E+E->E+i->i+i 最右推导,每个推导过程都是从最右边的非终结符号的替换开始
- E+E->i+E->i+i 最左推导,每个推导过程都是从最左边的非终结符号的替换开始
当然为了对句子的结构进行一个确定性的分析,我们一般只考虑最左推导或者最右推导。
前面我们提到过用一种树形的图示来表示这个句型的推导过程,这棵树就被称为”语法分析树“,简称”语法树“。
比如从E->(i+i) 的过程:

对于一个文法,如果它的某些句子对应两棵不同的语法树,这个文法就属于“二义性文法”。
注意,文法的二义性和我们通常所说的语言的二义性不同,我们可能有两个不同的文法G1,G2,一个是二义性,一个是非二义性,但是可能L(G1) = L(G2)。对于程序语言来说,我们常常希望它的文法是非二义性的,但是,只要我们能够控制和驾驭文法的二义性,文法二义性的存在也不一定是坏事。
现在已经证明了,文法二义性是不可判定的。也就是说不存在一个算法,在有限步骤内算出一个文法是不是二义性的。我们能做的事儿,就是找一组充分条件来说明非二义性。比如,规定运算符号的优先级和结合性。
对于我们上面使用的那个文法:E->E+E | (E) | E*E | i
如果限定*的优先级高于+,并且都是左结合的,那么上述文法就变成了非二义性文法。读者大大可以试试推导E->(i*i+i)。
以上是关于侃一侃编译原理的“文法”的主要内容,如果未能解决你的问题,请参考以下文章