Sqoop学习之路
Posted 常生果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sqoop学习之路相关的知识,希望对你有一定的参考价值。
正文
一、概述
sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。
核心的功能有两个:
导入、迁入
导出、迁出
导入数据:mysql,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论。
sqoop:
工具:本质就是迁移数据, 迁移的方式:就是把sqoop的迁移命令转换成MR程序
hive
工具,本质就是执行计算,依赖于HDFS存储数据,把SQL转换成MR程序
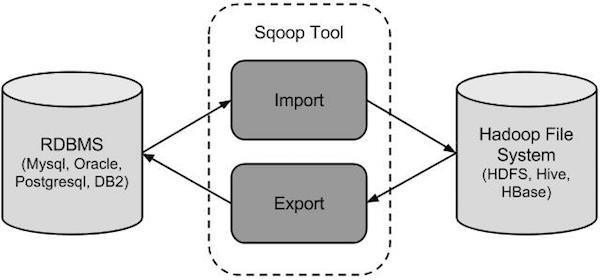
二、工作机制
将导入或导出命令翻译成 MapReduce 程序来实现 在翻译出的 MapReduce 中主要是对 InputFormat 和 OutputFormat 进行定制
三、安装
1、前提概述
将来sqoop在使用的时候有可能会跟那些系统或者组件打交道?
HDFS, MapReduce, YARN, ZooKeeper, Hive, HBase, MySQL
sqoop就是一个工具, 只需要在一个节点上进行安装即可。
补充一点: 如果你的sqoop工具将来要进行hive或者hbase等等的系统和MySQL之间的交互
你安装的SQOOP软件的节点一定要包含以上你要使用的集群或者软件系统的安装包
补充一点: 将来要使用的azakban这个软件 除了会调度 hadoop的任务或者hbase或者hive的任务之外, 还会调度sqoop的任务
azkaban这个软件的安装节点也必须包含以上这些软件系统的客户端/2、
2、软件下载
下载地址http://mirrors.hust.edu.cn/apache/

sqoop版本说明
绝大部分企业所使用的sqoop的版本都是 sqoop1
sqoop-1.4.6 或者 sqoop-1.4.7 它是 sqoop1
sqoop-1.99.4----都是 sqoop2
此处使用sqoop-1.4.6版本sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
3、安装步骤
(1)上传解压缩安装包到指定目录
因为之前hive只是安装在hadoop3机器上,所以sqoop也同样安装在hadoop3机器上
[hadoop@hadoop3 ~]$ tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C apps/
(2)进入到 conf 文件夹,找到 sqoop-env-template.sh,修改其名称为 sqoop-env.sh cd conf

[hadoop@hadoop3 ~]$ cd apps/ [hadoop@hadoop3 apps]$ ls apache-hive-2.3.3-bin hadoop-2.7.5 hbase-1.2.6 sqoop-1.4.6.bin__hadoop-2.0.4-alpha zookeeper-3.4.10 [hadoop@hadoop3 apps]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop-1.4.6 [hadoop@hadoop3 apps]$ cd sqoop-1.4.6/conf/ [hadoop@hadoop3 conf]$ ls oraoop-site-template.xml sqoop-env-template.sh sqoop-site.xml sqoop-env-template.cmd sqoop-site-template.xml [hadoop@hadoop3 conf]$ mv sqoop-env-template.sh sqoop-env.sh
(3)修改 sqoop-env.sh
[hadoop@hadoop3 conf]$ vi sqoop-env.sh
export HADOOP_COMMON_HOME=/home/hadoop/apps/hadoop-2.7.5 #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/home/hadoop/apps/hadoop-2.7.5 #set the path to where bin/hbase is available export HBASE_HOME=/home/hadoop/apps/hbase-1.2.6 #Set the path to where bin/hive is available export HIVE_HOME=/home/hadoop/apps/apache-hive-2.3.3-bin #Set the path for where zookeper config dir is export ZOOCFGDIR=/home/hadoop/apps/zookeeper-3.4.10/conf
为什么在sqoop-env.sh 文件中会要求分别进行 common和mapreduce的配置呢???
在apache的hadoop的安装中;四大组件都是安装在同一个hadoop_home中的
但是在CDH, HDP中, 这些组件都是可选的。
在安装hadoop的时候,可以选择性的只安装HDFS或者YARN,
CDH,HDP在安装hadoop的时候,会把HDFS和MapReduce有可能分别安装在不同的地方。
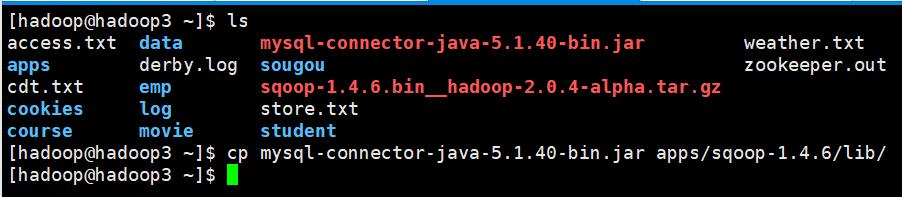
(4)加入 mysql 驱动包到 sqoop1.4.6/lib 目录下
[hadoop@hadoop3 ~]$ cp mysql-connector-java-5.1.40-bin.jar apps/sqoop-1.4.6/lib/
(5)配置系统环境变量
[hadoop@hadoop3 ~]$ vi .bashrc
#Sqoop export SQOOP_HOME=/home/hadoop/apps/sqoop-1.4.6 export PATH=$PATH:$SQOOP_HOME/bin

保存退出使其立即生效
[hadoop@hadoop3 ~]$ source .bashrc
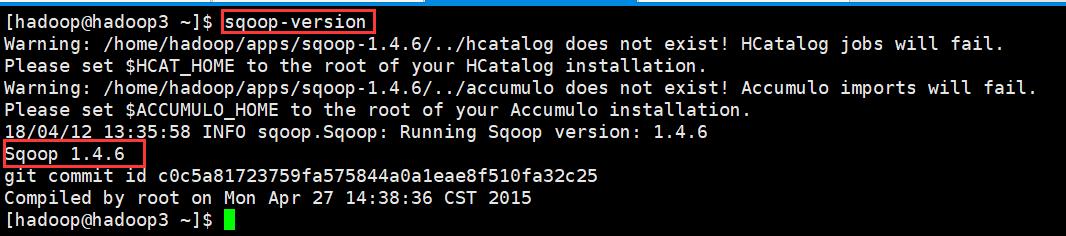
(6)验证安装是否成功
sqoop-version 或者 sqoop version
四、Sqoop的基本命令
基本操作
首先,我们可以使用 sqoop help 来查看,sqoop 支持哪些命令
[hadoop@hadoop3 ~]$ sqoop help Warning: /home/hadoop/apps/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /home/hadoop/apps/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. 18/04/12 13:37:19 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 usage: sqoop COMMAND [ARGS] Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information See 'sqoop help COMMAND' for information on a specific command. [hadoop@hadoop3 ~]$
然后得到这些支持了的命令之后,如果不知道使用方式,可以使用 sqoop command 的方式 来查看某条具体命令的使用方式,比如:
 View Code
View Code
示例
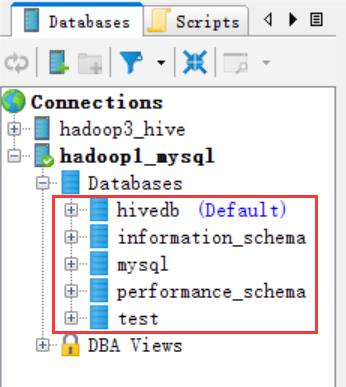
列出MySQL数据有哪些数据库
[hadoop@hadoop3 ~]$ sqoop list-databases \\ > --connect jdbc:mysql://hadoop1:3306/ \\ > --username root \\ > --password root Warning: /home/hadoop/apps/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /home/hadoop/apps/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. 18/04/12 13:43:51 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 18/04/12 13:43:51 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 18/04/12 13:43:51 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. information_schema hivedb mysql performance_schema test [hadoop@hadoop3 ~]$
列出MySQL中的某个数据库有哪些数据表:
[hadoop@hadoop3 ~]$ sqoop list-tables \\
> --connect jdbc:mysql://hadoop1:3306/mysql \\
> --username root \\
> --password root
View Code
创建一张跟mysql中的help_keyword表一样的hive表hk:
sqoop create-hive-table \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --hive-table hk
View Code
五、Sqoop的数据导入
“导入工具”导入单个表从 RDBMS 到 HDFS。表中的每一行被视为 HDFS 的记录。所有记录 都存储为文本文件的文本数据(或者 Avro、sequence 文件等二进制数据)
1、从RDBMS导入到HDFS中
语法格式
sqoop import (generic-args) (import-args)
常用参数
--connect <jdbc-uri> jdbc 连接地址 --connection-manager <class-name> 连接管理者 --driver <class-name> 驱动类 --hadoop-mapred-home <dir> $HADOOP_MAPRED_HOME --help help 信息 -P 从命令行输入密码 --password <password> 密码 --username <username> 账号 --verbose 打印流程信息 --connection-param-file <filename> 可选参数
示例
普通导入:导入mysql库中的help_keyword的数据到HDFS上
导入的默认路径:/user/hadoop/help_keyword
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ -m 1
View Code
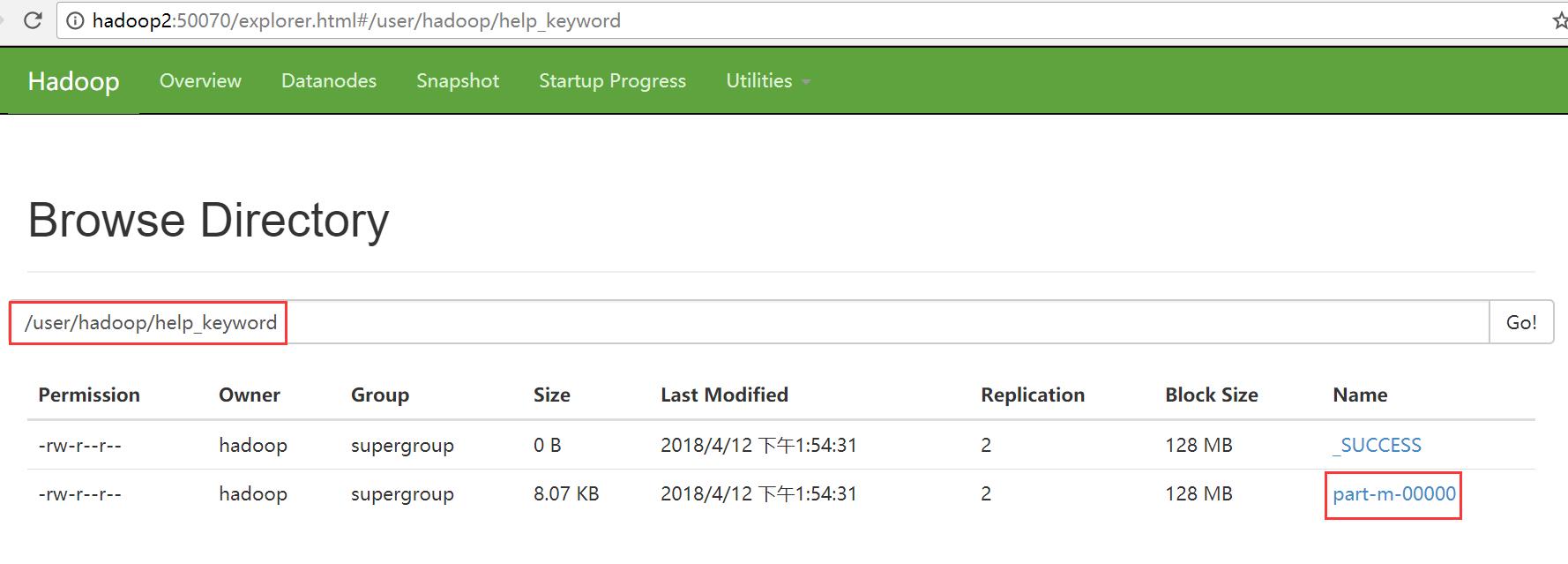
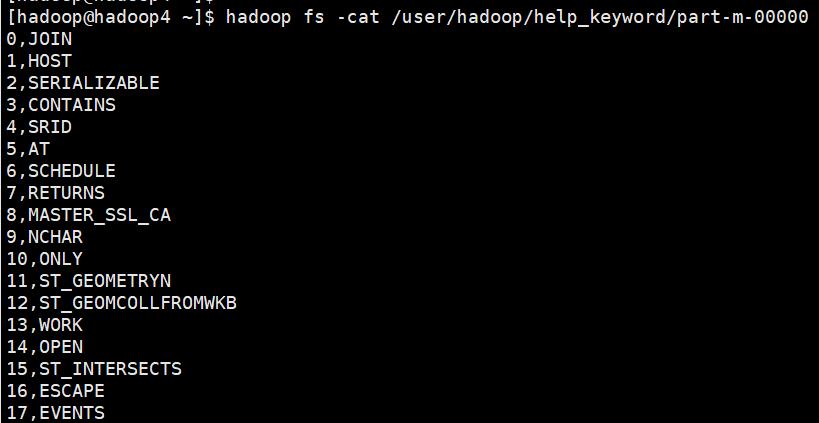
查看导入的文件
[hadoop@hadoop4 ~]$ hadoop fs -cat /user/hadoop/help_keyword/part-m-00000
导入: 指定分隔符和导入路径
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --target-dir /user/hadoop11/my_help_keyword1 \\ --fields-terminated-by '\\t' \\ -m 2
导入数据:带where条件
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --where "name='STRING' " \\ --table help_keyword \\ --target-dir /sqoop/hadoop11/myoutport1 \\ -m 1
查询指定列
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --columns "name" \\ --where "name='STRING' " \\ --table help_keyword \\ --target-dir /sqoop/hadoop11/myoutport22 \\ -m 1 selct name from help_keyword where name = "string"
导入:指定自定义查询SQL
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/ \\ --username root \\ --password root \\ --target-dir /user/hadoop/myimport33_1 \\ --query 'select help_keyword_id,name from mysql.help_keyword where $CONDITIONS and name = "STRING"' \\ --split-by help_keyword_id \\ --fields-terminated-by '\\t' \\ -m 4
在以上需要按照自定义SQL语句导出数据到HDFS的情况下:
1、引号问题,要么外层使用单引号,内层使用双引号,$CONDITIONS的$符号不用转义, 要么外层使用双引号,那么内层使用单引号,然后$CONDITIONS的$符号需要转义
2、自定义的SQL语句中必须带有WHERE \\$CONDITIONS
2、把MySQL数据库中的表数据导入到Hive中
Sqoop 导入关系型数据到 hive 的过程是先导入到 hdfs,然后再 load 进入 hive
普通导入:数据存储在默认的default hive库中,表名就是对应的mysql的表名:
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --hive-import \\ -m 1
导入过程
第一步:导入mysql.help_keyword的数据到hdfs的默认路径
第二步:自动仿造mysql.help_keyword去创建一张hive表, 创建在默认的default库中
第三步:把临时目录中的数据导入到hive表中
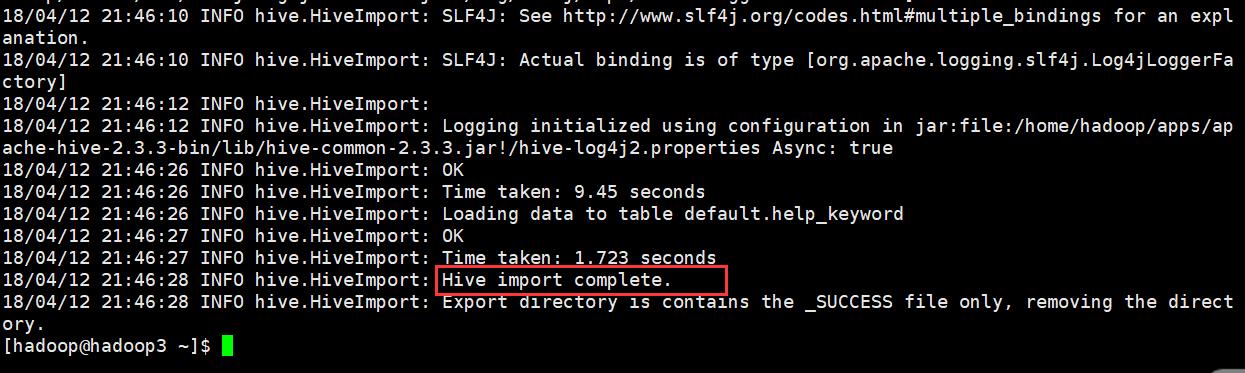
查看数据
[hadoop@hadoop3 ~]$ hadoop fs -cat /user/hive/warehouse/help_keyword/part-m-00000
指定行分隔符和列分隔符,指定hive-import,指定覆盖导入,指定自动创建hive表,指定表名,指定删除中间结果数据目录
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --fields-terminated-by "\\t" \\ --lines-terminated-by "\\n" \\ --hive-import \\ --hive-overwrite \\ --create-hive-table \\ --delete-target-dir \\ --hive-database mydb_test \\ --hive-table new_help_keyword
报错原因是hive-import 当前这个导入命令。 sqoop会自动给创建hive的表。 但是不会自动创建不存在的库
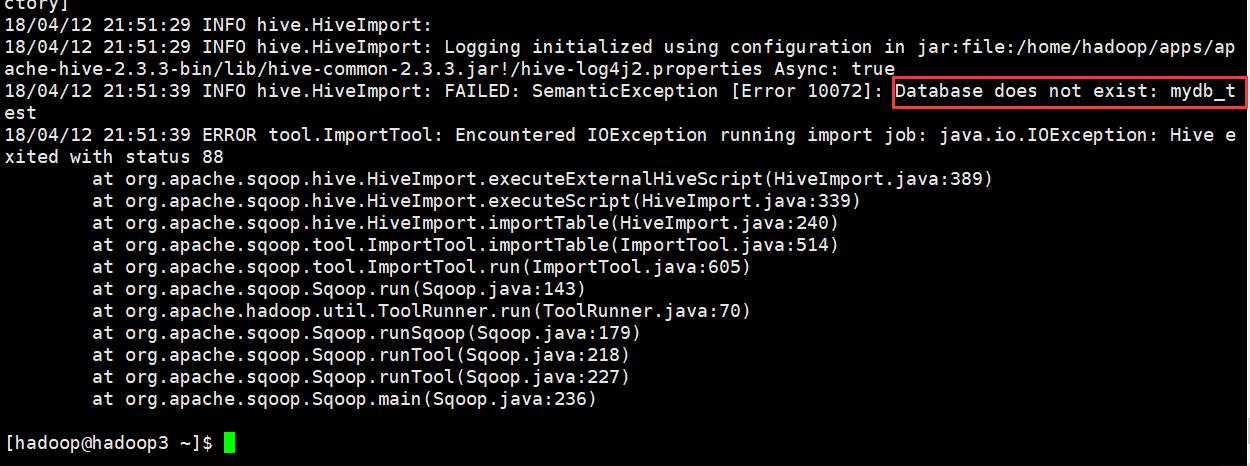
手动创建mydb_test数据块
hive> create database mydb_test; OK Time taken: 6.147 seconds hive>
之后再执行上面的语句没有报错
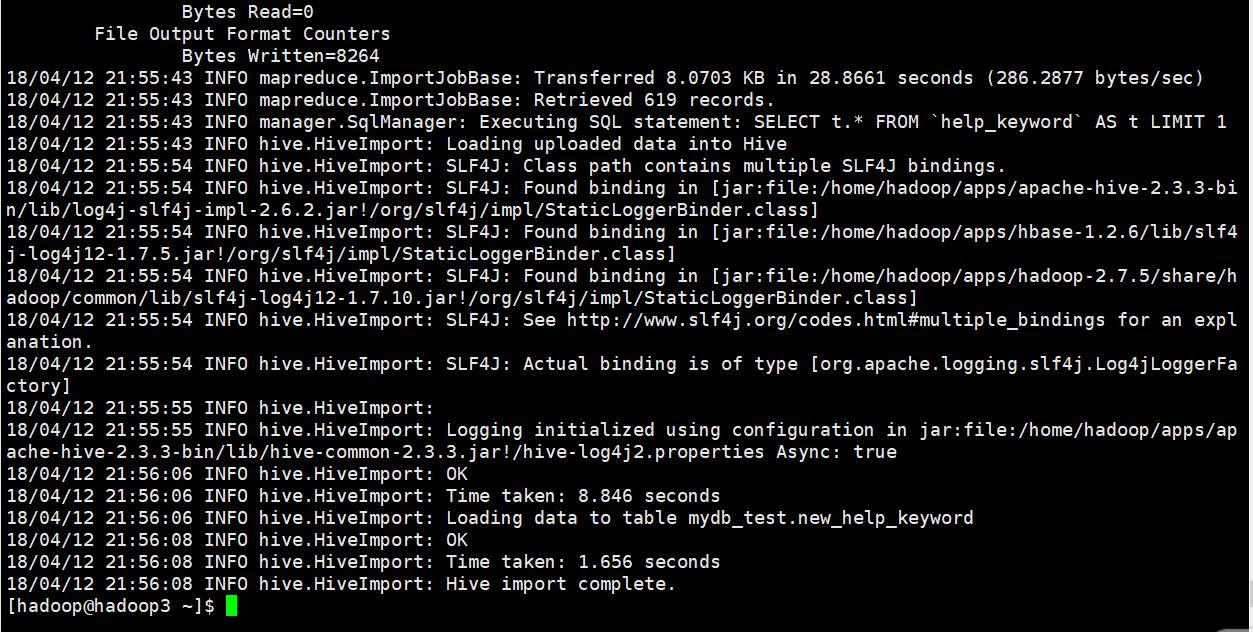
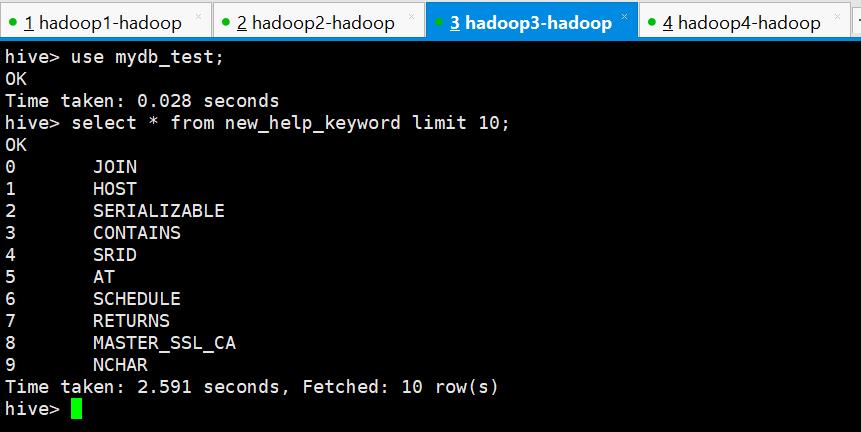
查询一下
select * from new_help_keyword limit 10;
上面的导入语句等价于
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --fields-terminated-by "\\t" \\ --lines-terminated-by "\\n" \\ --hive-import \\ --hive-overwrite \\ --create-hive-table \\ --hive-table mydb_test.new_help_keyword \\ --delete-target-dir
增量导入
执行增量导入之前,先清空hive数据库中的help_keyword表中的数据
truncate table help_keyword;
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --target-dir /user/hadoop/myimport_add \\ --incremental append \\ --check-column help_keyword_id \\ --last-value 500 \\ -m 1
语句执行成功
View Code
查看结果
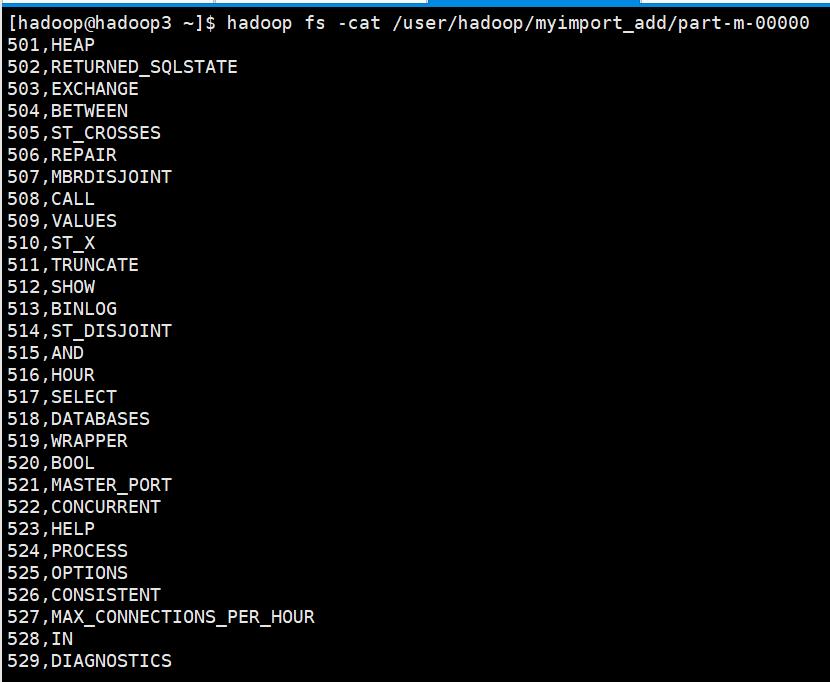
3、把MySQL数据库中的表数据导入到hbase
普通导入
sqoop import \\ --connect jdbc:mysql://hadoop1:3306/mysql \\ --username root \\ --password root \\ --table help_keyword \\ --hbase-table new_help_keyword \\ --column-family person \\ --hbase-row-key help_keyword_id
此时会报错,因为需要先创建Hbase里面的表,再执行导入的语句
hbase(main):001:0> create 'new_help_keyword', 'base_info' 0 row(s) in 3.6280 seconds => Hbase::Table - new_help_keyword hbase(main):002:0>
以上是关于Sqoop学习之路的主要内容,如果未能解决你的问题,请参考以下文章