聚类算法:K均值
Posted 追梦的独行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法:K均值相关的知识,希望对你有一定的参考价值。
在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
基本K均值:选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个簇。然后,根据指派到簇的点,更新每个簇的质心。重复指派和更新操作,直到质心不发生明显的变化。
为了定义二维空间的数据点之间的“最近”概念,我们使用欧几里得距离的平方,即点A(x1,y1)与点B(x2,y3)的距离为dist(A,B)=(x1-x2)2+(y1-y2)2。另外我们使用误差的平方和SSE作为全局的目标函数,即最小化每个点到最近质心的欧几里得距离的平方和。在设定该SSE的情况下,可以使用数学证明,簇的质心就是该簇内所有数据点的平均值。
问题
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)

K-Means要解决的问题
算法概要
这个算法其实很简单,如下图所示:
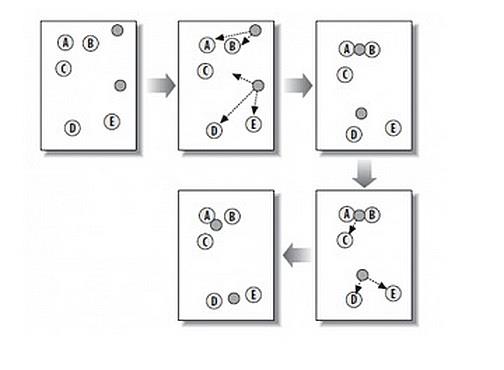
从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
- 随机在图中取K(这里K=2)个种子点。
- 然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
- 接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
- 然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。我重点想说一下“求点群中心的算法”。
求点群中心的算法
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:
1)Minkowski Distance公式——λ可以随意取值,可以是负数,也可以是正数,或是无穷大。

2)Euclidean Distance公式——也就是第一个公式λ=2的情况

3)CityBlock Distance公式——也就是第一个公式λ=1的情况

这三个公式的求中心点有一些不一样的地方,
我们看下图(对于第一个λ在0-1之间)。



(1)Minkowski Distanc (2)Euclidean Distance (3) CityBlock Distance
上面这几个图的大意是他们是怎么个逼近中心的,第一个图以星形的方式,第二个图以同心圆的方式,第三个图以菱形的方式。
实现代码如下:
- # scoding=utf-8
- import pylab as pl
- points = [[int(eachpoint.split("#")[0]), int(eachpoint.split("#")[1])] for eachpoint in open("points","r")]
- # 指定三个初始质心
- currentCenter1 = [20,190]; currentCenter2 = [120,90]; currentCenter3 = [170,140]
- pl.plot([currentCenter1[0]], [currentCenter1[1]],\'ok\')
- pl.plot([currentCenter2[0]], [currentCenter2[1]],\'ok\')
- pl.plot([currentCenter3[0]], [currentCenter3[1]],\'ok\')
- # 记录每次迭代后每个簇的质心的更新轨迹
- center1 = [currentCenter1]; center2 = [currentCenter2]; center3 = [currentCenter3]
- # 三个簇
- group1 = []; group2 = []; group3 = []
- for runtime in range(50):
- group1 = []; group2 = []; group3 = []
- for eachpoint in points:
- # 计算每个点到三个质心的距离
- distance1 = pow(abs(eachpoint[0]-currentCenter1[0]),2) + pow(abs(eachpoint[1]-currentCenter1[1]),2)
- distance2 = pow(abs(eachpoint[0]-currentCenter2[0]),2) + pow(abs(eachpoint[1]-currentCenter2[1]),2)
- distance3 = pow(abs(eachpoint[0]-currentCenter3[0]),2) + pow(abs(eachpoint[1]-currentCenter3[1]),2)
- # 将该点指派到离它最近的质心所在的簇
- mindis = min(distance1,distance2,distance3)
- if(mindis == distance1):
- group1.append(eachpoint)
- elif(mindis == distance2):
- group2.append(eachpoint)
- else:
- group3.append(eachpoint)
- # 指派完所有的点后,更新每个簇的质心
- currentCenter1 = [sum([eachpoint[0] for eachpoint in group1])/len(group1),sum([eachpoint[1] for eachpoint in group1])/len(group1)]
- currentCenter2 = [sum([eachpoint[0] for eachpoint in group2])/len(group2),sum([eachpoint[1] for eachpoint in group2])/len(group2)]
- currentCenter3 = [sum([eachpoint[0] for eachpoint in group3])/len(group3),sum([eachpoint[1] for eachpoint in group3])/len(group3)]
- # 记录该次对质心的更新
- center1.append(currentCenter1)
- center2.append(currentCenter2)
- center3.append(currentCenter3)
- # 打印所有的点,用颜色标识该点所属的簇
- pl.plot([eachpoint[0] for eachpoint in group1], [eachpoint[1] for eachpoint in group1], \'or\')
- pl.plot([eachpoint[0] for eachpoint in group2], [eachpoint[1] for eachpoint in group2], \'oy\')
- pl.plot([eachpoint[0] for eachpoint in group3], [eachpoint[1] for eachpoint in group3], \'og\')
- # 打印每个簇的质心的更新轨迹
- for center in [center1,center2,center3]:
- pl.plot([eachcenter[0] for eachcenter in center], [eachcenter[1] for eachcenter in center],\'k\')
- pl.show()
以上是关于聚类算法:K均值的主要内容,如果未能解决你的问题,请参考以下文章