如何防止过拟合
Posted 皇家大鹏鹏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何防止过拟合相关的知识,希望对你有一定的参考价值。
过拟合
先谈谈过拟合,所谓过拟合,指的是模型在训练集上表现的很好,但是在交叉验证集合测试集上表现一般,也就是说模型对未知样本的预测表现一般,泛化(generalization)能力较差。
如图所示
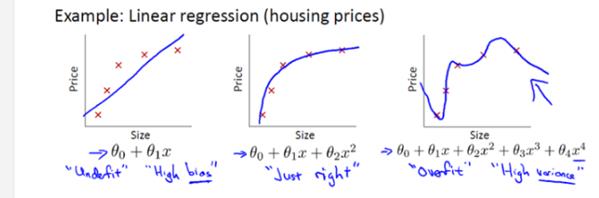
(图片来源:coursera 吴恩达机器学习公开课)
从图中可以看出,图一是欠拟合,模型不能很好地拟合数据;图二是最佳的情况;图三就是过拟合,采用了很复杂的模型。最后导致曲线波动很大,最后最可能出现的结果就是模型对于未知样本的预测效果很差。
在对模型进行训练时,有可能遇到训练数据不够,即训练数据无法对整个数据的分布进行估计的时候,或者在对模型进行过度训练(overtraining)时,常常会导致模型的过拟合(overfitting)。如下图所示:
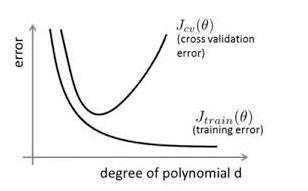
那么如何防止过拟合呢?一般的方法有early stopping、数据集扩增(Data augmentation)、正则化(Regularization)、Dropout等。
有一个概念需要先说明,在机器学习算法中,我们常常将原始数据集分为三部分:training data、validation data,testing data。这个validation data是什么?它其实就是用来避免过拟合的,在训练过程中,我们通常用它来确定一些超参数(比如根据validation data上的accuracy来确定early stopping的epoch大小、根据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?因为如果在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有任何参考意义。
Early stopping:
Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。这样可以有效阻止过拟合的发生,因为过拟合本质上就是对自身特点过度地学习。
正则化:
指的是在目标函数后面添加一个正则化项,一般有L1正则化与L2正则化。L1正则是基于L1范数,即在目标函数后面加上参数的L1范数和项,即参数绝对值和与参数的积项
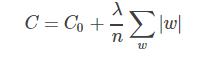
L2正则是基于L2范数,即在目标函数后面加上参数的L2范数和项,即参数的平方和与参数的积项:
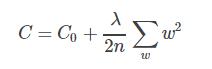
数据集扩增
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。
通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
DropOut:
而在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trick),对于如下所示的三层人工神经网络:
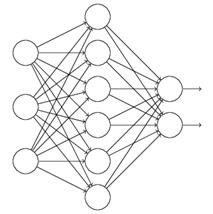
对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:
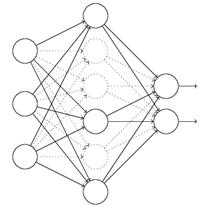
然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行瑕疵,直至训练结束。
(原文地址:http://blog.csdn.net/heyongluoyao8/article/details/49429629)
以上是关于如何防止过拟合的主要内容,如果未能解决你的问题,请参考以下文章