Spark学习笔记5:Spark集群架构
Posted CAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习笔记5:Spark集群架构相关的知识,希望对你有一定的参考价值。
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力。Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立集群管理器)上运行,所以Spark应用既能够适应专用集群,又能用于共享的云计算环境。
- Spark运行时架构
Spark在分布式环境中的架构如下图:
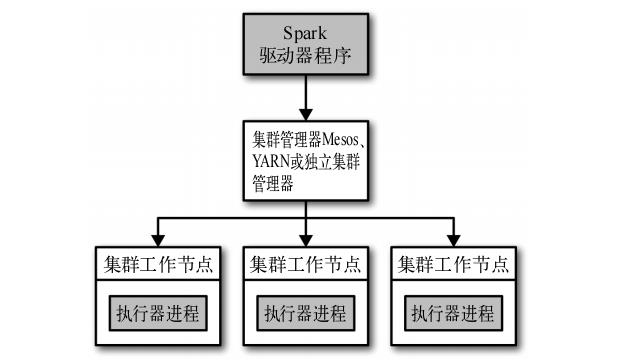
在分布式环境下,Spark集群采用的是主/从结构。在Spark集群,驱动器节点负责中央协调,调度各个分布式工作节点。执行器节点是工作节点,作为独立的Java进行运行,可以和大量的执行器节点进行通信,作为独立的Java进程运行。驱动器节点和所有的执行器节点一起被称为一个Spark应用。
Spark应用通过一个叫做集群管理器的外部服务在集群上的机器上启动。Spark自动的集群管理器称为独立集群管理器。Spark也能运行在Hadoop YARN和Apache Mesos两大开源集群管理器上。
详细说明驱动器节点和执行器节点的作用:
1、驱动器节点
Spark驱动器是执行程序中main()方法的进程。它执行用户编写的用来创建SparkContext ,创建RDD,以及进行RDD转化操作和行动操作的代码。
驱动器进程在Spark应用中有以下两个职责:
- 把用户程序转为任务
Spark驱动器程序负责把用户程序转为多个物理执行的单元,这些单元称为任务。任务是Spark中最小的工作单元,用户程序通常要启动成百上千的独立任务。
- 为执行器节点调度任务
Spark驱动器在各执行器进程间协调任务的调度,驱动器进程对应用中所有的执行器节点有完整的记录。每个执行器节点代表一个能够处理任务和存储RDD数据的进程。
2、执行器节点
Spark执行器节点是一种工作进程,负责在Spark作业中运行任务,任务间相互独立。执行器节点在Spark应用启动时启动,伴随着整个Spark应用的生命周期而存在。
执行器节点负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
执行器节点通过自身的块管理器为用户程序中要求缓存的RDD提供内存式存储。
- spark-submit部署应用
使用Spark提供的统一脚本spark-submit将应用提交到集群管理器上。
spark-submit提供了各种选项可以控制应用每次运行的各项细节。这些选项分为两类:第一类是调度信息,比如你希望为作业申请的资源量。第二类是应用的运行时依赖,比如需要部署到所有工作节点的库和文件。
spark-submit的一般格式:
bin/spark-submit [options] <app jar | python file> [app options]
[options]是要传给spark-submit的标记列表,运行spark-submit --help 可以列出所有可以接收的标记。
<app jar | python file>表示包含应用入口的JAR包或Python脚本。
[app options]是传给应用的选项。
spark-submit一些常用的标记如下:

- 使用Maven依赖
<properties>
<scala.version>2.10.4</scala.version>
<spark.version>1.6.3</spark.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- JDBC -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
</dependencies>
- Spark应用内与应用间调度
在调度多用户集群时,Spark主要依赖集群管理器来在Saprk应用间共享资源。Spark内部的公平调度器会让长期运行的应用定义调度任务的优先级队列。
以上是关于Spark学习笔记5:Spark集群架构的主要内容,如果未能解决你的问题,请参考以下文章