sqoop学习
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqoop学习相关的知识,希望对你有一定的参考价值。
sqoop 大概样例
sqoop import --connect jdbc:oracle:thin:@//XXXX.XXXX.XXXX.XXXX:1531/BDC --username DATAREPORT --password datareport --table NW_AGG_FLIGHT_ALL_DATE --hbase-create-table --hbase-table TEST_LAB:NW_AGG_FLIGHT_ALL_DATE --column-family CF --hbase-row-key "FLIGHT_DT,ORI_ENG,DES_ENG,CARRIER,FLIGHT_NO" --split-by flight_dt -m 4 --where " flight_dt = ‘2017-01-01‘"
连接串servicename 用/ SID用: 用户名,表名,ROW-KEY的字段名(不含null)等用大写
相关参数说明
其他参数说明
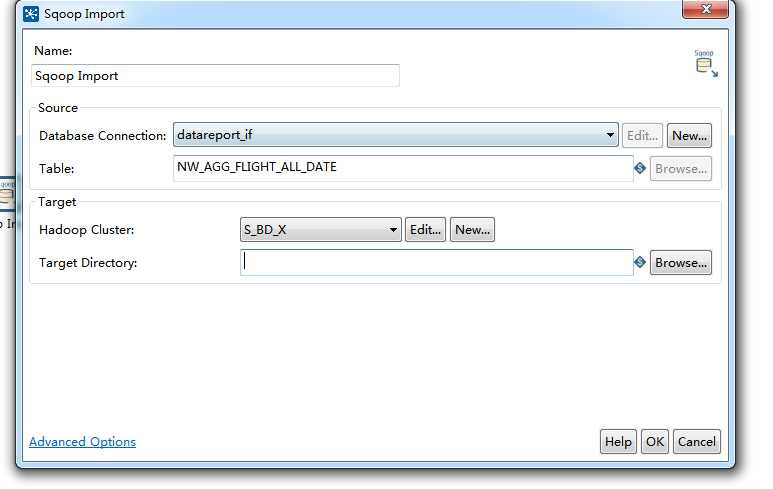
具体设置可以在Advanced Options中选择填写,能够生成相关的命令行
kettle执行 会遇到跨平台错误
需要在D:\\Program Files\\kettle710\\data-integration\\plugins\\pentaho-big-data-plugin\\hadoop-configurations\\cdh57中的mapred-site.xml里增加跨平台支持
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>