Spark中的矩阵乘法分析
Posted 拱头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark中的矩阵乘法分析相关的知识,希望对你有一定的参考价值。
前言:
矩阵乘法在数据挖掘/机器学习中是常用的计算步骤,并且在大数据计算中,shuffle过程是不可避免的,矩阵乘法的不同计算方式shuffle的数据量都不相同。通过对矩阵乘法不同计算方式的深入学习,希望能够对大数据算法实现的shuffle过程优化有所启发。网上有很多分布式矩阵乘法相关的文章和论文,但是鲜有对Spark中分布式矩阵乘法的分析。本文针对Spark中分布式矩阵乘法的实现进行必要的说明讨论。
分布式矩阵乘法原理:
矩阵乘法计算可以分为内积法和外积法。根据实现颗粒度的不同,也可以分为普通矩阵实现和分块矩阵实现。
矩阵乘法计算公式:

公式1为内积法计算公式,即使用A矩阵的行和B矩阵的列进行向量内积计算,每次计算矩阵C中的一个元素。
公式2为外积法计算公式,即使用A矩阵的列和B矩阵的行进行向量外积计算,每次计算一个n×k的矩阵,再将计算出的m个矩阵相加,得到矩阵C。
分布式矩阵乘法内积法实现:
内积要求每次能够计算矩阵C中的一个元素,由于C中每个元素的计算是相互独立的,所以这个计算过程能够并发执行,由于C中有n×k个元素,所以能够支持的最大并发量是n×k。在计算C中每一个元素的时候,都需要用到A中某一行的m个元素和B中某一行的m个元素,这个过程需要从A中shuffle m个元素和B中shuffle m个元素到C的计算节点上,所以使用内积法直接计算矩阵的乘法,最多需要shuffle的元素个数为2×m×n×k个(因为C有n×k个元素),每个计算节点一次最少要计算C中的1个元素,所以每个计算节点内存最少要能够存储2m的数据。但是在大矩阵的运算中,通常并发度不可能开发n×k的程度,所以事实上需要shuffle的数据会远小于2×m×n×k个,因为由于并发量远小于C中的元素个数,所以会在同一个计算节点上计算C的多个元素值,这个时候,这个节点上的数据就能重复使用,不需要为每个元素的计算都shuffle
2m的数据量。这也是使用内积发计算分块矩阵的时候,shuffle量会大大减少的原因。算法shuffle过程如下:
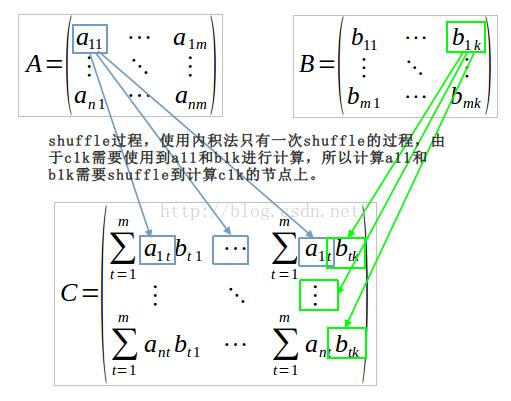
这个算法的缺点显而易见,shuffle的数据过多。在分布式计算系统中,shuffle过程是影响系统性能的重要因素。但是这种算法在A或B其中一个矩阵是小矩阵的时候是有明显的优势的。例如:如果B是小矩阵,矩阵B可以broadcast到分布式矩阵A的每一个节点上,这么在计算C矩阵的时候,A不需要再进行shuffle操作,能够充分的利用数据本地性进行计算。
分布式矩阵乘法外积法实现:
向量外积计算公式如下:
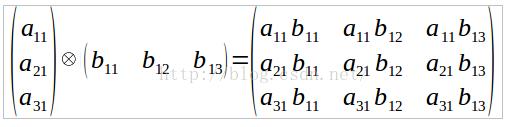
结合外积的计算公式,从上面公式2可以看出,矩阵乘法的外积公式是先计算m个n×k的矩阵,再将m个矩阵相加得到矩阵C。在这个过程中m个矩阵的计算过程是相互独立的。所以能够支持的最大并发量是m。在计算m个矩阵的任意一个的时候,都需要用到A中某一列的n个元素和B中某一行的k个元素,所以在计算m个矩阵的时候,最多需要移动m×(n+k)个元素。在计算完m个矩阵之后,需要将m个矩阵加和。矩阵加法是对应位置元素相加,所以在最后计算C中每一个元素的时候,需要将m个矩阵对应位置的数据shuffle到某一个计算节点进行加和,所以在加和过程中,需要shuffle的最大数据量是m×n×k(因为m个矩阵,每个矩阵有n×k个元素)。每个计算节点最少要计算m个矩阵中的1个,所以计算节点最少需要能够存储n+k个元素的内存,由于每个节点输出元素量为n×k,这个数据量在大规模矩阵中是相当大的,单个计算节点内存很难存储下来,所以每个节点计算的输出结果通常是达到一定量后存储到磁盘上,但是如果是在大规模稀疏矩阵中,m个矩阵中每个矩阵中有值的个数通常都会远小于n×k个,所以第二次shuffle的数据量通常远小于n×k。算法shuffle过程如下:
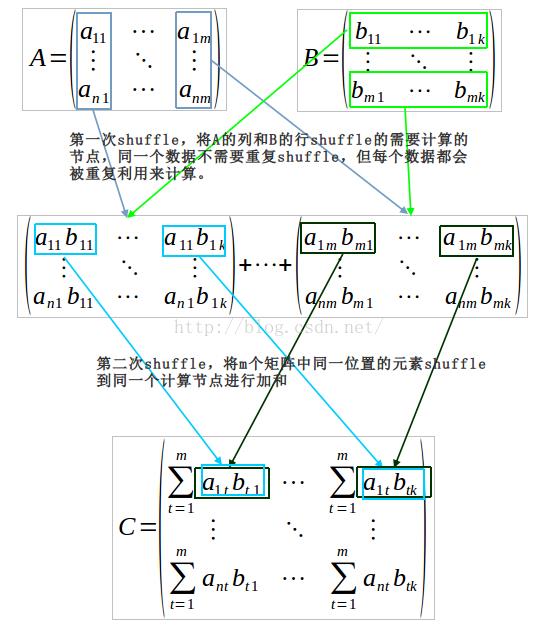
这个算法的缺点就是,在分布式大矩阵中,如果不是稀疏矩阵,计算出来的中间矩阵会非常大,要在单个计算节点完全使用内存计算中间矩阵基本不可能,需要使用磁盘辅助存储中间矩阵的计算结果。算法的优势在于计算稀疏矩阵和虽然AB都是大规模矩阵,但是计算结果是个小矩阵的时候,这两种情况每个中间矩阵都能够完全存储在内存中,就会比较快。
分块矩阵的分布式乘法实现:
分块矩阵乘法的过程和不分块的计算过程差不多,也可以使用内积法和外积法实现。使用分块矩阵实现分布式矩阵乘法的好处主要有两个,一个是减少shuffle过程的数据量,另一个是分块矩阵在每个小块在本地计算的时候能够调用现有矩阵计算包,成熟的矩阵计算包通常来说计算效率都比自己实现的好,例如矩阵计算的常用包BLAS包。
分块矩阵的基本计算公式如下(来自维基百科:
https://zh.wikipedia.org/wiki/%E5%88%86%E5%A1%8A%E7%9F%A9%E9%99%A3):

以上公式的计算复杂度为O(n^3),除了以上公式之外1969年Strassen利用分治算法将分块矩阵乘法的计算复杂度降低到O(n^log7),计算公式如下所示(来自维基百科:
https://zh.wikipedia.org/wiki/%E6%96%BD%E7%89%B9%E6%8B%89%E6%A3%AE%E6%BC%94%E7%AE%97%E6%B3%95):

java中的Jampack包和JAMA都是使用Strassen算法实现矩阵乘法,这些软件包都没有实现并行计算,但是在分布式计算中可以将每个小块分布到本地计算,再调用对应的单机包。
分块矩阵理论上,一个矩阵中的行列数是可以不一样的,但是为了实现方便,分布式分块矩阵乘法中的实现通常一个矩阵中每个块的行列数都是一样的。
在Spark中,Spark自带的org.apache.spark.mllib.linalg.distributed.BlockMatrix实现了分布式矩阵乘法,BlockMatrix是使用内积法实现的分布式分块矩阵的乘法。除此之外,第三方包实现有,南京大学PASA实验室在Spark上改进的分布式矩阵乘法(网址:
http://pasa-bigdata.nju.edu.cn/project/Marlin.html),PASA的包也是使用内积发实现的分布式分块矩阵乘法。分块矩阵的内积法和外积法算法数据shuffle的示意图和上面提到的非分块矩阵的示意图一样,只是每个元素都改成一个小矩阵,这里只分析shuffle的数据量。假设分块矩阵A和B还是原来的矩阵,只是分块成行数r,列数j的小矩阵。则内积法shuffle的数据量为2×m/c×n/r×k/r×(r×c)=2×m×n×k/r,外积法shuffle数据量为m/c×(n/r+k/r+n/r×k/r)×(r×c)
= m×(n+k/r+n×k/r)。可见分块矩阵乘法的算法shuffle数据量比不分块的少。
Spark中的分块矩阵乘法不使用外积法实现,主要考虑到外积法内存占用量大。
Spark自带BlockMatrix乘法源码分析:
必要的注释已经在源码中给出
def multiply(other: BlockMatrix): BlockMatrix = {
.......
if (colsPerBlock == other.rowsPerBlock) {
//GridPartitioner一共分为numRowBlocks*other.numColBlocks个partition
val resultPartitioner = GridPartitioner(numRowBlocks, other.numColBlocks,
math.max(blocks.partitions.length, other.blocks.partitions.length))
// 这里是计算每个leftDestinations和rightDestinations的类型都是Map[(Int,Int),Set[Int]],也就是先计算左右矩阵的
// 每一块会shuffle到哪个partition
val (leftDestinations, rightDestinations) = simulateMultiply(other, resultPartitioner)
// Each block of A must be multiplied with the corresponding blocks in the columns of B.
val flatA = blocks.flatMap { case ((blockRowIndex, blockColIndex), block) =>
val destinations = leftDestinations.getOrElse((blockRowIndex, blockColIndex), Set.empty)
destinations.map(j => (j, (blockRowIndex, blockColIndex, block)))
}
// Each block of B must be multiplied with the corresponding blocks in each row of A.
val flatB = other.blocks.flatMap { case ((blockRowIndex, blockColIndex), block) =>
val destinations = rightDestinations.getOrElse((blockRowIndex, blockColIndex), Set.empty)
destinations.map(j => (j, (blockRowIndex, blockColIndex, block)))
}
// GridPartitioner一共有numRowBlocks*other.numColBlocks 个分区,所以在cogroup的时候,在计算A*B=C的时候,C矩阵所用到的所有A和B中的
//分块都会在一个partition中,在reduceByKey的时候就可以进行combineByKey进行优化,事实上在reduceByKey的过程中,只有相加的过程,
// 没有shuffle的过程。
val newBlocks = flatA.cogroup(flatB, resultPartitioner).flatMap { case (pId, (a, b)) =>
a.flatMap { case (leftRowIndex, leftColIndex, leftBlock) =>
b.filter(_._1 == leftColIndex).map { case (rightRowIndex, rightColIndex, rightBlock) =>
//在进行矩阵乘法实现的时候,本地矩阵计算使用com.github.fommil.netlib包提供的矩阵算法,矩阵加法调用的是scalanlp包提供的矩阵加法
val C = rightBlock match {
case dense: DenseMatrix => leftBlock.multiply(dense)
case sparse: SparseMatrix => leftBlock.multiply(sparse.toDense)
case _ =>
throw new SparkException(s"Unrecognized matrix type ${rightBlock.getClass}.")
}
((leftRowIndex, rightColIndex), C.toBreeze)
}
}
}.reduceByKey(resultPartitioner, (a, b) => a + b).mapValues(Matrices.fromBreeze)
// TODO: Try to use aggregateByKey instead of reduceByKey to get rid of intermediate matrices
new BlockMatrix(newBlocks, rowsPerBlock, other.colsPerBlock, numRows(), other.numCols())
} else {
.......
}
}
.......
if (colsPerBlock == other.rowsPerBlock) {
//GridPartitioner一共分为numRowBlocks*other.numColBlocks个partition
val resultPartitioner = GridPartitioner(numRowBlocks, other.numColBlocks,
math.max(blocks.partitions.length, other.blocks.partitions.length))
// 这里是计算每个leftDestinations和rightDestinations的类型都是Map[(Int,Int),Set[Int]],也就是先计算左右矩阵的
// 每一块会shuffle到哪个partition
val (leftDestinations, rightDestinations) = simulateMultiply(other, resultPartitioner)
// Each block of A must be multiplied with the corresponding blocks in the columns of B.
val flatA = blocks.flatMap { case ((blockRowIndex, blockColIndex), block) =>
val destinations = leftDestinations.getOrElse((blockRowIndex, blockColIndex), Set.empty)
destinations.map(j => (j, (blockRowIndex, blockColIndex, block)))
}
// Each block of B must be multiplied with the corresponding blocks in each row of A.
val flatB = other.blocks.flatMap { case ((blockRowIndex, blockColIndex), block) =>
val destinations = rightDestinations.getOrElse((blockRowIndex, blockColIndex), Set.empty)
destinations.map(j => (j, (blockRowIndex, blockColIndex, block)))
}
// GridPartitioner一共有numRowBlocks*other.numColBlocks 个分区,所以在cogroup的时候,在计算A*B=C的时候,C矩阵所用到的所有A和B中的
//分块都会在一个partition中,在reduceByKey的时候就可以进行combineByKey进行优化,事实上在reduceByKey的过程中,只有相加的过程,
// 没有shuffle的过程。
val newBlocks = flatA.cogroup(flatB, resultPartitioner).flatMap { case (pId, (a, b)) =>
a.flatMap { case (leftRowIndex, leftColIndex, leftBlock) =>
b.filter(_._1 == leftColIndex).map { case (rightRowIndex, rightColIndex, rightBlock) =>
//在进行矩阵乘法实现的时候,本地矩阵计算使用com.github.fommil.netlib包提供的矩阵算法,矩阵加法调用的是scalanlp包提供的矩阵加法
val C = rightBlock match {
case dense: DenseMatrix => leftBlock.multiply(dense)
case sparse: SparseMatrix => leftBlock.multiply(sparse.toDense)
case _ =>
throw new SparkException(s"Unrecognized matrix type ${rightBlock.getClass}.")
}
((leftRowIndex, rightColIndex), C.toBreeze)
}
}
}.reduceByKey(resultPartitioner, (a, b) => a + b).mapValues(Matrices.fromBreeze)
// TODO: Try to use aggregateByKey instead of reduceByKey to get rid of intermediate matrices
new BlockMatrix(newBlocks, rowsPerBlock, other.colsPerBlock, numRows(), other.numCols())
} else {
.......
}
}
以上代码有一个simulateMultiply方法比较重要,源码注释如下:
private[distributed]
def simulateMultiply(
other: BlockMatrix,
partitioner: GridPartitioner): (BlockDestinations, BlockDestinations) = {
val leftMatrix = blockInfo.keys.collect() // blockInfo should already be cached
val rightMatrix = other.blocks.keys.collect()
//以下这段代码这样理解,假设A*B=C,因为A11在计算C11到C1n的时候会用到,所以A11在计算C11到C1n的机器都会存放一份。
val leftDestinations = leftMatrix.map { case (rowIndex, colIndex) =>
//左矩阵中列号会和右矩阵行号相同的块相乘,得到所有右矩阵中行索引和左矩阵中列索引相同的矩阵的位置。
// 由于有这个判断,右矩阵中没有值的快左矩阵就不会重复复制了,避免了零值计算。
val rightCounterparts = rightMatrix.filter(_._1 == colIndex)
// 因为矩阵乘完之后还有相加的操作(reduceByKey),相加的操作如果在同一部机器上可以用combineBy进行优化,
// 这里直接得到每一个分块在进行完乘法之后会在哪些partition中用到。
val partitions = rightCounterparts.map(b => partitioner.getPartition((rowIndex, b._2)))
((rowIndex, colIndex), partitions.toSet)
}.toMap
val rightDestinations = rightMatrix.map { case (rowIndex, colIndex) =>
val leftCounterparts = leftMatrix.filter(_._2 == rowIndex)
val partitions = leftCounterparts.map(b => partitioner.getPartition((b._1, colIndex)))
((rowIndex, colIndex), partitions.toSet)
}.toMap
(leftDestinations, rightDestinations)
}
other: BlockMatrix,
partitioner: GridPartitioner): (BlockDestinations, BlockDestinations) = {
val leftMatrix = blockInfo.keys.collect() // blockInfo should already be cached
val rightMatrix = other.blocks.keys.collect()
//以下这段代码这样理解,假设A*B=C,因为A11在计算C11到C1n的时候会用到,所以A11在计算C11到C1n的机器都会存放一份。
val leftDestinations = leftMatrix.map { case (rowIndex, colIndex) =>
//左矩阵中列号会和右矩阵行号相同的块相乘,得到所有右矩阵中行索引和左矩阵中列索引相同的矩阵的位置。
// 由于有这个判断,右矩阵中没有值的快左矩阵就不会重复复制了,避免了零值计算。
val rightCounterparts = rightMatrix.filter(_._1 == colIndex)
// 因为矩阵乘完之后还有相加的操作(reduceByKey),相加的操作如果在同一部机器上可以用combineBy进行优化,
// 这里直接得到每一个分块在进行完乘法之后会在哪些partition中用到。
val partitions = rightCounterparts.map(b => partitioner.getPartition((rowIndex, b._2)))
((rowIndex, colIndex), partitions.toSet)
}.toMap
val rightDestinations = rightMatrix.map { case (rowIndex, colIndex) =>
val leftCounterparts = leftMatrix.filter(_._2 == rowIndex)
val partitions = leftCounterparts.map(b => partitioner.getPartition((b._1, colIndex)))
((rowIndex, colIndex), partitions.toSet)
}.toMap
(leftDestinations, rightDestinations)
}
从代码中可以知道,Spark中自带的分块矩阵乘法要求每个Executor的内存最少能够存下左矩阵一行中所有非零块和右矩阵一列中的所有非零块。在计算的过程中只需要一次shuffle。
PASA基于Spark实现的BlockMatrix乘法:
源码注释如下:
def multiply(other: BlockMatrix): BlockMatrix = {
.......
if (numBlksByCol() == other.numBlksByRow()) {
//num of rows to be split of this matrix
val mSplitNum = numBlksByRow()
//num of columns to be split of this matrix, meanwhile num of rows of that matrix
val kSplitNum = numBlksByCol()
//num of columns to be split of that matrix
val nSplitNum = other.numBlksByCol()
val partitioner = new MatrixMultPartitioner(mSplitNum, kSplitNum, nSplitNum)
val thisEmitBlocks = blocks.flatMap({ case(blkId, blk) =>
//左矩阵的每一块要与右矩阵对应行的每一块矩阵相乘,右矩阵每一行有nSplitNum个块,所以每个块复制nSplitNum份。
//这里没有考虑右矩阵某些块是零值,所以在join进行本地矩阵乘法的时候会有不必要零值计算
Iterator.tabulate[(BlockID, SubMatrix)](nSplitNum)(i => {
val seq = blkId.row * nSplitNum * kSplitNum + i * kSplitNum + blkId.column
(BlockID(blkId.row, i, seq), blk)})
}).partitionBy(partitioner)
val otherEmitBlocks = other.blocks.flatMap({ case(blkId, blk) =>
Iterator.tabulate[(BlockID, SubMatrix)](mSplitNum)(i => {
val seq = i * nSplitNum * kSplitNum + blkId.column * kSplitNum + blkId.row
(BlockID(i, blkId.column, seq), blk)
})
}).partitionBy(partitioner)
if (kSplitNum != 1) {
//以下代码join用到的Partitioner是MatrixMultPartitioner,reduceByKey用到的Partitioner是HashPartitioner,
// 两次shuffle用到不同的Partitioner不同,所以不可避免的需要两次shuffle。
val result = thisEmitBlocks.join(otherEmitBlocks).mapPartitions(iter =>
iter.map { case (blkId, (block1, block2)) =>
(BlockID(blkId.row, blkId.column), block1.multiply(block2))
}
).reduceByKey((a, b) => a.add(b))
new BlockMatrix(result, numRows(), other.numCols(), mSplitNum, nSplitNum)
} else {
val result = thisEmitBlocks.join(otherEmitBlocks).mapPartitions(iter =>
iter.map { case (blkId, (block1, block2)) =>
(BlockID(blkId.row, blkId.column), block1.multiply(block2))
}
)
new BlockMatrix(result, numRows(), other.numCols(), mSplitNum, nSplitNum)
}
}
......
}
.......
if (numBlksByCol() == other.numBlksByRow()) {
//num of rows to be split of this matrix
val mSplitNum = numBlksByRow()
//num of columns to be split of this matrix, meanwhile num of rows of that matrix
val kSplitNum = numBlksByCol()
//num of columns to be split of that matrix
val nSplitNum = other.numBlksByCol()
val partitioner = new MatrixMultPartitioner(mSplitNum, kSplitNum, nSplitNum)
val thisEmitBlocks = blocks.flatMap({ case(blkId, blk) =>
//左矩阵的每一块要与右矩阵对应行的每一块矩阵相乘,右矩阵每一行有nSplitNum个块,所以每个块复制nSplitNum份。
//这里没有考虑右矩阵某些块是零值,所以在join进行本地矩阵乘法的时候会有不必要零值计算
Iterator.tabulate[(BlockID, SubMatrix)](nSplitNum)(i => {
val seq = blkId.row * nSplitNum * kSplitNum + i * kSplitNum + blkId.column
(BlockID(blkId.row, i, seq), blk)})
}).partitionBy(partitioner)
val otherEmitBlocks = other.blocks.flatMap({ case(blkId, blk) =>
Iterator.tabulate[(BlockID, SubMatrix)](mSplitNum)(i => {
val seq = i * nSplitNum * kSplitNum + blkId.column * kSplitNum + blkId.row
(BlockID(i, blkId.column, seq), blk)
})
}).partitionBy(partitioner)
if (kSplitNum != 1) {
//以下代码join用到的Partitioner是MatrixMultPartitioner,reduceByKey用到的Partitioner是HashPartitioner,
// 两次shuffle用到不同的Partitioner不同,所以不可避免的需要两次shuffle。
val result = thisEmitBlocks.join(otherEmitBlocks).mapPartitions(iter =>
iter.map { case (blkId, (block1, block2)) =>
(BlockID(blkId.row, blkId.column), block1.multiply(block2))
}
).reduceByKey((a, b) => a.add(b))
new BlockMatrix(result, numRows(), other.numCols(), mSplitNum, nSplitNum)
} else {
val result = thisEmitBlocks.join(otherEmitBlocks).mapPartitions(iter =>
iter.map { case (blkId, (block1, block2)) =>
(BlockID(blkId.row, blkId.column), block1.multiply(block2))
}
)
new BlockMatrix(result, numRows(), other.numCols(), mSplitNum, nSplitNum)
}
}
......
}
总结:
通过源码分析,可以知道Spark自带的BlockMatrix乘法算法比PASA实现的BlockMatrix乘法算法更高效,能够避免不必要的零值计算,也能够减少一次shuffle。在实践中,使用Spark自带的BlockMatrix算法要注意内存的使用,分块的时候,块的大小是多少除了注意内存之外,还要注意令子块中的数据能够尽量的紧凑,减少零值计算。
以上是关于Spark中的矩阵乘法分析的主要内容,如果未能解决你的问题,请参考以下文章