第二篇:R语言数据可视化之数据塑形技术
Posted 穆晨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二篇:R语言数据可视化之数据塑形技术相关的知识,希望对你有一定的参考价值。
前言
绘制统计图形时,半数以上的时间会花在调用绘图命令之前的数据塑型操作上。因为在把数据送进绘图函数前,还得将数据框转换为适当格式才行。
本文将给出使用R语言进行数据塑型的一些基本的技巧,更多技术细节推荐参考《R语言核心手册》。
数据框塑型
1. 创建数据框 - data.frame()
# 创建向量p
p = c("A", "B", "C")
# 创建向量q
q = 1:3
# 创建数据框:含p/q两列
dat = data.frame(p, q)
结果展示: 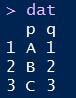
2. 查看数据框信息 - str()
# 展示数据集dat信息 str(dat)
结果展示:

3. 向数据框添加列
基本格式为:数据框$新列名 = 向量名。如下代码将在dat数据集中创建名为newcol的列,并将向量v赋值给它:
dat$newcol = v
如果向量长度小于数据框的行数,R会重复这个向量,直到所有行被填充。
4. 从数据框中删除列
可以将NULL赋值给某列即可。如下代码将删除数据集中的badcol列:
dat$badcol = NULL
也可以使用subset函数(后面会具体讲),并将一个减号至于待删除的列前:
dat = subset(data, select = -badcol)
5. 重命名数据框中的列名
可以将列名称向量赋值给names函数:
names(dat) = c("name1", "name2", "name3")
如果想通过列名重命名某一列可以这样:
# 将名为ctrl的列更名为Cntrol
names(anthoming)[names(anthoming) == "ctrl"] = c("Cntrol")
6. 重排序数据框的列
可以通过数值位置重排序:
# 通过列的数值位置重排序 dat = dat[c(1,3,2)]
也可以通过列的名称重排序:
# 通过列的名称重排序
dat = dat[c("col1", "col3", "col2")]
7. 从数据框提取子集 - subset()
如下R语言代码从climate数据框中,选定Source属性为"Berkeley"的记录的"Year"、"Anomaly10y"两列:
# subset函数:首参选定数据集, Source参数选定行,select参选定列 subset(climate, Source == "Berkeley", select = c(Year, Anomaly10y))
因子水平塑型
1. 根据数据的值改变因子水平顺序 - reorder()
下面这个例子将根据count列对spray列中的因子水平进行重排序,汇总数据为mean:
# reorder函数:首参选定因子向量,次参选定排序依据的数据向量,FUN参数选定汇总函数 iss$spray = reorder(iss$spray, iss$count, FUN = mean)
2. 改变因子水平的名称 - revalue() / mapvalues() in plyr包
如下两行R语言代码均可将水平因子f中名为"small","medium","large"的因子分别更名为"S","M", "L":
# 方法一
f = revalue(f, c(small = "S", medium = "M", large = "L"))
# 方法二
f = mapvalues(f, c("small", "medium", "large"), c("S", "M", "L"))
3. 去掉因子中不再使用的水平 - droplevels()
如下R语言代码将剔除掉因子f中多余的水平:
droplevels(f)
变量塑型
1. 变量替换 - match()
要将某些值替换为其他特定值,可使用match函数。如下R语言代码将数据框pg的group列的oldvals中的"ctr1","trt1","trt2"的值分别替换为"No","Yes","Yes":
# 旧值
oldvals = c("ctrl1", "trt1", "trt2")
# 新值
newvals = factor(c("No", "Yes", "Yes"))
# 替换
pg$treatment = newvals[match(pg$group, oldvals)]
2. 分组转换数据 - ddply() in plyr包
通过使用ddply()函数的transform参数功能,能够对不同分组内的数据进行转换。如下R语代码能够将cabbages数据框按照Cult列因子进行分组,并在数据框中创建一个新的名为DevWt的列,该新列值由原某列值减分组均值得到:
# ddply函数:首参选定数据框,次参选定分组变量,叁参选定处理方式,肆参输出新列 cb = ddply(cabbages, "Cult", transform, DevWt = HeadWt - mean(HeadWt))
3. 分组汇总数据 - ddply() in plyr包
通过使用ddply()函数的transform参数功能,能够对不同分组内的数据进行汇总。汇总和上面介绍的转换的区别在于汇总结果的记录数等于分组的个数,而转换操作后记录数是不变的,只是对原列进行改动转换。如下R语言代码将cabbages数据框按照Cult和Date列因子进行分组,并在数据框中创建一个新的名为DevWt的列,该新列值由对每个分组进行均值统计得到:
# ddply函数:首参选定数据框,次参选定分组变量,叁参选定处理方式,肆参输出新列
cb = ddply(cabbages, c("Cult", "date"), summarise, Weight = mean(HeadWt))
长/宽数据塑型
1. 宽数据 -> 长数据 - melt() in reshape2包
anthoming数据集如下所示:
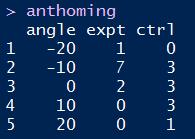
其中expt和ctrl两列可以合并为一列。合并后的数据框相对合并前的叫长数据,而合并前的数据框相对合并后的数据叫宽数据,是不是很贴切呢?
如下R语言代码使用melt函数将上述数据集"拉长":
# melt函数:首参选定数据框,次参选定记录标识列,variable.name选定拉长后的属性名列,value.name选定拉长后的属性值列 melt(anthoming, id.vars = "angle", variable.name = "condition", value.name = "count")
拉长后的效果:

2. 长数据 -> 宽数据 - dcast() in reshape2包
plum数据集如下所示:
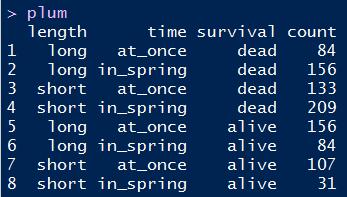
该数据框中length列和time列作为标识列, 如下R语言代码可将该数据框压扁:
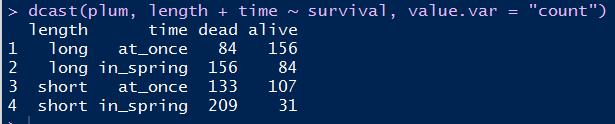
# dcast函数:首参选定数据框,次参选定记录标识列和新的属性名列,value.var选定被拉长的属性值列 dcast(plum, length + time ~ survival, value.var = "count")
压扁后的效果:
小结
在调用任何图像绘制函数之前,都要按照绘图函数的要求摆放好数据,这个过程也被称为数据塑型。本文的部分功能可能读者会疑惑有啥用,别着急,先进入到有趣的绘制章节部分吧。随着绘图次数增多,慢慢就会懂了。
以上是关于第二篇:R语言数据可视化之数据塑形技术的主要内容,如果未能解决你的问题,请参考以下文章