python轻量级爬虫的编写
Posted GuityCrown
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python轻量级爬虫的编写相关的知识,希望对你有一定的参考价值。
嗯...今天来分享一下如何使用python编写一个简单的网络爬虫。说到爬虫,这简直就是广大懒惰的程序员和宅男们的福音啊,一次编写,想要啥资源就能爬啥资源,高至各种学习资源,论文资料,低至各种图片小视频(...)等等...嗯...这里讲解了如何搭建一个简单爬虫的框架之后,会基于该框架编写一个栗子,该栗子代码会从python的百科页面开始,爬取各种百科页面信息并记录下来。
注意,这里的标题是《*轻量级爬虫*》,之所以说是轻量级,是因为这里只涉及到静态网页的解析,至于AJAX异步加载,JS脚本什么的并不涉及。
先来代码链接~~~
噢,对了,这个爬虫有两个版本,一个是mysql版,一个是内存板。有啥区别呢,就是前者是使用MySQL数据库存储已经访问过的URL的,后者则使用内存。前者的好处是,多次运行相互独立,不会重复爬取相同的URL,而后者不一样,每一次运行都会从相同的URL出发,重复爬取相同的URL,那是因为前者是持久化存储,而后者不是。一旦后者的程序关掉,所有已经被访问过的URL记录就会清空。但是,前者也有一个缺点,那就是运行速度比较慢...具体怎么样,大家把代码下载下来跑一下就清楚了。下面讲述的是内存存储版的~~~
1. python爬虫框架
在编写代码之前,我们应该先确定一个良好的代码框架,这也是一个优秀的程序员应有的习惯(咳咳...我还不算一个优秀的程序员...以后会是的...)。这里,我将会讲述一个简单爬虫的框架。
一个最基本的爬虫应该由一下4部分组成:URL调度器,网页下载器,网页解析器,爬取信息输出器。以下是它们相互协调工作的流程图。
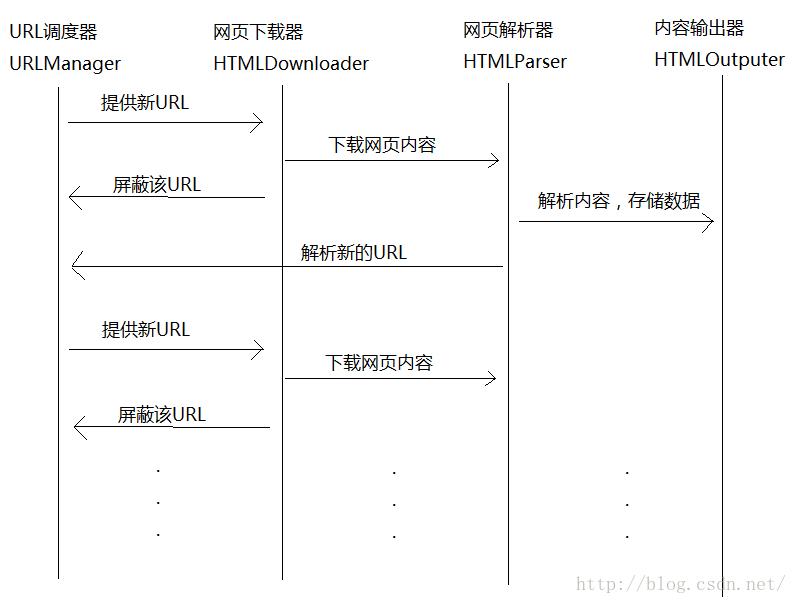
假设这四大功能块都以上图中命名方式命名,那么根据上述流程图,我们可以编写爬虫的主程序如下(为了测试方便,下面代码限制了爬取的URL数量为10个):
# 爬虫主程序
class SpiderMain(object):
def __init__(self):
self.url_manager=UrlManager()
self.downloader=htmlDownloader()
self.parser=HtmlParser()
self.outputer=HtmlOutputer()
def craw(self, url):
num=0
self.url_manager.add_new_url(url)
while self.url_manager.has_new_url() and num < 10:
url = self.url_manager.get_new_url()
print url
# 下载网页内容
content=self.downloader.download(url)
if content is None:
print "Craw failed"
continue
#解析网页数据
data = self.parser.parse(url, content)
if data is None:
print "Craw failed"
continue
new_urls = data[0]
new_data = data[1]
# 收集解析后爬取的数据
self.url_manager.add_new_urls(new_urls)
self.outputer.collect(new_data)
num+=1
self.outputer.output()1) URL调度器
URL调度器负责URL的处理,主要是对将未访问过的URL提供给网页下载器进行访问及下载,将已经访问过的URL屏蔽,防止程序洪福爬取相同的页面,提高效率。它不停地给网页下载器提供新的URL并随之屏蔽掉,如此往复,直到没有新的URL或者达到了爬取数目限制。假设URL调度器是一个类UrlManager,那么我们可以编写如下代码:
# URL调度器
class UrlManager(object):
def __init__(self):
self.new_url=set()
self.old_url=set()
def add_new_url(self,url):
if url not in self.new_url and url not in self.old_url:
self.new_url.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_url)!=0
def get_new_url(self):
url = self.new_url.pop()
self.old_url.add(url)
return url2) 网页下载器
这个很简单,我们使用urllib2提供的接口就可以获取一个指定URL的内容。代码如下:
# 下载网页内容
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
try:
response = urllib2.urlopen(url)
except urllib2.URLError:
return None
except urllib2.HTTPError:
return None
if response.getcode() != 200:
return None
return response.read()3) 网页解析器
我们使用BeautifulSoap解析网页,BeautifulSoup是一个专门用于解析网页并得到DOM树的一个python第三方库,下面简单地说一下如何使用BeautifulSoap解析网页。我们以百度百科为栗。
首先,我们打开http://baike.baidu.com/view/21087.htm这个页面,并右键查看元素。我们先来看看标题的html代码。
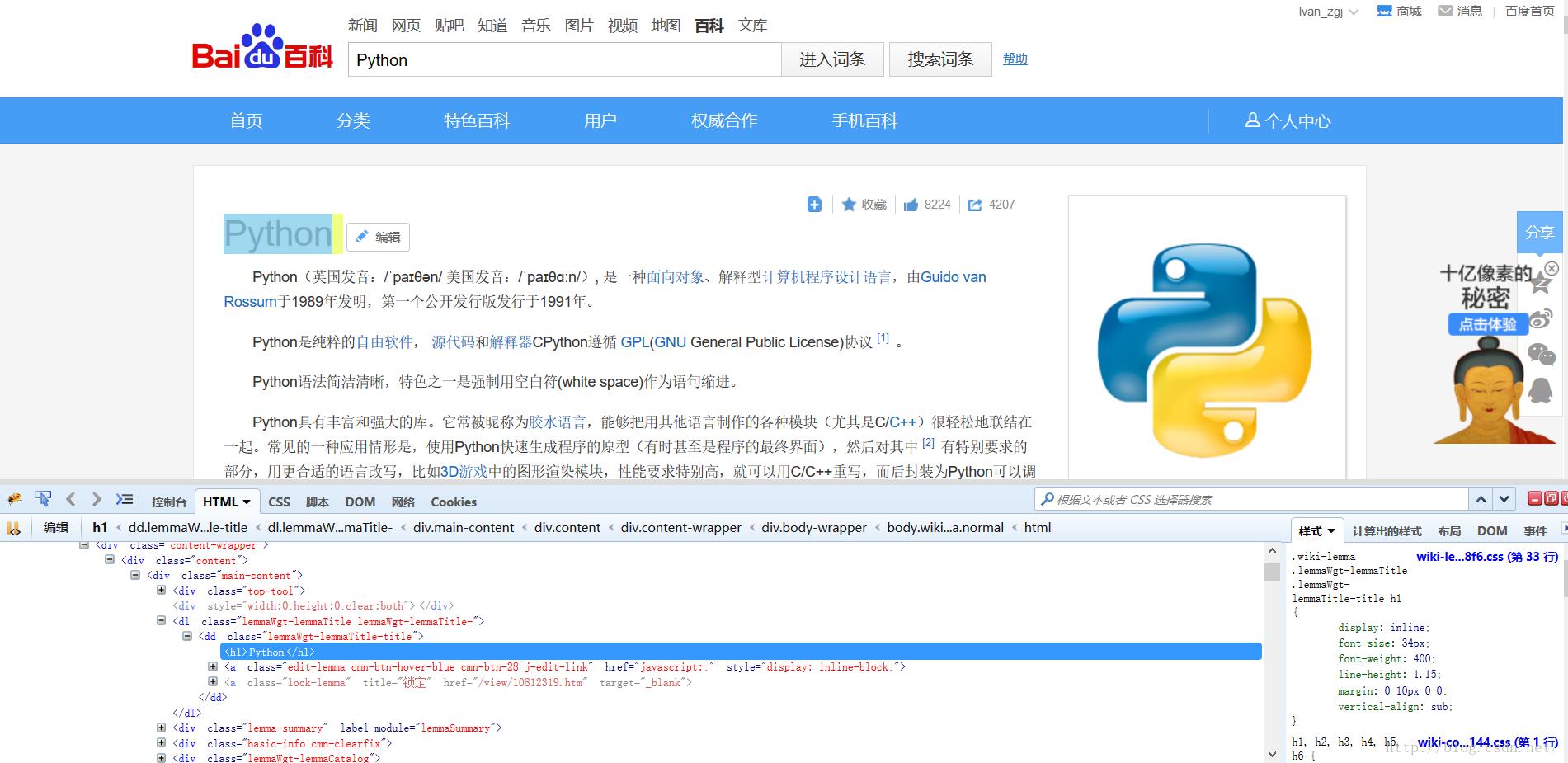
我们可以看到,标题Python的html代码为
...
<dd class="lemmaWgt-lemmaTitle-title">
<h1>Python</h1>
...BeautifulSoap提供了find和find_all方法来寻找一个或多个指定节点。以上面的标题为栗,我们可以编写python代码如下。
soup = BeautifulSoup(content,'html.parser',from_encoding='utf-8')
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title')
if title !=None:
title = title.find('h1')
if title != None:
data['title'] = title.get_text()
else:
data['title'] = ''
在这里,我们的任务是:从一个html页面中获取新的百度百科链接,获取该页面中的标题内容及摘要。下面给出网页解析器的代码:
# 解析网页数据class HtmlParser(object):
def parse(self,url,content):
if url is None or content is None:
return None
soup = BeautifulSoup(content,'html.parser',from_encoding='utf-8')
new_urls=self.__get_new_urls(url,soup)
new_data=self.__get_new_data(url,soup)
return new_urls,new_data
def __get_new_urls(self,url,soup):
new_urls=set()
links = soup.find_all('a',href=re.compile('/view/\\d+.htm'))
for link in links:
new_url=urlparse.urljoin(url,link['href'])
new_urls.add(new_url)
return new_urls
def __get_new_data(self,url,soup):
data={}
data['url']=url
# <dd class="lemmaWgt-lemmaTitle-title"> <h1>Python</h1>
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title')
if title !=None:
title = title.find('h1')
if title != None:
data['title'] = title.get_text()
else:
data['title'] = ''
# <div class="lemma-summary" label-module="lemmaSummary">
summary = soup.find('div', class_='lemma-summary')
if summary != None:
data['summary'] = summary.get_text()
else:
data['summary'] = ''
return data4) 爬取内容的输出器
这个也比较简单,主要是存储爬取到的数据,然后写到一个文件里面。
# 收集爬取到的数据以及将数据输出到文件中
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect(self,data):
self.datas.append(data)
def output(self):
with open('output.html','wb') as f:
f.write('<html>')
f.write('<head><meta charset="UTF-8"></head>')
f.write('<body>')
f.write('<table>')
try:
for data in self.datas:
f.write('<tr>')
f.write('<td>%s</td>' % data['url'].encode('utf-8'))
f.write('<td>%s</td>' % data['title'].encode('utf-8'))
f.write('<td>%s</td>' % data['summary'].encode('utf-8'))
f.write('</tr>')
except Exception as e:
print e
finally:
f.write('</table>')
f.write('</body>')
f.write('</html>')
f.close()2. 爬虫运行效果
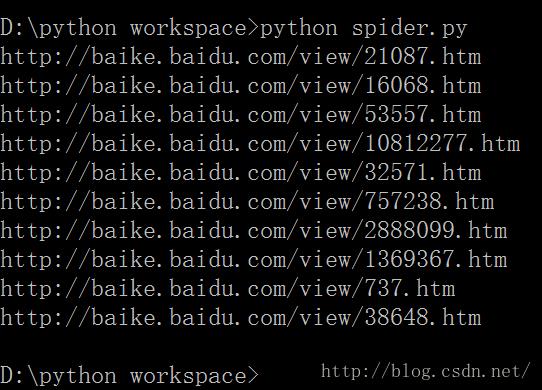
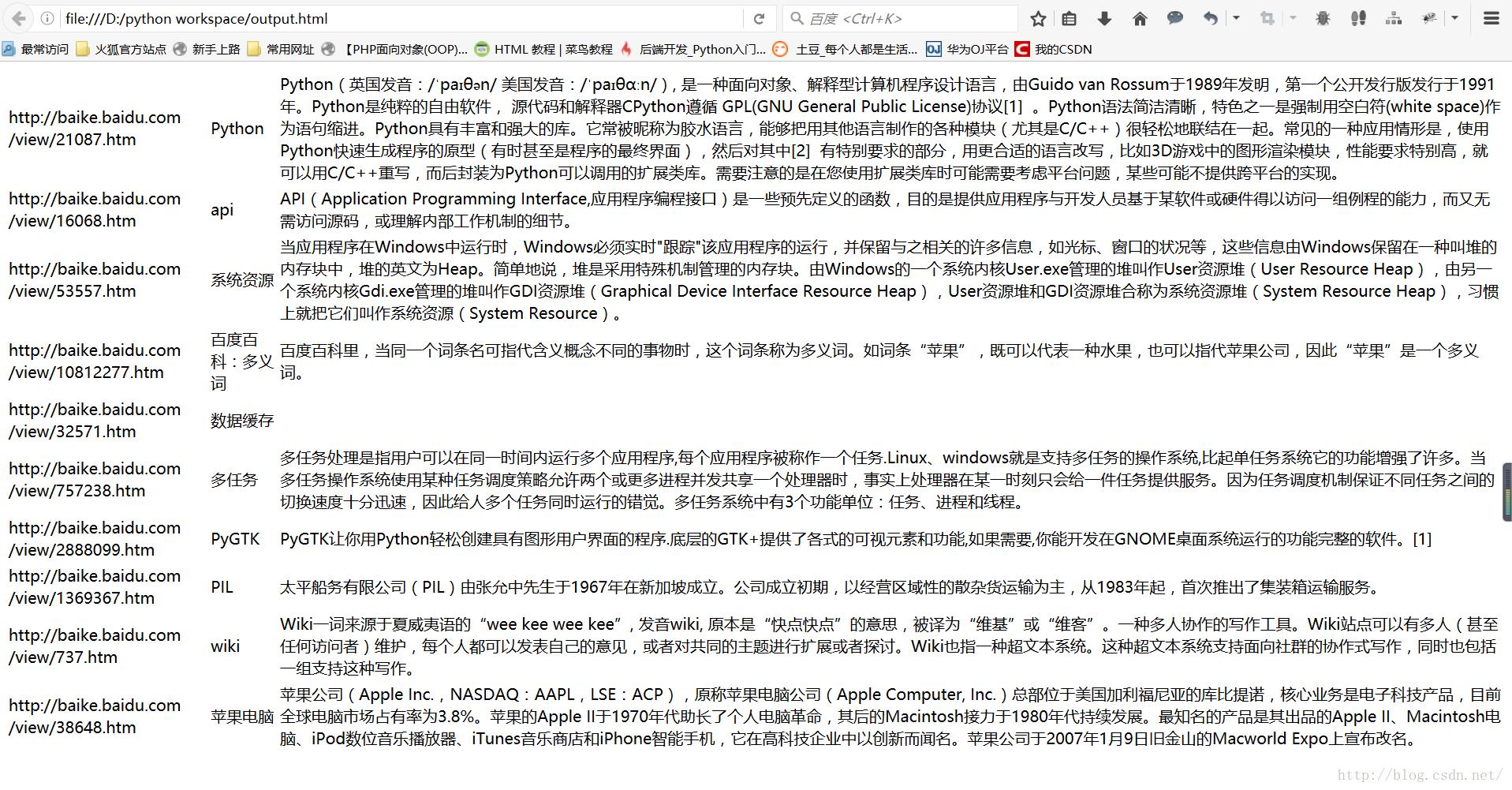
嗯...上述就是一个简单的爬虫的简单解析。谢谢~
以上是关于python轻量级爬虫的编写的主要内容,如果未能解决你的问题,请参考以下文章
Python学习使用Feapder框架,编写爬虫,爬取中国工程院院士信息