JavaWeb入门详解(第二篇)之xml简介
Posted 穆瑾轩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaWeb入门详解(第二篇)之xml简介相关的知识,希望对你有一定的参考价值。
JavaWeb入门详解(第二篇)之xml简介
1、XML概述
XML(Extensible Markup Language的缩写),被称作可扩展标记语言,是一种标记语言。XML也是 W3C 推荐的数据传输存放标准。XML也不是一出现就备受瞩目的,XML语言的形成经历了一个漫长的过程。
XML并不是历史上第一门标记语言,事实上XML还有两个先驱:SGML和html,这两个语言都是非常成功的标记语言,但是都有一些与生俱来的缺陷,XML正是为了解决它们的不足而诞生的。
XML的发展:GML->SGML->HTML->XML
| 标记语言 | 时间 | 事件描述 |
|---|---|---|
| GML | 60年代 | 自IBM从60年代就开始发展 通用标记语言GML(Generalized Markup Language),实现在不同的机器进行通信的数据规范 |
| SGML | 1978-1986 | 直到1978年,ANSI将GML加以整理规范,发布成为SGML,一个SGML语言文件由三部分组成,即语法定义、文件类型定义DTD(Definition Type Document)和文件实例。1986年ISO正式承认SGML为国际标准规范(ISO8879)。并且被广泛地运用在各种大型的文件计划中。 |
| HTML | 1991 | 1991年WWW在互联网上首次露面,也随之引起了巨大的轰动。 |
| HTML+ | 1993-1996 | 1993年ITEF(因特网工作小组)发布了一个草案,那时没有HTML的官方文档,各种标签(Tag)也很混乱。1989年,欧洲物理量子实验室(CERN)的信息专家蒂姆·伯纳斯·李发明了超文本链接语言, 使用此语言能轻松地将一个文件中的文字或图形连到其他的文件中去。只要用鼠标在第一个文件中点取其中一段或一个图标,就可以为用户取来网络中或其他位置的相关文件,并显示在屏幕上。可以说,HTML(Hypertext Markup Language)是SGML的一个实例,它的DTD作为标准被固定下来。这个草案HTML tags可以算是HTML的第一个版本。1994年,Tim Berners-Lee创建了非盈利性的 W3C(world wild web consortium万维网联盟)。1995年,HTML2.0发布。1996年,HTML3.2发布。 |
| XML | 1998 | 他们认为HTML存在一些缺陷,例如HTML的形式与内容无法分离、标记单一等等,前途不是很光明。于是W3C转向语言更加规范的XML,以便于弥补HTML的不足。1998年,W3C发布XML(Extensible Markup Language 可扩展标记语言) 1.0标准,用来简化Web文档信息的传输,可自定义标签,也是各种应用程序进行数据传输最常用的工具。随着XML技术的发展,XML越来越适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。 |
| XHTML 1.0-2.0 | 2000-2006 | XHTML生态环境渐渐破碎,2006年,XTML2没有实质性进展。Tim Berners-Lee反思,决定重组HTML工作组。 |
| HTML5 | 2014 | 2014年,W3C宣布HTML 5标准规范制定完成,方便了移动端的软件开发,HTML 5已经不是SGML的子集,是一个全新的标准。 |
1.1、XML的用途
1)程序间数据的传输:XML的格式是通用的,能够减少交换数据时的复杂性!
2)配置文件:XML能够非常清晰描述出程序之间的关系,config.xml -> java语言、Python语言、php语言
3)存储数据:充当小型数据库,存储数据。
2、XML的语法声明
在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可分为开始标签和结束标签,在开始标签和结束标签之间,又可以使用其它标签描述其它数据,以此来实现数据关系的描述。
<中国>
<北京>
<海淀></海淀>
<丰台></丰台>
</北京>
<湖南>
<长沙></长沙>
<岳阳></岳阳>
</湖南>
<湖北>
<武汉></武汉>
<荆州></荆州>
</湖北>
</中国>一个XML文件分为如下几部分内容:
-
文档声明
-
元素
-
属性
-
注释
-
CDATA区 、特殊字符
-
处理指令
2.1、文档声明
XML声明放在XML的第一行
-
最简单的声明语法:
<?xml version="1.0" ?>-
用encoding属性说明文档的字符编码:
<?xml version="1.0" encoding="GB2312" ?>-
用standalone属性说明文档是否独立:
<?xml version="1.0" encoding="GB2312" standalone="no" ?>standalone--独立使用--默认是no。standalone表示该xml是不是独立的,如果是yes,则表示这个XML文档时独立的,不能引用外部的DTD规范文件;
2.2、元素
XML文件中出现的标签。
元素命名规范
-
区分大小写,例如,<P>和<p>是两个不同的标记。
-
不能以数字或"_" (下划线)开头。
-
不能以xml(或XML、或Xml 等)开头。
-
不能包含空格,空格和换行都会被当做元素内容进行处理。
-
名称中间不能包含冒号(:)。
2.3、属性
一个标签可以有多个属性,每个属性都有它自己的名称和取值。属性是作为XML元素中的一部分的,命名规范也是和XML元素一样的!
<!--属性名是name,属性值是china-->
<中国 name="china"></中国>
<!--在XML技术中,标签属性所代表的信息,也可以被改成用子元素的形式来描述-->
<中国>
<name>china</name>
</中国>2.4、注释
注释和HTML的注释是一样的
<!--注释-->2.5、CDATA区
有些内容可能不想让解析引擎解析执行,而是当作原始内容处理。语法:<![CDATA[ 内容 ]]>
<![CDATA[
<itcast>
<br/>
</itcast>
]]>2.6、转义字符
| 转义字符 | 替代 |
|---|---|
| & | & |
| < | < |
| > | > |
| " | " |
| ' | &apos |
2.7、处理指令
处理指令,简称PI (processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。处理指令必须以“<?”作为开头,以“?>”作为结尾,XML声明语句就是最常见的一种处理指令。
例如:在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用css文件显示xml文档内容。 <?xml-stylesheet type="text/css" href="1.css"?>
XML代码:
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/css" href="1.css"?>
<china>
<province>
<jiangxi id="a1">江西</jiangxi>
<beijing id="a2">北京</beijing>
</province>
</china>CSS代码:
#a1{
font-size: 60px;
color:red;
}
#a2{
font-size: 70px;
}案例效果:

3、XML的技术架构
XML文件是可扩展的,且里面的标签可以自定义的,只要符合XML的最基本要求,那么就可以写一个XML文件。但是在实际应用中,我们需要针对某一个特定的应用,给xml中引入一下语法,这些语法用来检测特定应用的XML文件编写是否正确。例如mybatis中使用的DTD约束,spring中使用的shema约束。
XML文档只用于组织、存储数据,除此之外的读取、传送、存取等等操作都与XML本身无关!就需要用到XML之外的技术了。
-
为XML定约束:现在一般使用DTD或Schema技术
-
解析XML的数据:一般使用DOM或者SAX技术,各有各的优点
-
提供样式:XML一般用来存储数据的,但设计者野心很大,也想用来显示数据,就有了XSLT(eXtensiable Stylesheet Language Transformation)可扩展样式转换语言
3.1、xml-DTD约束
xml约束就是在特定应用下,为xml编写的一下语法,用来检测这个应用下的xml文件是否正确。
描述约束的文件是以.dtd为扩展名,dtd约束作用于xml文档,会有两种方式:
-
把dtd约束直接写到xml文档中
<?xml version="1.0" encoding="UTF-8"?>
<!--XML文件使用 DOCTYPE 声明语句来指明它所遵循的DTD文件-->
<!DOCTYPE users[
<!ELEMENT users (user+) > <!-- +: users下可出现一次或多次user,?: 0次或一次,*: 0次或多次-->
<!ELEMENT user (name,age,addr) > <!-- user下可出现一次name,age,addr-->
<!ELEMENT name (#PCDATA) > <!-- #PCDATA表示元素中可以同时出现文本和元素-->
<!ELEMENT age (#PCDATA) >
<!ELEMENT addr (#PCDATA) >
]>
<users>
<user>
<name>zhangsan</name>
<age>23</age>
<addr>shanghai</addr>
<!-- 报错:The content of element type "user" must match "(name,age,addr)". -->
<sex>男</sex>
</user>
<!-- 报错:The content of element type "users" must match "(user)+". -->
<user1>
<name>lisi</name>
<age>24</age>
<addr>beijing</addr>
</user1>
</users>-
在xml文档中引用一个外部的dtd约束文档(dtd约束文档以.dtd作用扩展名)
1)引用本地文件
<!DOCTYPE users SYSTEM "./users.dtd">2)引用公共文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd"> 3.2、xml-shema约束
Schema它也来约束xml文件的,DTD在约束xml的时候一个xml中只能引入一个DTD,同时DTD它无法对属性以及标签中的数据做数据类型的限定。
Schema它是用来代替DTD来约束xml。Schema文件本身就是使用xml文件书写的,同时它对需要约束的xml中的数据有严格的限定。
要定义一个Schema文件,这时它的扩展名必须是.xsd。在这个文件中根元素必须是schema。
使用Schema来约束xml,Schema在书写的时候,只需要使用W3C组织提前定义的限定标签的,以及限定的属性的那个标签即可。
例如:
我们将上面的案例改用Schema来限定。
-
新建一个users.xsd文件
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3school.com.cn"
xmlns="http://www.w3school.com.cn"
elementFormDefault="qualified">
<!-- 使用命名空间的作用:在XML中,采用现成的,在全球范围唯一的“域名”作为Namespace,命名空间允许我们在一个文档中结合不同的元素和属性定义,并指明这些元素和属性的定义来自那里,其实就是为了区分而不至于同名冲突,类似于java中的包-->
<!-- xs:schema 表明schema中用到的元素和数据类型来自该URI的命名空间,
而且规定来自该命名空间的元素和数据类型应使用前缀xs,例如:<xs:element> -->
<!-- targetNamespace 表明此schema定义的元素来自该命名空间 -->
<!-- xmlns 默认命名空间 -->
<!-- elementFormDefault="qualified" 任何xml实例文档所使用的且在此schema中声明过的元素必须被命名空间限定 -->
<xs:element name="users">
<xs:complexType> <!-- 这是一个复杂元素 -->
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="user">
<xs:complexType>
<xs:sequence maxOccurs="1">
<xs:element name="name" type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
<xs:element name="addr" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
<!-- <sequence> 表明元素必须按照顺序出现,还可以是
<all> 元素的顺序可以任意。 但是元素出现的次数有且仅有一次。
<choice> 简单元素只能出现其中的一个。-->
<!--maxOccurs="unbounded" 最大次数不限,maxOccurs="1"最大次数1次-->-
新建一个users.xml文件
<?xml version="1.0"?>
<users
xmlns="http://www.w3school.com.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3school.com.cn users.xsd">
<!-- xmlns 默认命名空间的声明,在此xml文档中使用过的所有元素都被声明于该命名空间。 -->
<!-- xmlns:xsi 实例命名空间,只有有了xsi之后才能使用schemaLocation,该值提供了需要使用的命名空间 -->
<!-- xsi:schemaLocation 提供命名空间使用的xml schema的位置 -->
<user>
<name>zhangsan</name>
<age>23</age>
<addr>shanghai</addr>
</user>
<user>
<name>lisi</name>
<age>24</age>
<addr>beijing</addr>
</user>
</users>-
ref引用方式使用xsd
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3school.com.cn"
xmlns="http://www.w3school.com.cn"
elementFormDefault="qualified">
<xs:element name="users">
<xs:complexType> <!-- 这是一个复杂元素 -->
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="user">
<xs:complexType>
<xs:sequence maxOccurs="1">
<xs:element ref="name"/>
<xs:element ref="age"/>
<xs:element ref="addr"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="name" type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
<xs:element name="addr" type="xs:string"/>
</xs:schema>-
元素组方式
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3school.com.cn"
xmlns="http://www.w3school.com.cn"
elementFormDefault="qualified">
<xs:element name="users">
<xs:complexType> <!-- 这是一个复杂元素 -->
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="user">
<xs:complexType>
<xs:group ref="testGrop"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:group name="testGrop">
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
<xs:element name="addr" type="xs:string"/>
</xs:sequence>
</xs:group>
</xs:schema>4、XML解析
4.1、XML解析概述
最初的xml解析器是sun的Crimson和IBM的Xerces,这两个开源项目都捐给了apache组织,后来Xerces发展很快,Crimon基本没有人使用。
1)早期JDK为我们提供了两种xml解析技术:DOM和Sax 。
W3C已于2000年11月13日推出了规范DOM level 2,DOM:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种方式,而几乎所有的编程语言都对这个解析技术使用了自己语言的特点进行了实现。Sun公司在jdk1.4(2002)中提供了DOM相应的java语言的实现(Sun公司在JDK5时对Dom解析技术进行了升级:SAX(Simple API for XML))。
2)2004年发布VTD-XML0.5,2005年10月发布VTD- XML1.0,VTD-XML是一种无提取的XML 解析方法它较好的解决了DOM占用内存过大的缺点,并且还提供了快速的解析与遍历、对XPath的支持和增量更新等特性。
3)java发布JAXP(The Java API For XML Processing)
它是J2SE的一部分,是XML解析转换验证查询API,由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
4)JDK6(2006年12月)时又发布了JAXB2.0(Java Architecture for XML Binding)和StAX(Streaming API for XML)
JAXB2.0,允许Java开发人员将Java类映射为XML表示方式。StAX,它能够从应用程序的stream对象解析XML数据,是一个用Java实现的XML拉式解析器。
5)优秀的三方解析包:JDOM、DOM4J
有人觉得W3C的DOM标准API比较复杂,而Sun公司的JAXP又不够完善,于是有人开发Java专用的XML API,就是JDOM(java+DOM),所以呢JDOM是在DOM基础上进行了封装,所以采用许多Java语言的优秀特性,比如方法重载、集合(Collections)和类映射(Reflection)。
由于JDOM的开发人员出现了分歧,DOM4J由JDOM的一批开发人员所研发,DOM4J又是对jdom进行了封装。DOM4J(Document Object Model For Java)因For与Four同音,被称为DOM4J。
根据从XML中获取数据的简易性,性能和最终所得到的数据模型的不同,XML解析技术大致可分为以下四类:
1) 面向文档的对象式解析;主要有:DOM解析、JDOM
2) 面向文档的流式解析;主要有:推式解析(SAX)和拉式解析(StAX)
3) 面向文档的指针式解析;主要有:VTD(Virtual Token Descriptor,虚拟令牌描述符)-XML
4) 面向应用的对象式解析;如:DOM4J、JAXB(JDK中的API)
4.2、DOM 解析 XML
DOM解析是一个基于对象的API,它把XML的内容加载到内存中,生成与XML文档内容对应的模型!当解析完成,内存中会生成与XML文档的结构与之对应的DOM对象树,这样就能够根据树的结构,以节点的形式对文档进行操作!所以, DOM 解析方式的优点是对文档的cud(增删改)比较方便,缺点是占用内存比较大。
适用范围:小型 XML 文件解析、需要全解析或者大部分解析 XML、需要修改 XML 树内容以生成自己的对象模型。
DOM解析核心操作接口:Document(整个文档)、Node(节点)、NodeList...
使用案例:
解析如下:xml
<?xml version="1.0" encoding="UTF-8" ?>
<china>
<province>
<jiangxi id="a1">江西</jiangxi>
<beijing id="a2">北京</beijing>
</province>
</china>源码:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringWriter;
import java.io.Writer;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Result;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomTestDemo {
/**
* @param args
* @throws ParserConfigurationException
* @throws IOException
* @throws SAXException
*/
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
//API规范:需要用一个工厂来造解析器对象,于是我先造了一个工厂!
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
//获取解析器对象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
//获取到解析XML文档的流对象
InputStream inputStream = DomTestDemo.class.getClassLoader().getResourceAsStream("city.xml");
//解析XML文档,得到了代表XML文档的Document对象!
Document document = documentBuilder.parse(inputStream);
//遍历文档
list(document);
//添加属性
addAttr(document);
}
/**
* 遍历标签
* @param node
*/
private static void list(Node node) {
// 只打印标签
if (node instanceof Element) {
System.out.println(node.getNodeName());
}
NodeList list = node.getChildNodes();
for (int i = 0; i < list.getLength(); i++) {
Node child = list.item(i);
list(child);
}
}
/**
* 添加属性
* @param document
* @throws Exception
*/
public static void addAttr(Document document) throws Exception{
//获取document指定节点
Element province = (Element) document.getElementsByTagName("jiangxi")
.item(0);
//更新dom
province.setAttribute("JC", "赣");
//把更新后内存中的dom写到xml文档中
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer();
StreamResult result = new StreamResult(new FileOutputStream("src/city.xml"));
DOMSource source = new DOMSource(document);
//将内存中的document对象输出到result中
transformer.transform(source, result);
//输出更新后的dom
printXml(source);
}
/**
* 输出Dom
* @param source
* @throws Exception
*/
public static void printXml(DOMSource source) throws Exception{
Writer sw = new StringWriter();
//使用StringWriter对象去接收内存中的dom对象
Result result = new StreamResult(sw);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer transformer = tf.newTransformer();
//将source输出到result的StringWriter对象中
transformer.transform(source, result);
System.out.println(sw.toString());
}
}案例效果:

4.3、SAX解析 XML
SAX(Simple API for XML)解析技术就是一种推式解析。在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。它是如何做的呢?SAX提供了一个用于处理XML的,基于事件驱动的简单API。当SAX解析器进行操作时,会触发一系列事件SAX。解析器在发现xml文档中的内容时就告诉你如何处理这些内容,处理的方式由使用者决定。
下面通过案例来说明:
import java.io.InputStream;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxTestDemo {
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
//要得到解析器对象就需要造一个工厂,于是我造了一个工厂
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
//获取到解析器对象
SAXParser saxParse = saxParserFactory.newSAXParser();
//SAXParser提供了很多构造方法:这里要求我们使用一个DefaultHandler对象
//1、parse(InputStream is, HandlerBase hb) HandlerBase已经过时已经被 SAX2 DefaultHandler取代
//2、parse(InputStream is, DefaultHandler dh)
//3、...
InputStream inputStream = SaxTestDemo.class.getClassLoader().getResourceAsStream("city.xml");
saxParse.parse(inputStream,new ListHander(false,null));
//遍历指定节点
InputStream inputStream2 = SaxTestDemo.class.getClassLoader().getResourceAsStream("city.xml");
saxParse.parse(inputStream2,new ListHander(true,"jiangxi"));
}
}
/**
* 创建一个ListHander类继承DefaultHandler
* 重写DefaultHandler中的方法
* startDocument()
* endDocument()
* startElement(...)
* endElement(...)
* characters(...)
* @author Administrator
*
*/
class ListHander extends DefaultHandler {
boolean flag = false;
String name = null;
boolean contFlag = false;
/**
* 是否遍历指定标签
* @param flag
* @param name
*/
public ListHander(Boolean flag,String name){
this.flag = flag;
this.name = name;
}
@Override
public void startDocument() throws SAXException {
System.out.println("我开始来扫描!!!!");
}
@Override
public void endDocument() throws SAXException {
System.out.println("我结束了!!!!");
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
//输出节点的名字!
if (flag) {
if(name!=null && name.equals(qName)){
contFlag = true;
System.out.println("startElement="+qName);
}
}else{
contFlag = false;
System.out.println("startElement="+qName);
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (flag) {
if(name!=null && name.equals(qName)){
System.out.println("endElement="+qName);
contFlag = false;
}
}else{
System.out.println("endElement="+qName);
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
//输出文本的内容
if (flag) {
if(contFlag){
System.out.println("characters="+new String(ch,start,length));
}
}else{
System.out.println("characters="+new String(ch,start,length));
}
}
}输出结果:
我开始来扫描!!!!
startElement=china
characters=
startElement=province
characters=
startElement=jiangxi
characters=江西
endElement=jiangxi
characters=
startElement=beijing
characters=北京
endElement=beijing
characters=
endElement=province
characters=
endElement=china
我结束了!!!!
我开始来扫描!!!!
startElement=jiangxi
characters=江西
endElement=jiangxi
我结束了!!!!从上面的案例输出结果,我们不难发现,流式解析产生一个对应的事件流,并向事件处理程序发送所捕获的各种事件。虽然我们可以过滤获得我们自己所需的数据,但是并没有提供我们终止继续获取的方法。进而又出现了一种叫StAX(Streaming API for XML)解析技术,是一种拉式解析,并且可随时停止解析。StAX也是用Java定义的,其StAX1.0于2004年3月发布,并且成为了JSR-173 规范。
4.4、DOM4J
DOM缺点,比较耗费内存。sax缺点,只能对xml文件进行读取。而DOM4J既可以提高效率,同时也可以进行crud操作。DOM4J是dom4j.org开源XML解析包,可以在这里下载(dom4j)。注:(需要导入依赖包:dom4j-1.6.1.jar)
常用的API:
| 常用API | API描述 |
|---|---|
| org.dom4j.io.SAXReader | 获取解析器,read 提供读取xml文件的方式,返回一个Domcument对象 |
| org.dom4j.Document | getRootElement 获取根节点,iterator遍历node |
| org.dom4j.Node | getName/getNodeType/getNodeTypeName |
| org.dom4j.Element | attributes/attributeValue/elementIterator/elements |
| org.dom4j.Attribute | getName/getValue 获取属性名/值 |
| org.dom4j.Text | getText获取Text节点值 |
| org.dom4j.CDATA | getText 获取CDATA Section值 |
| org.dom4j.Comment | getText 获取注释 |
4.4.1、遍历
import java.io.InputStream;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jTestDemo1 {
public static void main(String[] args) throws DocumentException {
//获取到解析器
SAXReader saxReader = new SAXReader();
//获取到XML文件的流对象
InputStream inputStream = Dom4jTestDemo1.class.getClassLoader().getResourceAsStream("city.xml");
//通过解析器读取XML返回Document对象
Document document = saxReader.read(inputStream);
//打印document对象
System.out.println(document.asXML());
//获取根节点
Element root = document.getRootElement();
//System.out.println("根节点路径:"+root.getPath()+":"+root.getTextTrim());
//遍历指定根节点开始遍历
getElement(root);
//指定开始节点
//getElement(root.element("province"));
}
@SuppressWarnings("rawtypes")
public static void getElement(Element element) {
//获取到子元素集合
List elements = element.elements();
//没有子元素
if (elements.isEmpty()) {
System.out.println(element.getPath()+":"+element.getTextTrim());
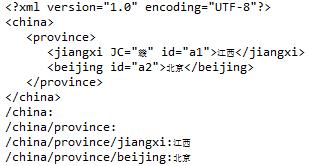
}else {
//输出当前元素
System.out.println(element.getPath()+":"+element.getTextTrim());
//当前元素如有子元素则递归遍历
for (Iterator it = elements.iterator(); it.hasNext();) {
Element elem = (Element) it.next();
getElement(elem);
}
}
}
}案例效果:
4.4.2、修改
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
public class Dom4jTestDemo2 {
public static void main(String[] args) throws DocumentException, IOException {
// TODO Auto-generated method stub
//获取到解析器
SAXReader saxReader = new SAXReader();
//获取到XML文件的流对象
InputStream inputStream = Dom4jTestDemo1.class.getClassLoader().getResourceAsStream("city.xml");
//通过解析器读取XML返回Document对象
Document document = saxReader.read(inputStream);
//得到需要添加的父节点
Element need = document.getRootElement().element("province");
//创建出新的节点
Element newElement1 = DocumentHelper.createElement("shanghai");
newElement1.setText("上海");
Element newElement2 = DocumentHelper.createElement("wuhan");
newElement2.setText("武汉");
need.add(newElement1);
need.add(newElement2);
//打印document对象
//System.out.println(document.asXML());
//创建带有格式的对象
OutputFormat outputFormat = OutputFormat.createPrettyPrint();
outputFormat.setEncoding("UTF-8");
XMLWriter xmlWriter = new XMLWriter(new FileWriter("./src/city2.xml"), outputFormat);
//XMLWriter对象写入的是document
xmlWriter.write(document);
xmlWriter.close();
System.out.println(document.asXML());
//删除节点
Element wuhan = document.getRootElement().element("province").element("wuhan");
wuhan.getParent().remove(wuhan);
//打印document对象
System.out.println(document.asXML());
}
}4.4.3、XPath强大的导航
使用dom4j的时候,要获取某个节点,都是通过根节点开始,一层一层地往下寻找,这样确实麻烦。dom4j中XPath表达式可以评估的文件或树中的任何节点。(注:需要导入依赖包jaxen-1.1.6.jar)
import java.io.InputStream;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
public class Dom4jTestDemo3 {
@SuppressWarnings("rawtypes")
public static void main(String[] args) throws DocumentException {
//获取到解析器
SAXReader saxReader = new SAXReader();
//获取到XML文件的流对象
InputStream inputStream = Dom4jTestDemo1.class.getClassLoader().getResourceAsStream("city.xml");
//通过解析器读取XML返回Document对象
Document document = saxReader.read(inputStream);
//前面我们遍历以及修改Document对象都需要获取对应的跟节点
List list = document.selectNodes( "//china/province");
for ( Iterator i = list.iterator(); i.hasNext(); ) {
Element element = (Element) i.next();
getElement(element);
}
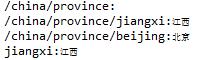
Node node = (Node)document.selectSingleNode("/china/province/jiangxi");
System.out.println(node.getName()+":"+node.getText());
}
@SuppressWarnings("rawtypes")
public static void getElement(Element element) {
List elements = element.elements();
//没有子元素
if (elements.isEmpty()) {
System.out.println(element.getPath()+":"+element.getTextTrim());
}else {
//输出当前元素
System.out.println(element.getPath()+":"+element.getTextTrim());
//当前元素如有子元素则递归遍历
for (Iterator it = elements.iterator(); it.hasNext();) {
Element elem = (Element) it.next();
getElement(elem);
}
}
}
}案例效果:
以上是关于JavaWeb入门详解(第二篇)之xml简介的主要内容,如果未能解决你的问题,请参考以下文章