学习笔记Spark—— Spark架构及原理
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Spark—— Spark架构及原理相关的知识,希望对你有一定的参考价值。
一、Spark架构
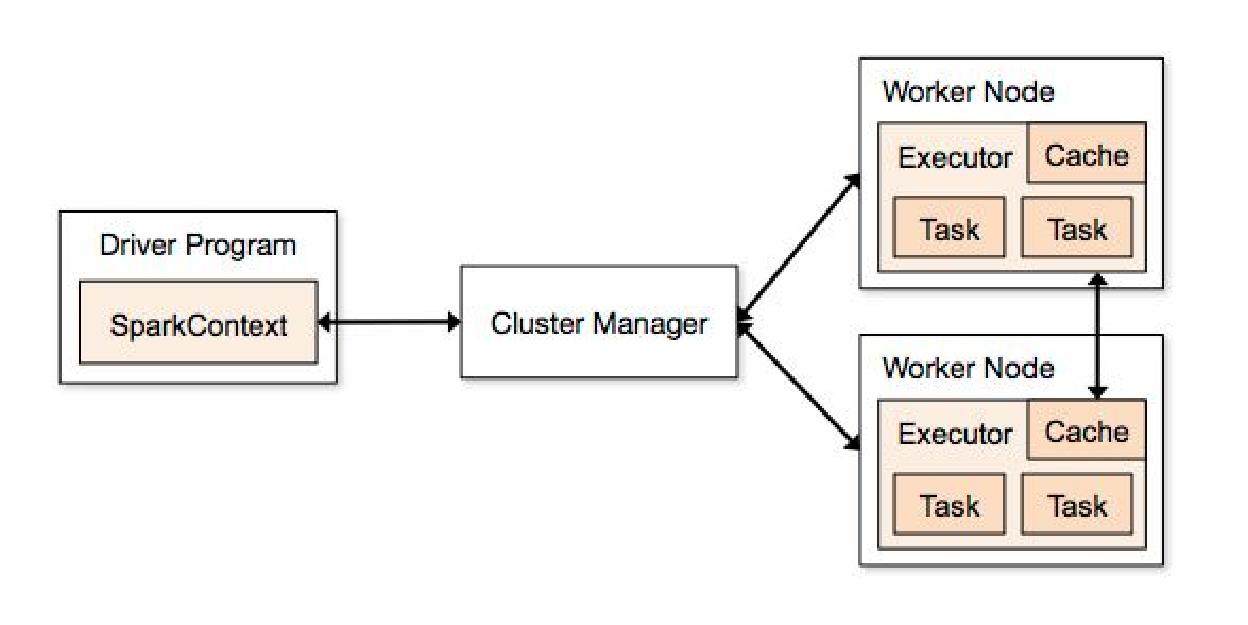
1.1、基本组件
Cluster Manager
在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器。
Worker
从节点,负责控制计算节点,启动Executor或者Driver。在YARN模式中为NodeManager,负责计算节点的控制。
Driver
运行Application的main()函数并创建SparkContext。
Executor
执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
SparkContext
整个应用的上下文,控制应用的生命周期,主要包括:
RDD Objects(RDD DAG):构建DAG图;
DAG Scheduler:根据作业(task)构建基于Stage的DAG,并提交Stage给TaskSchedule;
TaskScheduler:将任务(task)分发给Executor执行。
1.2、Standalone模式运行流程
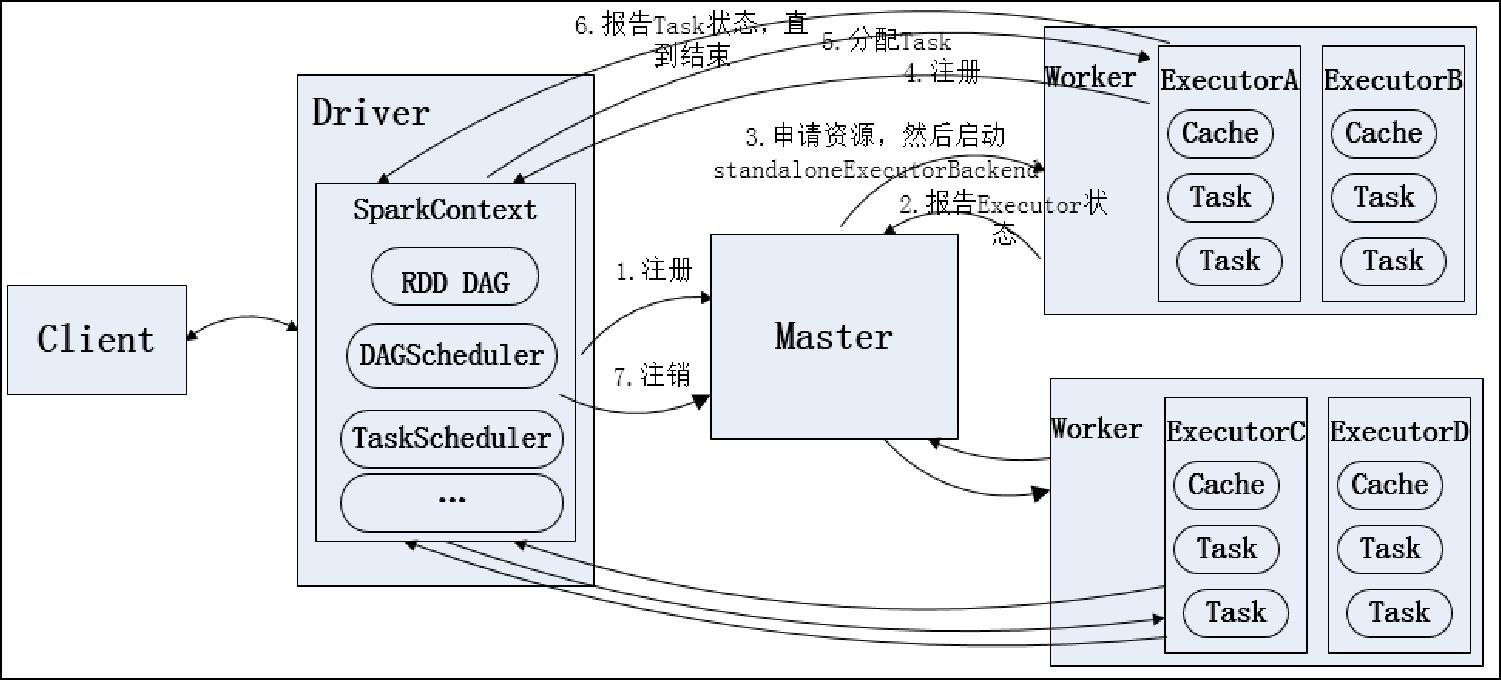
Client:客户端,负责提交Application应用程序
Application:用户编写的Spark应用程序,包含一个Driver功能的代码
Driver:运行Application代码里的main函数并创建SparkContext
SparkContext:应用上下文,控制整个生命周期。负责和Master通信,进行资源申请、分配任务等。
1、SparkContext向Master注册并申请资源
2、Master接收到SparkContext的资源申请要求,根据Worker的心跳周期内的报告信息决定在哪个Worker上分配资源
3、Worker获取到资源后,启动Executor,Executor启动后向SparkContext注册并申请分配任务
4、SparkContext接收到Executor的任务申请后,SparkContext将Application代码发送给Executor并自身解析Application代码构建RDD DAG图,DAGScheduler将DAG划分成一个或多个Stage,Stage根据Partition个数分成一个多个Task并形成TaskSet同时发送给TaskScheduler。TaskScheduler将Task分配到相应的Worker,最后提交给Executor执行。
5、Executor接收到Task之后运行Task并SparkContext汇报任务状态和进度,直到Task运行完成
所有Task运行完成后,SparkContext向Master注销,释放资源
1.3、Spark on YARN
1.3.1、yarn-cluster运行流程
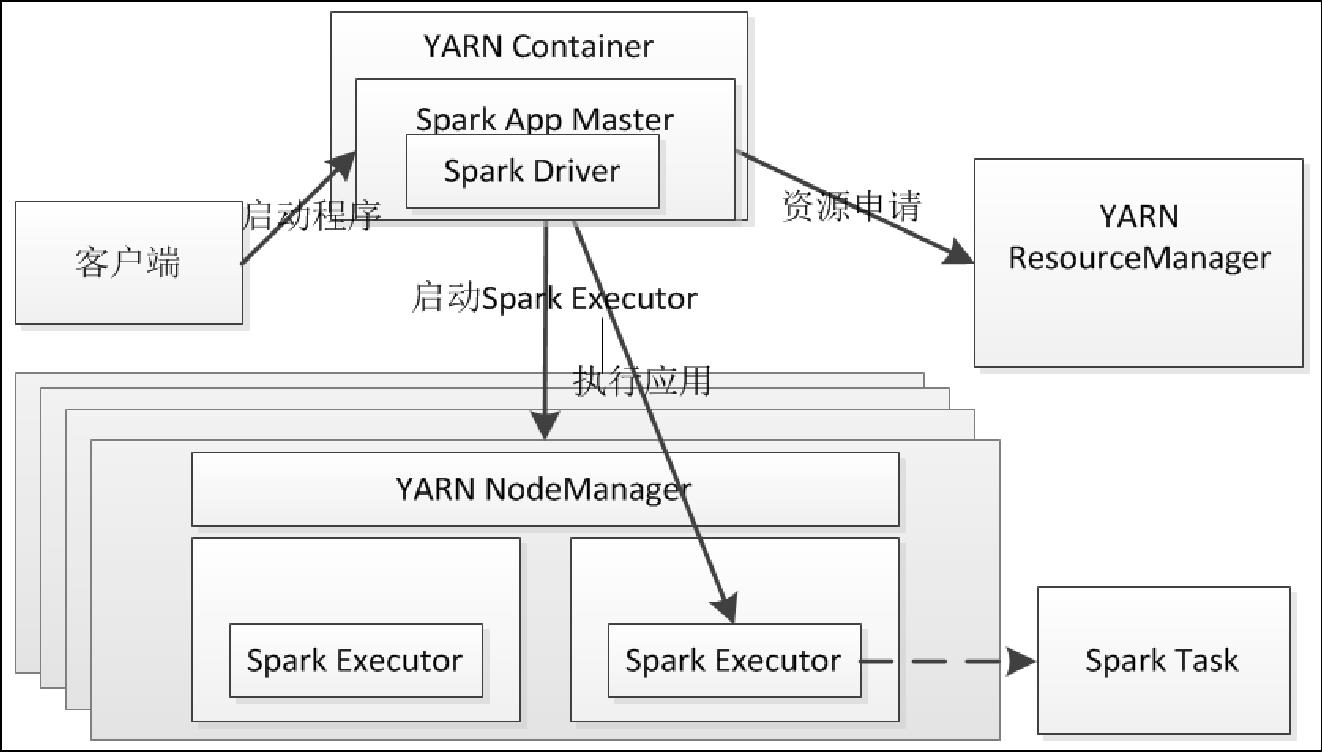
在集群模式下,Driver运行在Application Master上,Application Master进程同时负责驱动Application和从YARN中申请资源,该进程运行在YARN container内,所以启动Application Master的Client可以立即关闭而不必持续到Application的声明周期。图 1‑18是YARN集群模式的作业运行流程,流程描述如下:
- 客户端生成作业信息提交给ResourceManager。
- ResourceManager在某一个NodeManager(由YARN决定)启动container并将Application Master分配给该NodeManager。
- NodeManager接收到ResourceManager的分配,启动Application Master并初始化作业,此时NodeManager就称为Driver。
- Application向ResourceManager申请资源,分配资源同时通知其他NodeManager启动相应的Executor。
- Executor向NodeManager上的Application Master注册汇报并完成相应的任务。
1.3.2、yarn-client运行流程
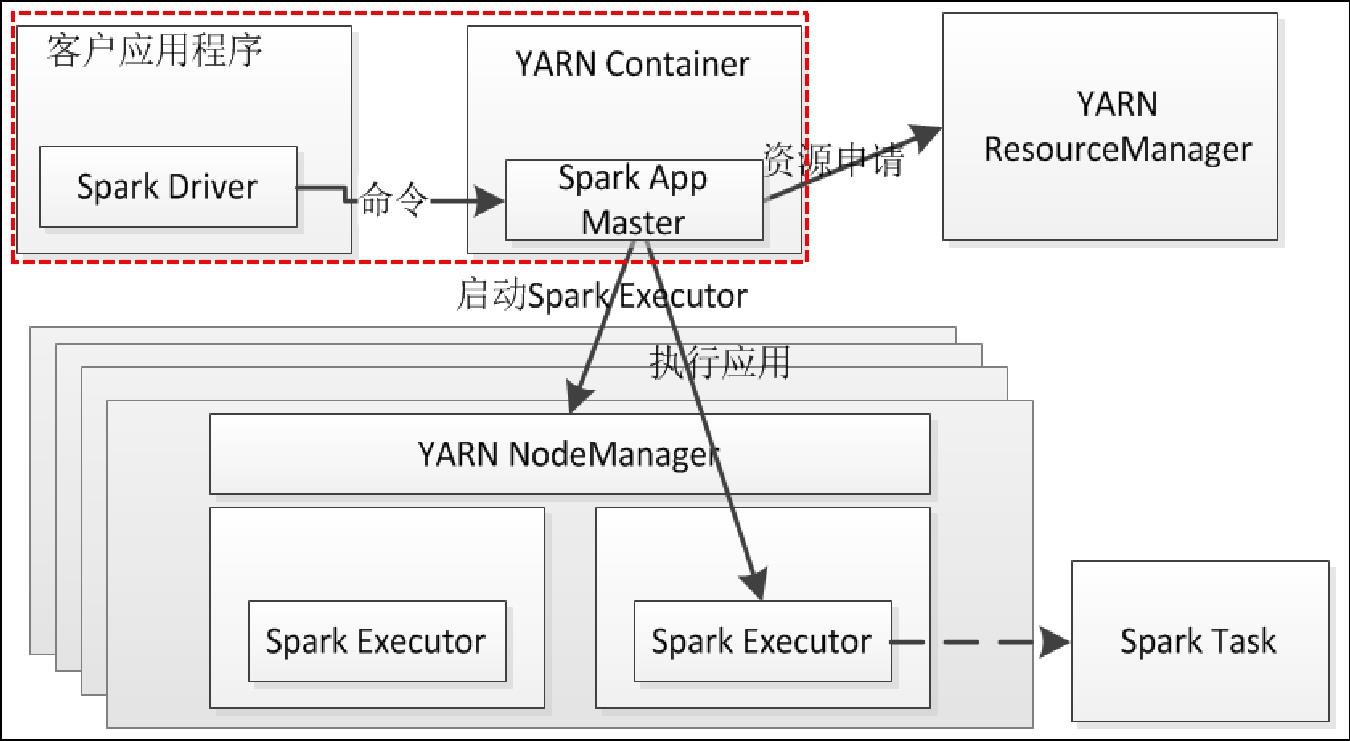
YARN客户端模式的作业运行流程。Application Master仅仅从YARN中申请资源给Executor,之后Client会跟container通信进行作业的调度。YARN-Client模式的作业运行流程描述如下:
- 客户端生成作业信息提交给ResourceManager。
- ResourceManager在本地NodeManager启动Container并将Application Master分配给该NodeManager。
- NodeManager接收到ResourceManager的分配,启动Application Master并初始化作业,此时这个NodeManager就称为Driver。
- Application向ResourceManager申请资源,分配资源同时通知其他NodeManager启动相应的Executor。
- Executor向本地启动的Application Master注册汇报并完成相应的任务。
二、Spark RDD
2.1、RDD简介
RDD(Resilient Distributed Datasets弹性分布式数据集),可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)
RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。
RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
2.2、RDD 特点
- 它是集群节点上的不可改变的、已分区的集合对象;
- 通过并行转换的方式来创建如(map、filter、join等);
- 失败自动重建;
- 可以控制存储级别(内存、磁盘等)来进行重用;
- 必须是可序列化的;在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能有大的下降但不会差于现在的MapReduce;
- 对于丢失部分数据分区只需要根据它的lineage就可重新计算出来,而不需要做特定的checkpoint;
注意:
① RDD一旦创建就不可更改
② 重建不是从最开始的点来重建的,可以是上一步开始重建
2.3、算子

(了解)
转换(Transformations)(如:map、Filter、groupby、join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算
操作(Actions)(如:count、collect、save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计划的动因。
2.4、宽依赖与窄依赖
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
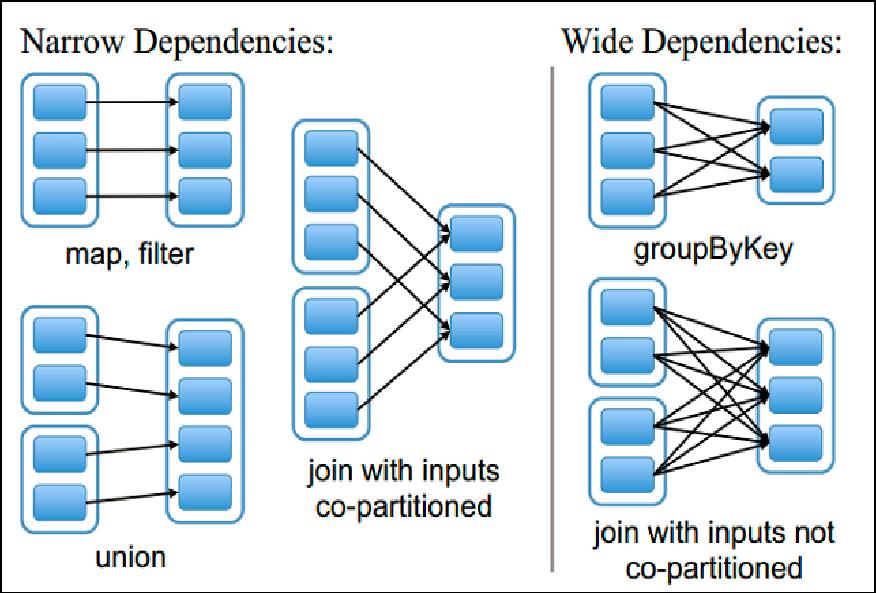
图中的每个小方格代表一个分区,而一个大方格(比如包含3个或2个小方格的大方格)代表一个RDD,竖线左边显示的是窄依赖,而右边是宽依赖。
要知道宽窄依赖的区别,那么先要了解父RDD(Parent RDD)和子RDD(Child RDD)。在上图中,“map,filter”左上面的是父RDD,而右上面的是子RDD。“union”左上面的两个RDD都是其右上面的RDD的父RDD,所以它是有两个父RDD的。
以上是关于学习笔记Spark—— Spark架构及原理的主要内容,如果未能解决你的问题,请参考以下文章