Scrapy:Python的爬虫框架
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy:Python的爬虫框架相关的知识,希望对你有一定的参考价值。
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的html数据。虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便。
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
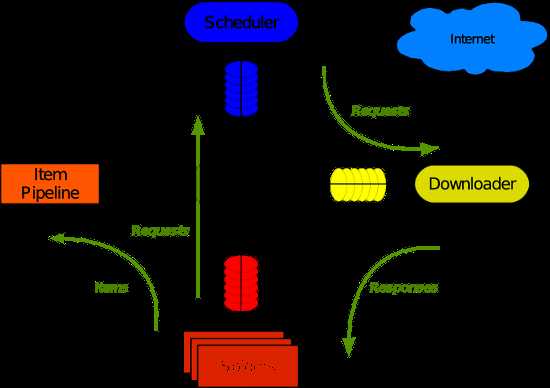
Scrapy主要包括了以下组件:
- 引擎,用来处理整个系统的数据流处理,触发事务。
- 调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
- 项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发。
以上是关于Scrapy:Python的爬虫框架的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫教程-31-创建 Scrapy 爬虫框架项目