5. 过拟合及其避免
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5. 过拟合及其避免相关的知识,希望对你有一定的参考价值。
参考技术A Fundamental concepts:generalization(泛化、普遍化、一般化);fitting (拟合)and overfitting(过拟合);complexity control(复杂度控制)。Exemplary techniques:cross-validation(交叉验证);attribute selection(特征/属性选择);tree pruning(树剪枝);regularization(正则化)。
Generalization(泛化):指一个模型对于学习集以外的新数据的适应性。
在讨论怎么应对过拟合之前,我们先要知道如何识别过拟合。
Fitting Graph: 拟合图形以一个复杂度函数的形式来展示模型的精确程度。
为了检测过拟合,需要引入一个数据科学的概念, holdout data (留出法,留出数据)。
直接点说就是把学习集分一些数据出来当做模型验证数据,当留出法数据在这个场景下被使用时,通常被叫做“测试集”(相比学习集而言)。
模型结果函数越复杂,对学习集的拟合度则越高,但对测试集的贴合度会降低,这是一个反向关系,使用这个反向关系来寻找合适的模型函数的复杂度,以避免过拟合状况的发生。(可参考下图拟合图进行查看)
关于前面的churn案例的一个拟合图,如下图5-2所示:
关于churn的拟合图中错误率的判断,基于churn数据表中对target variable的yes和no的定义,即已知对于新加入的要素,默认不会churn也就是不会换运营商,新元素no churn=right,churn=wrong。基于全量样本下,会有一个每年固定的churn几率,这个固定的churn几率即为y轴上b的值,这个几率就叫做基础概率即base rate,在朴素贝叶斯的概率预测方法中,base rate被使用的较为广泛,后续章节会有相关介绍。
决策树的每一个叶子节点是否要拆分的依据是查看当前该叶子节点中的所有元素是否有同样的target variable值,若都相同,则不用再拆分,当做叶子节点处理。
决策树的复杂程度取决于它的节点数量。
决策树拟合曲线左侧,树小且预测精度低,右侧精度高。可以看出在sweet spot右侧,学习集适配度随着节点增多而增加,但是测试集准确度随着节点增多而降低,复杂度多过sweet spot时就发生了过拟合。
不幸的是,目前还没有一个理论型的方法可以预测何时能达到这个sweet spot,只能凭借经验主义来做判断。
增加函数复杂度可能有以下情形:
1. 增加变量的数量(即公式中 的数量,i=1,2,3...);
2. 增加非线性变量,如新增变量 ;
3. 增加非线性变量,如新增变量 ;
此时目标函数变为:
这个就是一个典型的非直线函数,并且典型来说,更多参数也就是更高维度,一般带来更高的预测准确度。
这里还通过之前的鸢尾花的花瓣和花萼宽度的例子来解释线性函数的过拟合。
下面我们将原先的2个变量引申为3个变量,即原先的花瓣宽度(petal width)、花萼宽度(sepal width)加上花萼宽度的平方,得到下图所示的曲线:
加入平方变量后,分割线均变为了抛物线(parabola)。
这个小节会讨论过拟合如何产生和为何产生,这节不重要,跳过也不影响学习。
模型越复杂,就越有可能产生有害的假的关联关系(feature和target variable之间的关联关系),这种错误关联关系的泛化影响了对学习集以外的新元素的target variable的预测,从而降低了模型预测的准确度
可以发现通过上述学习集,得出:
1. x=p时,75%可能性class是c1,25%可能性class是c2,所以可以通过x进行class预测;
2. 当已经计入x变量后再添加y变量,则y对class的预测不起作用,即x=p时y=r则class都是c1,x=p时y=s则class都是c2,在决策树中不具备新的预测意义;
3. 但是可以得出结论x=p并且y=r时,class必为c1,这个节点的增加可以获得新的information gain,但是却把整体模型的预测错误率从25%提高到30%,也就是增加的information gain同时增加了错误率。
从这个案例总结出:
1. 这种过拟合现象不仅出现在决策树模型中,只是决策树模型中更明显能看出来;
2. 这种现象并不是表5-1的数据特殊性导致的,所有数据集都会出现类似的问题;
3. 没有一个通用的理论方案来提前知道这个模型是否已经过拟合了,所以一定要留下一个holdout set(即测试集)来对过拟合现象的发生进行判断。
交叉验证的步骤如下:
1. 将数据集分成k个部分并且分别进行标签标记,这些部分命名为folds(子类),通常情况下k会取5或者10;
2. 随后对分组好的数据进行k次模型学习和模型验证的迭代,在每一次迭代中,一个不同的子类被选做测试集,此时其他几个子类共同组成学习集,所以每一个迭代都会有(k-1)/k的数据当做学习集,有1/k的数据当做测试集。
交叉验证的过程直观展现如下图:
3. 通过k次迭代后,可以得到k个不同的模型结果,可通过这k个结果计算出平均值和标准差。
(得到平均值就是数字化的预测结果,而标准差则是浮动范围)
通过这个数据实践可以发现如下几个点:
1. 各子类平均准确度为68.6%,而之前章节全量数据当学习集时的预测准确度为73%,可见全量数据做学习集时出现了显著的过拟合现象;
2. 不同子类的预测准确度有差异,所以取平均值是一个好主意,同时也可以使用这些数据产生的方差;
3. 对比逻辑回归和决策树的结果,发现两种模型在分组3精确度都不高,在分组10精确度都较高,但两种模式是不同的,并且逻辑回归展示了较低的整体准确度64.1%和较高的标准差1.3,所以在这个数据集上面,决策树更适用,因为准确度高并且预测结果更稳定(方差较小),但这个不是绝对的,换到其他数据集,结果就完全不一样了。
模型的 泛化表现 和学习集 数据数量 的关系被叫做 学习曲线(learning curve) 。
学习曲线(learning curve)展示的是基于测试集的泛化表现,针对训练集的数据数量来统计,和训练集数据量相对应(x轴)。
拟合图(fitting graph)展示泛化表现同时也展示模型在学习集的表现,但是和模型的复杂度相对应(x轴),拟合图中训练集数据量通常不会变化。
先从决策树模型开始,逐渐得到一个可适用于多种模型的广泛的避免过拟合的机制(mechanism)。
决策树中一般使用的避免过拟合方法有以下两种:
1. 在决策树过于庞大前停止扩张;
2. 持续扩张决策树,然后回删“prune”决策树,减小它的规模。
关于控制决策树的复杂度的方法包括:
1. 限制每个叶子节点的最小元素个数。那么这个最小个数怎么定呢?
统计学家使用了一种假设测试“hypothesis test”。在停止扩张决策树时,先判定增加节点获得的information gain是否是通过运气(chance)获得的,如果不是通过运气获得的,那么就继续扩张决策树。这个判断基于一个显著性(p-value),通过p-value来定义分叉后的差异是否是由运气产生的,通常这个几率使用5%。
2. 对一个大的决策树进行删节点“prune”,表示使用叶子节点来替换其他的叶子节点或分叉节点。
这个方法取决于替换后,模型的准确度是否会降低,这个过程可以持续迭代直到任何一次替换都会降低模型准确度为止。
那么接下来思考下,如果我们使用所有类型的复杂度来制作决策树会怎样?例如,搭一个节点就停止,然后再搭一个2节点的树,再另外搭一个三节点的树,然后得到了一堆不同复杂度的决策树,然后只要有一个方法能证明模型的泛化表现,那么我们就可以选择到泛化表现最好的这个模型。(应该是拿来承上启下的一段)
嵌套留出测试(nested holdout testing) :将原有的学习集进行再次拆分,拆为子学习集(训练集)和子确认集(validation set for clarity),然后通过子学习集来训练模型,然后用子确认集来验证。
嵌套交叉验证(nested cross-validation) :假如我们要对一组数据进行建模,这组数据有一个未知的复杂度变量C,此时首先对交叉验证中的每个场景(即n个fold(组)为训练集,1个fold为测试集)进行一次仅针对训练集数据的交叉验证,得到此时的最优C值,找到这个场景下的最优复杂度情况,然后再使用这个C值来进行真正的全场景全fold的交叉验证。(与一般的交叉验证的区别在于,先只用训练集数据找到最优复杂度参数C,再执行全数据的交叉验证)
来使用决策树方法简单解释下嵌套交叉验证,根据图5-3所示,最优准确率的决策树节点数是122个,那么就先用子训练集和确认集来得到122节点的这个数值,然后再使用122这个节点数,来对全训练集数据进行建模,此处的122个节点数就可以当做复杂度参数C。
若使用嵌套交叉验证对5个fold的数据集进行分析,那么需要进行30次建模,即对每个折叠情况下的训练集进行子训练集和确认集的拆分的时候,将4个原训练集的fold再拆成5份进行参数C的确认,此时每个outerloop的inner loop包含5个模型(共6个),故一共需要30次建模,可参考下图及链接:
序列向前选择(sequential forward selection - SFS):仍然是测试集(拆分为子测试集和确认集)、验证集,当有n多个特征时,先使用一个feature建模,然后加上第二个,选择其中最好的,然后加上第三个在三个feature的模型中选最好的,以此类推,逐个增加,直到增加feature不能让确认集数据预测更准确为止,此时使用的feature就是建立整个数据集模型要使用的feature。(同样也可以先用全量feature建模,然后一个一个减少,方法类似,名称为sequential backward elimination)
正则化(regularization) :将数字化的回归函数结果简单化的过程,模型拟合度越高越好,同时越简单也越好。
逻辑回归的正则化表达式如下:
其中, 是针对这个回归的最佳模型结果, 是惩罚系数, 是惩罚函数。
通过给原有的最佳模型增加惩罚函数来调整最终结果,得到正则化后的数学表达式。
最常用到的惩罚是各系数(各w值)的平方和,通常叫做w的L2范数(L2-norm of w),当系数很大时,w值的平方和会是一个很大的惩罚值(较大的正值或负值w会使模型更贴合学习集数据,同时也会使L2范数变大即惩罚增大,以此来应对过拟合)。
岭回归(ridge regression) :是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法(least-squares linear regression)(将L2-norm惩罚应用在最小二乘法上之后得到的模型结果)。
最小二乘法(ordinary least squares) :最小二乘法是解决曲线拟合问题最常用的方法。其基本思路是:令
其中, 是事先选定的一组线性无关的函数, (k=1、2...m,m<n)是待定系数,拟合准则是使 (y=1,2...n)与 的距离 的平方和最小,称为最小二乘准则。
如果不使用系数平方和,而使用系数的绝对值来当做惩罚函数,此时叫做L1范数(L1-norm),加上惩罚后的模型称为lasso(LASSO回归)或者L1正则化(L1-regularization)。
L1正则化会使很多系数归零,并且可以通过系数归零来进行feature的选择。
支持向量机的正则化表达式如下:
相比于逻辑回归,支持向量机中把最佳函数更换为hinge loss(铰链损失)判定函数的拟合度,铰链损失越低拟合度越好,所以函数前面加了负号。
grid search(网格搜索):在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search),本书中所提到的嵌套交叉验证寻找最优解的过程也被叫做网格搜索。
场景简介:你的投资公司要成立一个投资基金,将资金投入到1000个基金中,每个基金包含了若干随机挑选的股票,5年后,这些基金有些涨了有些跌了,你可以清算掉跌的,留下涨的,然后宣称你的公司投资回报率很好。
更直观比喻,拿1000个硬币扔很多次,肯定会有某个硬币正面朝上的概率高于50%很多,那么找到这个硬币当成最好的硬币,其实是很傻逼的一种决策。这种问题就叫做多重比较问题。
也就是说通过学习集来得到的多个不同复杂度的模型,就像这多个硬币一样,从这里挑选出来的最优模型,在进行预测时,可能也会遇到“最好硬币”相同的问题,即多重比较误区。
总结就是顺了一遍前面讲的知识点,没啥新内容。
避免过度拟合之正则化(转)
“越少的假设,越好的结果”
商业情景:
当我们选择一种模式去拟合数据时,过度拟合是常见问题。一般化的模型往往能够避免过度拟合,但在有些情况下需要手动降低模型的复杂度,缩减模型相关属性。
让我们来考虑这样一个模型。在课堂中有10个学生。我们试图通过他们过去的成绩预测他们未来的成绩。共有5个男生和5个女生。女生的平均成绩为60而男生的平均成绩为80.全部学生的平均成绩为70.
现在有如下几种预测方法:
1 用70分作为全班成绩的预测
2 预测男生的成绩为80分,而女生的成绩为60分。这是一个简单的模型,但预测效果要好于第一个模型。
3 我们可以将预测模型继续细化,例如用每个人上次考试的成绩作为下次成绩的预测值。这个分析粒度已经达到了可能导致严重错误的级别。
从统计学上讲,第一个模型叫做拟合不足,第二个模型可能达到了成绩预测的最好效果,而第三个模型就存在过度拟合了。
接下来让我们看一张曲线拟合图

上图中Y与自变量X之间呈现了二次函数的关系。采用一个阶数较高的多项式函数对训练集进行拟合时可以产生非常精确的拟合结果但是在测试集上的预测效果比较差。接下来,我们将简要的介绍一些避免过度拟合的方法,并将主要介绍正则化的方法。
避免过度拟合的方法
1 交叉验证: 交叉验证是一轮验证的最简单的形式,每次我们将样本等分为k份,留一份作为测试样本并将其他作为训练样本。通过对训练样本的学习得到模型,将模型用于预测测试样本。循环上述步骤,使每一份样本都曾作为测试集。为了保持较低的方法,k值较大的交叉验证模型比较受青睐。
2 停止法: 停止法为初学者避免过度拟合提供了循环次数的指导
3 剪枝法: 剪枝法在GART (决策树)模型中应用广泛。它用于去掉对于预测提升效果较小的节点。
4 正则化: 这是我们将详细介绍的方法。该方法对目标函数的变量个数引入损失函数的概念。也就是说,正则化方法通过使很多变量的系数为0而降低模型的维度,减少损失。
正则化基础
给定一些自变量X,建立一个简单的因变量y与X之间的回归模型。回归方程类似于:
y = a1x1 + a2x2 + a3x3 + a4x4 .......
在上述方程中a1, a2, a3 …为回归系数,而x1, x2, x3 ..为自变量。给定自变量和因变量,基于目标函数估计回归系数a1, a2 , a3 …。对于线性回归模型目标函数为:
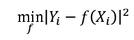
如果存在大量的x1 , x2 , x3 因变量,则可能出现过度拟合的问题。因此我们引入新的惩罚项构成新的目标函数来估计回归系数。在这种修正下,目标函数变为:

方程中的新加项可以是回归系数的平方和乘以一个参数λ。 如果λ=0 过度拟合上限的情景。λ趋于无穷则回归问题变为求y的均值。最优化λ需要找到训练样本和测试样本的的预测准确性之间的一个平衡点。
理解正则化的数学基础
存在各种各样的方法计算回归系数。一种非常常用的方法为坐标下降法。坐标下降是一种迭代方法,在给定初始值后不断寻找使得目标函数最小的收敛的回归系数值。因此我们集中处理回归系数的偏导数。在没有给出更多的导数信息前,我直接给出最后的迭代方程:
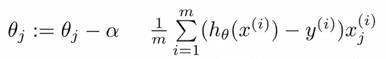 (1)
(1)
这里的θ是估计的回归系数,α为学习参数。现在我们引入损失函数,在对回归系数的平方求偏导数以后,将转化为线性形式。最终的迭代方程如下:
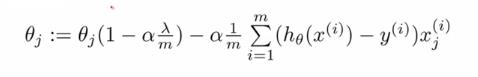 (2)
(2)
如果仔细观察该方程你会发现,ϑ每次迭代的开始点略小于之前的迭代结果。这是(1)与(2)两个迭代方程的唯一区别。而迭代方程(2)试图寻找绝对值最小的收敛的ϑ值。
结束语
在这篇文章中我们简单的介绍了正则化的思想。当然相关的概念远比我们介绍的深入。在接下来的一些文章中我们会继续介绍一些正则化的概念。
原文作者: TAVISH SRIVASTAVA
翻译: F.xy
原文链接:http://www.analyticsvidhya.com/blog/2015/02/avoid-over-fitting-regularization/
http://www.cnblogs.com/yymn/p/4646383.html
以上是关于5. 过拟合及其避免的主要内容,如果未能解决你的问题,请参考以下文章