K均值聚类算法
Posted GUET-13组-2021
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K均值聚类算法相关的知识,希望对你有一定的参考价值。
- K均值聚类的概念
- 1.1 什么是聚类
- 1.2 K-means的原理
- 1.3 K-means的步骤
- 1.4 K-means的数学描述
- K值选择问题
- 2.1 拍脑袋法
- 2.2 肘部法则(Elbow Method)
- 2.3 轮廓系数法
- 2.4 Canopy算法
一.K均值聚类算法的概念
1.1什么是聚类
监督式学习:可以由训练资料中学到或建立一个模式,并依此模式推测新的实例,训练资料是由输入物件和预期输出所输出。
无监督式学习:只有数据没有明确答案,即训练数据没有标签,自动对输入的资料进行分类或分群。
1.2 K-means的原理
K-means算法又名K均值算法,其中的K表示的是聚类为K个簇,means代表取每一个聚类中数据值的均值作为该簇的中心,或称为质心,即用每一个类的质心对该簇进行描述。
在给定K值和K个初始类簇中心点的情况下,把每个点(亦即数据记录)分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕后,根据一个类簇内所有点重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
1.3 K-means步骤
1.假定我们要对N个样本观测做聚类,要求聚为K类,首先选择K个点作为初始中心点。
2.针对数据集中每个样本Xi,分别计算该样本到K个聚类中心的欧式距离,并将其分到距离最小的聚类中心所对应的类中。
3.针对每个类别Cj,重新计算它的聚类中心,n为类别Cj中包含的数据点的个数。
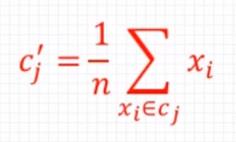
4.然后根据这个中心重复第2,3步,直到收敛(聚类中心不再改变或达到指定的迭代次数),聚类过程结束。
1.4 K-means的数学描述
二.K值选择问题
1.拍脑袋法

2.肘部法则(Elbow Method)
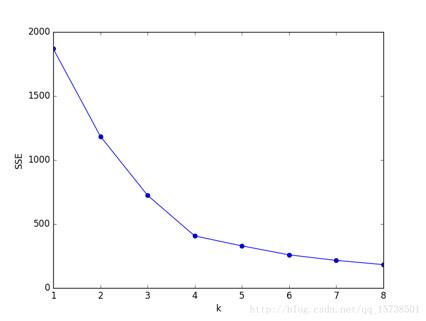
随着聚类数K的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小,并且当K小于真实聚类簇数时,由于K的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当K到达真实聚类数时,再增加K所得到的聚合程度回报会迅速变小,所以SSE的下降和K的关系图是一个手肘的形状,而这个肘部对应的K值就是数据的真实聚类数。
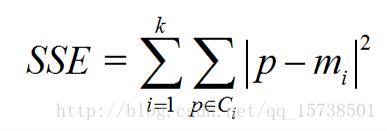
ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
2.轮廓系数法
轮廓系数是一种非常常用的聚类效果评价指标,该指标结合了内聚度和分离度两个因素,用于评估聚类的效果,该值处于-1~+1之间,值越大,表示聚类效果越好,其具体计算过程如下:
假设已经通过聚类算法将待分类的数据进行了聚类,并最终得到了一个簇。对于每个簇中的每个样本点,分别计算其轮廓系数。具体的,需要对每个样本点计算以下两个指标:
a(i):样本点i到与其同一个簇的其他样本点距离的平均值,a(i)越小,说明该样本属于该类的可能性越大。
b(i):样本点i到其他簇Cj中的所有样本的平均距离的平均值bij中的最小值,b(i)=minbi1,bi2,…
则样本的轮廓系数为:
而所有样本点i的轮廓系数的平均值,即为该聚类结果总的轮廓系数S,越接近于1,聚类效果越好。


从上面的公式,不难发现若s(i)<0,说明i与其簇内元素的平均距离大于最近的其他簇,表示聚类效果不好,如果a(i)趋于0,或者b(i)足够大,即a(i)<<b(i),那么s(i)趋近于0,说明聚类效果比较好。
3.Canopy算法

Canopy算法解析


Canopy效果图如下

三.算法的优缺点
优点:原理比较简单,实现也很容易,收敛速度快
聚类效果优
算法的可解释性强
主要调参的参数仅仅是簇族K
缺点:K值的选取不好把握
初始聚类中心的选择较为困难
采用迭代方法,得到的结果不一定是全局最优解
对噪音和异常点比较敏感等
以上是关于K均值聚类算法的主要内容,如果未能解决你的问题,请参考以下文章