决策树如何防止过拟合
Posted shayue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树如何防止过拟合相关的知识,希望对你有一定的参考价值。
决策树在长成的过程中极易容易出现过拟合的情况,导致泛化能力低。主要有两种手段可以用于防止过拟合。
提前停止
Early Stopping,在完全长成以前停止,以防止过拟合。主要有以下3种方式:
- 限制树的高度,可以利用交叉验证选择
- 利用分类指标,如果下一次切分没有降低误差,则停止切分
- 限制树的节点个数,比如某个节点小于100个样本,停止对该节点切分
后剪枝
提前停止的不足
“提前停止”是一个不错的策略,但是在实际的执行中会越到一些麻烦。比如「其中的第2点,如果下一次切分没有降低误差,则停止切分。」一看貌似很有道理,但是很容易举出反例:
对一个XOR的数据集生成决策树:
 ?
?
下面如果使用x[1]切分:
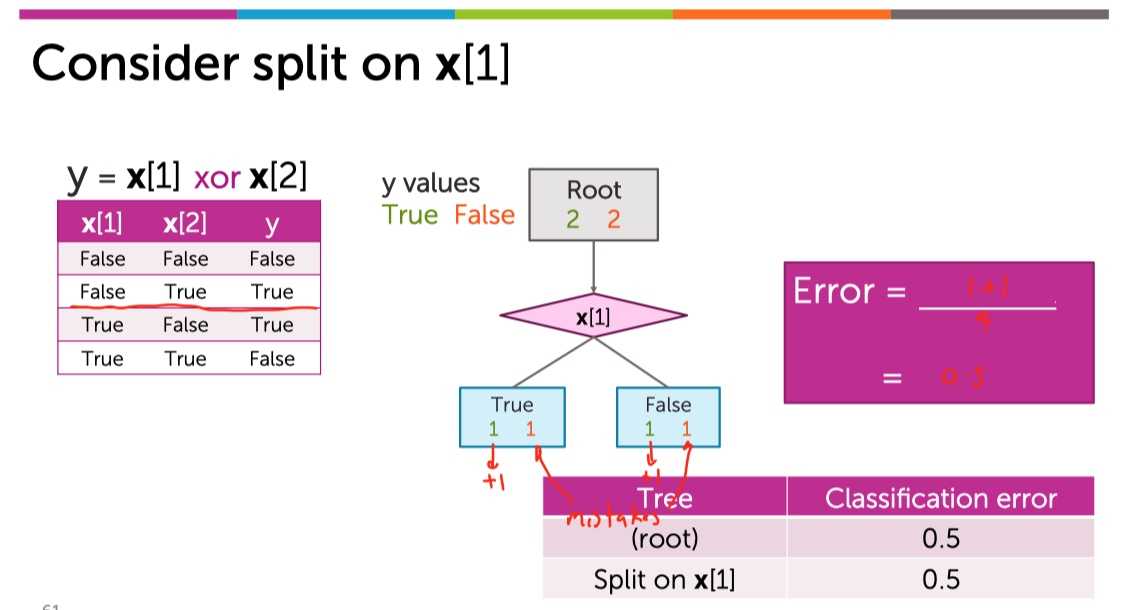 ?
?
又或者用x[2]切分:
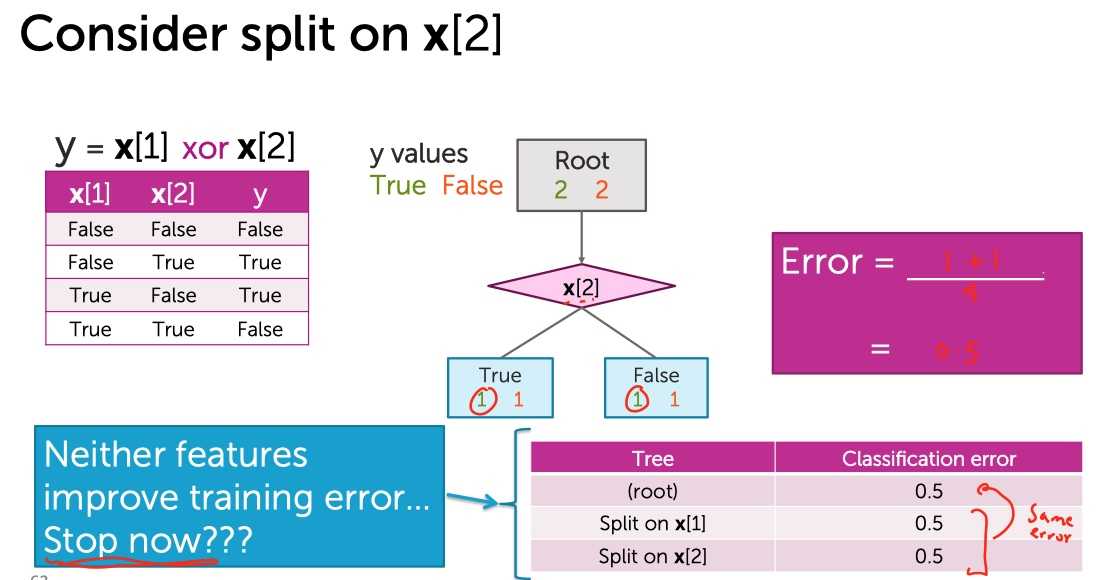 ?
?
发现,无论选择哪一个维度进行切分都不会使得训练误差降低了。所以根据Early Stopping,仅仅长成只有一个节点的stump。但是实际上:
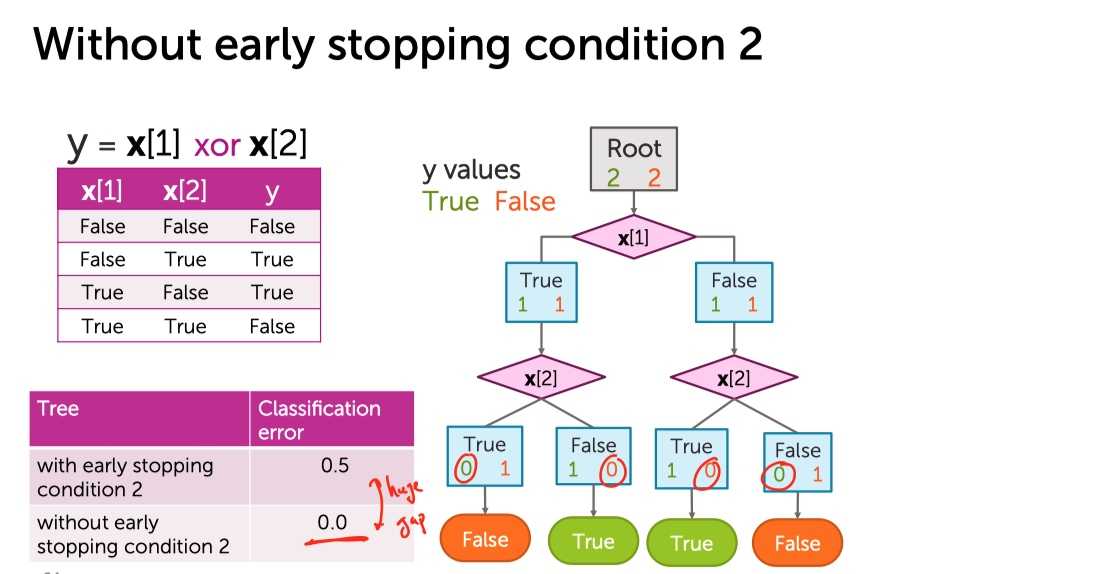 ?
?
继续切下去,能学成一颗具有良好区分度的决策树。所以「提前停止」的第2种情况既有利也有弊:
 ?
?
剪枝
我们通过一颗决策树的叶子结点个数来定义这棵树有多复杂。
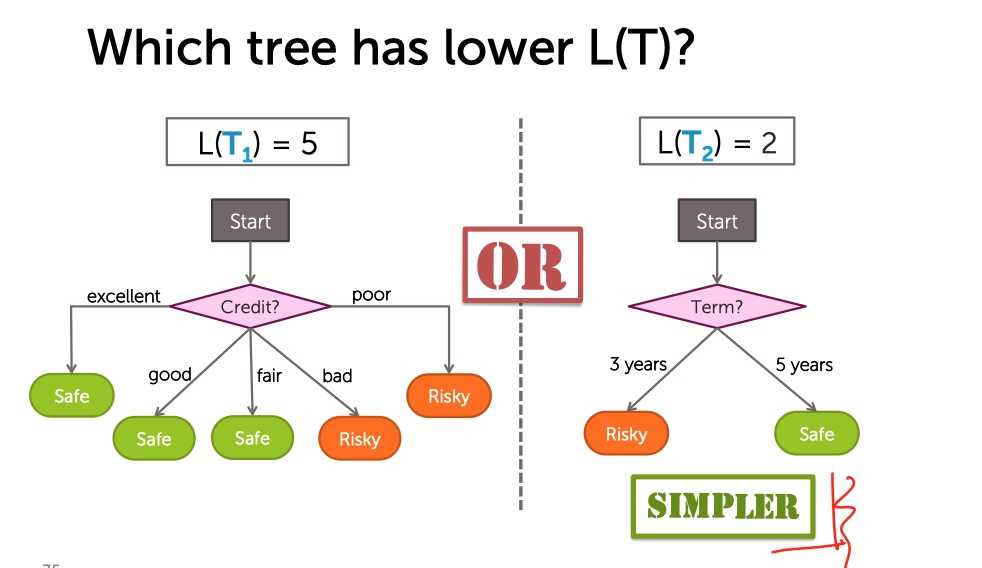 ?
?
但是树太简单也不好,训练误差太大,欠拟合。所以,训练出一颗好的决策树就是在树的训练误差与复杂程度之间做权衡。
 ?
?
写成数学公式,可以表示为:
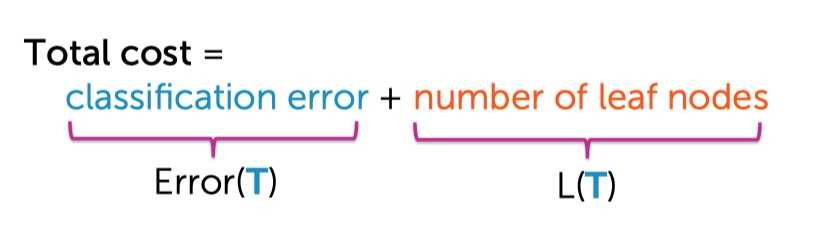 ?
?
 ?
?
剪枝算法
举例说明
有一颗已经长成的树:
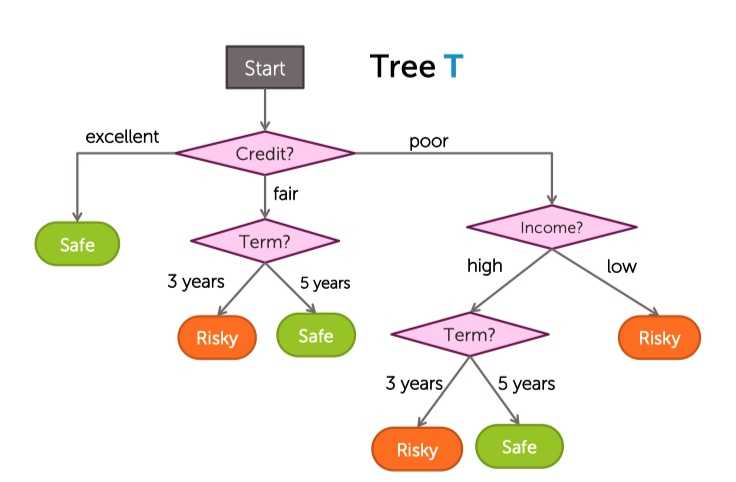 ?
?
从底部开始考虑,第一个要检查的切分点是Term:
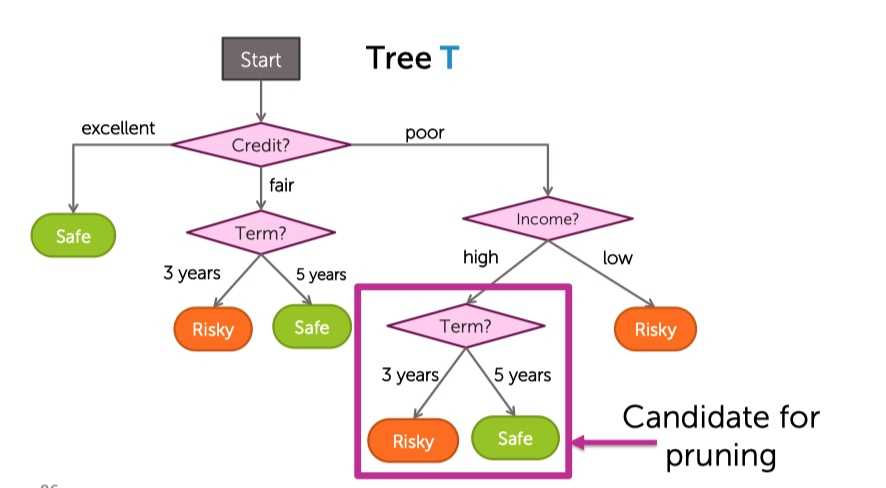 ?
?
假设惩罚性lambda是0.3:
- 对于未剪枝的T,计算它的训练误差为0.25,叶子结点总数为6.所以总的cost为0.43
- 对于剪去Term的Tsamller,计算它的训练误差为0.26,叶子结点总数为5.所以总的cost为0.41
- 因为剪去后的树的损失更小。所以决定剪枝。
- 接着对于所有的切分节点做上述相同的动作。
算法
 ?
?
以上是关于决策树如何防止过拟合的主要内容,如果未能解决你的问题,请参考以下文章