基于nightmare的美团美食商家爬虫实践
Posted leestar54
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于nightmare的美团美食商家爬虫实践相关的知识,希望对你有一定的参考价值。
前言
上学的时候自己写过一些爬虫代码,比较简陋,基于HttpRequest请求获取地址返回的信息,再根据正则表达式抓取想要的内容。那时候爬的网站大多都是静态的,直接获取直接爬即可,而且也没有什么限制。但是现在网站的安全越来越完善,各种机器识别,打码,爬虫也要越来越只能才行了。
前段时间有需求要简单爬取美团商家的数据,做了一些分析,实践,在这里总结分享。
美团商家页分析
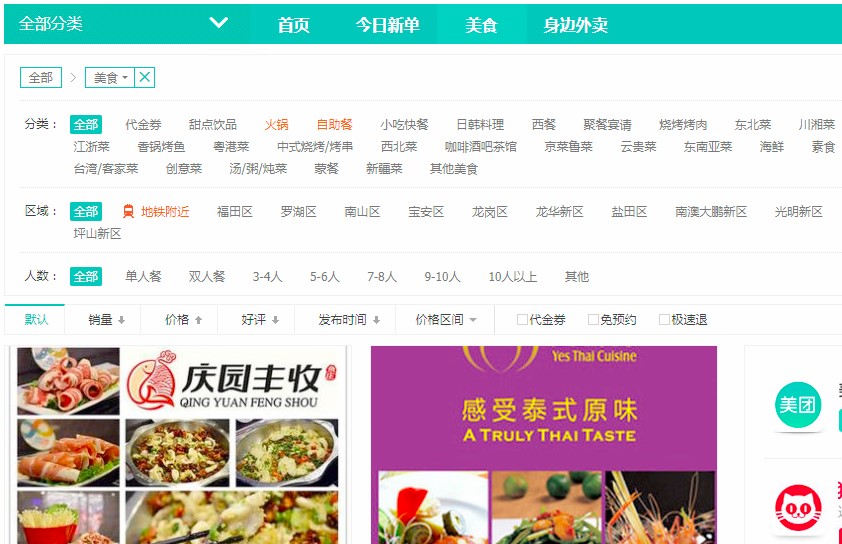
1、城市大全可以很容易的在这个页面爬出来 http://www.meituan.com/index/changecity/initiative
2、每个城市一个地址,例如深圳:http://sz.meituan.com/category/meishi
3、可以按照分类、区域、人数来分类
4、商家列表是动态JS加载的,并且会有很多页数
5、根据商家列表再进入商家详情获取数据
这样爬取流程即为
1、进去城市美食页
2、抓取分类,循环选择分类
3、抓取区域,循环选择区域
4、抓取人数,循环选择人数
5、判断是否有下一页按钮,循环进入下一页
6、进入详情页抓取,提交之后continue
需要爬取的数据有(这里没有按人数爬)
CREATE TABLE `test_mt` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`city` varchar(10) NOT NULL DEFAULT \'\' COMMENT \'城市\',
`cate` varchar(15) NOT NULL DEFAULT \'\' COMMENT \'分类\',
`area` varchar(15) NOT NULL DEFAULT \'\' COMMENT \'区域\',
`poi` varchar(15) NOT NULL DEFAULT \'\' COMMENT \'商圈\',
`name` varchar(30) NOT NULL DEFAULT \'\' COMMENT \'店名\',
`addr` varchar(50) NOT NULL DEFAULT \'\' COMMENT \'地址\',
`tel` varchar(30) NOT NULL DEFAULT \'\' COMMENT \'联系方式\',
`rj` int(11) NOT NULL DEFAULT \'0\' COMMENT \'人均\',
`rate` float(2,1) NOT NULL DEFAULT \'0.0\' COMMENT \'评价\',
`rate_count` int(11) NOT NULL DEFAULT \'0\' COMMENT \'评价数\',
`recom_food` varchar(512) NOT NULL DEFAULT \'\' COMMENT \'特色菜\',
`desc` varchar(512) NOT NULL DEFAULT \'\' COMMENT \'门店介绍\',
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
爬虫工具选取
为了快速实现功能,直接找现有的开源工具,说到爬虫,python首屈一指,所以先以此尝试
pysipder
https://github.com/binux/pyspider
最开始尝试了pysipder,主要是因为国人写的,先支持国产,准确的说pyspider已经是一个非常强大的爬虫框架了,具体内容官网查看,经过试用之后,感觉有一些杀鸡用牛刀的感觉,再来pyspider默认只支持抓取静态页,对于js加载的美团列表,难度就大了很多,中间尝试考虑通过获取cookie,模拟接口操作,但是协议解析起麻烦又耗时,坑肯定又多,就放弃了。
pyspider的js加载是通过配合phantomjs实现的,但是据说有内存泄露的问题,要不定期的重启phantomjs,试用之后发现并不很顺手(也许是python不熟),特别是模拟点击操作很麻烦导致回调地狱的出现,所以考虑再多试用几款工具选型。
scrapy
https://scrapy.org/
20K的star代表了它的强大,试用过程中发现和pysipder大同小异,遇到的问题也大同小异,也跳过了。
nightmare
https://github.com/segmentio/nightmare
之前用的时候git上star貌似还不多,目前已经13K了,准确的说nightmare一款基于electron(曾经使用PhantomJS,后面改用Electron)的高度封装web自动化测试工具,当然也可以用来做一些简易的爬虫,api及其简单,缺点就是模拟真人操作,这样的爬虫效率非常低,但是对于高安全性的网站来说,这样的操作也最为安全,防止被封。
经过试用之后,最后决定采用nightmare进行爬虫。
同步任务
需要注意的是evaluate函数返回的是promise,即为异步回调函数,可以配合co库,进行yield操作,即可用同步模式进行异步操作。
var Nightmare = require(\'nightmare\'),
nightmare = Nightmare(),
co = require(\'co\');
var run = function*(){
var results = [];
for(var i=0; i<5; i++){
var result = yield nightmare.goto(\'http://example.org\').evaluate(function(){ return 123;});
results.push(result);
}
return results;
}
co(run).then(function(results){
console.dir(results);
console.log(\'done\');
});js动态加载
nightmare是模拟操作,相当于开了个浏览器,所以这都不是什么问题,但需要注意的是,列表如果数量太多,其实是分页加载的,第一次只加载十个,下滑再加载10个,加载完整页之后,还有下一页按钮,至于当前页的分页,需要滑动到低,才会加载完,所以还需要模拟滑动操作scrollTo,滑动过程中动态加载数据,有时候会有不成功的情况(可能是由于官方限制?),所以偶尔会漏过一些商家。
中断继续
为了避免异常导致从头开始爬,可以每次在catch的时候保存当前的状态值,下次启动读取,然后接着爬即可。
//记录执行步骤,中断后下次继续
//分类
let stepLog = {
cate_index: 0,
//区域
location_index: 8,
//商圈
area_index: 0,
}
function writeLog (log) {
fs.writeFileSync(\'./steplog.log\', JSON.stringify(log));
}
function readLog () {
let json = fs.readFileSync(\'./steplog.log\');
return JSON.parse(json);
}爬坑总结
1、爬虫检测限制非常严格,搞不好就403,隔天才恢复,间隔时间很重要,示例代码的参数已经比较稳定。
2、数据基本上都是动态加载,加载接口又要cookie,又要post首次加载的各种参数,这也是为什么难爬,之前考虑过用PhantomJS,但是API过于复杂,无界面,不方便调试,nightmare基于electron这方面简直是神器,模拟人操作,又防封,又便捷。
3、nightmare不会记录cookie,所以如果有时候爬久了,关闭再开会403,但是浏览器正常,是cookie导致的,可以访问一些美团其他页面,先加载cookie再跳转到需要爬的页面即可。
4、由于默认情况不会记录cookie,所以需要的话可以再结束的时候getcookie序列化成json保存成文件,下次开启的时候再进行初始化。
5、中断继续,也可以把各种状态参数序列化成json保存,下次启动初始化,即可从中断的地方继续开始。
6、可以不需要正则,直接用dom选择器进行html元素查询。
7、效率确实不高,但也没啥好办法,爬一个城市大概花4-5天。
示例代码
注意post提交服务器地址改为自己的接口,如果需要保存本地,需自行处理。
代码保存直接运行即可 node **.js。
PS:中间变量命名有些随意,请见谅。
var Nightmare = require(\'nightmare\');
var fs = require(\'fs\');
//nightmare = Nightmare({ show: true }),
var co = require(\'co\');
var http = require(\'http\');
var city = \'南昌\';
var run = function* () {
let nightmare = Nightmare({ show: true, waitTimeout: 60000 });
//记录执行步骤,中断后下次继续
//分类
let stepLog = {
cate_index: 0,
//区域
location_index: 8,
//商圈
area_index: 0,
}
if (fs.existsSync(\'./steplog.log\')) {
stepLog = readLog();
}
//writeLog(stepLog);
//获取地区美食分类,先进主页是为了获取cookie防止被封
let result1 = yield nightmare.goto(\'http://nc.meituan.com/\').wait(5000)
.goto(\'http://nc.meituan.com/category/meishi\')
.wait(\'div.filter-label-list.filter-section.category-filter-wrapper.first-filter ul.inline-block-list\')
.evaluate(function () {
let arr_a = document.querySelectorAll(\'div.filter-label-list.filter-section.category-filter-wrapper.first-filter ul.inline-block-list li a\');
let str = \'\';
//过滤全部,代金券
for (var index = 2; index < arr_a.length; index++) {
var element = arr_a[index];
str += element.href + \',\';
}
return str;
})
let arr_a1 = result1.split(\',\');
console.log(arr_a1);
var temp_index1 = stepLog.cate_index;
for (var index1 = temp_index1; index1 < arr_a1.length; index1++) {
stepLog.cate_index = index1;
//获取美食分类之后,获取地区
var element1 = arr_a1[index1];
if (element1 != \'\') {
try {
let result2 = yield nightmare
.wait(10000)
.goto(element1)
.wait(\'ul.inline-block-list.J-filter-list.filter-list--fold\')
.evaluate(function () {
let arr_a = document.querySelectorAll(\'ul.inline-block-list.J-filter-list.filter-list--fold li a\');
let str = \'\';
//过滤全部,地铁2
for (var index = 2; index < arr_a.length; index++) {
var element = arr_a[index];
str += element.href + \',\';
}
return str
});
let arr_a2 = result2.split(\',\');
console.log(arr_a2);
var temp_index2 = stepLog.location_index;
for (var index2 = temp_index2; index2 < arr_a2.length; index2++) {
stepLog.location_index = index2;
//获取地区之后,获取商圈
var element2 = arr_a2[index2];
if (element2 != \'\') {
try {
let result3 = yield nightmare
.wait(10000)
.goto(element2)
.wait(\'ul.inline-block-list.J-area-block\')
.evaluate(function () {
let arr_a = document.querySelectorAll(\'ul.inline-block-list.J-area-block li a\');
let str = \'\';
//商圈下标,过滤全部
for (var index = 1; index < arr_a.length; index++) {
var element = arr_a[index];
str += element.href + \',\';
}
return str
});
arr_a3 = result3.split(\',\');
console.log(arr_a3);
var temp_index3 = stepLog.area_index;
for (var index3 = temp_index3; index3 < arr_a3.length; index3++) {
stepLog.area_index = index3;
//获取商圈店铺信息
var element3 = arr_a3[index3];
if (element3 != \'\') {
let nextPage = \'undefined\';
do {
let url = \'\';
if (nextPage == \'undefined\')
url = element3;
else
url = nextPage;
try {
let result4 = yield nightmare
.wait(10000)
.goto(url)
.wait(\'#content\').wait(2000)
.scrollTo(716, 0).wait(5000).scrollTo(716 * 2, 0).wait(5000).scrollTo(716 * 3, 0).wait(5000).scrollTo(716 * 4, 0).wait(5000).scrollTo(716 * 5, 0).wait(5000).scrollTo(716 * 6, 0).wait(5000).scrollTo(716 * 7, 0).wait(5000).scrollTo(716 * 8, 0).wait(5000).scrollTo(716 * 9, 0).wait(5000).scrollTo(716 * 10, 0).wait(5000).scrollTo(716 * 11, 0).wait(5000).scrollTo(716 * 12, 0).wait(5000).scrollTo(716 * 13, 0).wait(5000).scrollTo(716 * 14, 0).wait(5000).scrollTo(716 * 15, 0).wait(5000).scrollTo(716 * 16, 0).wait(5000).scrollTo(716 * 17, 0).wait(5000).scrollTo(716 * 18, 0).wait(5000).scrollTo(716 * 19, 0).wait(5000).scrollTo(716 * 20, 0).wait(5000)
.evaluate(function () {
let arr_a = document.querySelectorAll(\'div.poi-tile-nodeal\');
let str = \'\';
for (var index = 0; index < arr_a.length; index++) {
var element = arr_a[index];
let sp_rj = element.querySelector(\'div.poi-tile__money span.avg span\');
//人均
let rj = 0;
if (sp_rj != null) {
let str_rj = sp_rj.innerText;
rj = parseInt(str_rj.substr(1, rj.length));
}
console.log(index);
let url = \'\';
let elelink = element.querySelector(\'a.poi-tile__head.J-mtad-link\');
if (elelink != null) {
//链接地址
url = elelink.href;
console.log(url);
}
str += url + \'|\' + rj + \',\';
}
let href = document.querySelector(\'li.next a\') ? document.querySelector(\'li.next a\').href : \'undefined\'
return str + \'^\' + href;
});
console.log(result4);
temp4 = result4.split(\'^\');
nextPage = temp4[1];
arr_a4 = temp4[0].split(\',\');
for (var index4 = 0; index4 < arr_a4.length; index4++) {
var element4 = arr_a4[index4];
if (element4 != \'\') {
try {
let temp = element4.split(\'|\');
let url5 = \'\';
if (temp[0] != \'\') {
url5 = temp[0];
} else {
continue;
}
//获取店铺详细信息
let result5 = yield nightmare
.wait(5000)
.goto(url5)
.wait(\'div.poi-section.poi-section--shop\')
.evaluate(function () {
let query = document.querySelectorAll(\'div.component-bread-nav a\');
let cate = query[2].innerText; console.log(cate);
let area = query[3].innerText; console.log(area);
let poi = \'\';
if (query[4] != undefined) {
poi = query[4].innerText; console.log(poi);
}
query = document.querySelector(\'div.summary\');
let name = query.querySelector(\'h2 span.title\').innerText; console.log(name);
let addr = query.querySelector(\'span.geo\').innerText; console.log(addr);
let tel = query.querySelector(\'div.fs-section__left p:nth-child(3)\').innerText; console.log(tel);
let rate = \'\';
if (query.querySelector(\'span.biz-level strong\') != undefined) {
rate = query.querySelector(\'span.biz-level strong\').innerText; console.log(rate);
}
let rate_count = query.querySelector(\'a.num.rate-count\').innerText; console.log(rate_count);
let recom_food = \'\';
query = document.querySelectorAll(\'div.menu__items table tbody td\');
for (var index = 0; index < query.length; index++) {
var element = query[index];
recom_food += element.innerText + \',\';
}
desc = document.querySelector(\'div.poi-section.poi-section--shop div div\').innerText;
return cate + \'|\' + area + \'|\' + poi + \'|\' + name + \'|\' + addr + \'|\' + tel + \'|\' + rate + \'|\' + rate_count + \'|\' + recom_food + \'|\' + desc
});
console.log(result5);
postResult(result5 + \'|\' + city + \'|\' + temp[1]);
} catch (e) {
console.log(e);
writeLog(stepLog);
continue;
}
}
}
} catch (e) {
console.log(e);
writeLog(stepLog);
continue;
}
} while (nextPage != \'undefined\')
}
}
stepLog.area_index = 1;
} catch (e) {
console.log(e);
writeLog(stepLog);
continue;
}
}
}
stepLog.location_index = 2;
} catch (e) {
console.log(e);
writeLog(stepLog);
continue;
}
}
}
stepLog.cate_index = 2;
}
function postResult (postData) {
options = {
hostname: \'你的提交域名\',
port: 80,
path: \'/admin/test/upload\',
method: \'POST\',
headers: {
\'Content-Type\': \'raw\',
\'Content-Length\': Buffer.byteLength(postData)
}
};
req = http.request(options, (res) => {
//console.log(`STATUS: ${res.statusCode}`);
//console.log(`HEADERS: ${JSON.stringify(res.headers)}`);
res.setEncoding(\'utf8\');
res.on(\'data\', (chunk) => {
console.log(`BODY: ${chunk}`);
});
res.on(\'end\', () => {
console.log(\'No more data in response.\');
});
});
req.on(\'error\', (e) => {
console.error(`problem with request: ${e.message}`);
});
// write data to request body
req.write(postData);
req.end();
}
function writeLog (log) {
fs.writeFileSync(\'./steplog.log\', JSON.stringify(log));
}
function readLog () {
let json = fs.readFileSync(\'./steplog.log\');
return JSON.parse(json);
}
function start () {
co(run).then(function () {
console.log(\'done\');
}).catch(function (err) {
console.log(new Date().toUTCString());
console.error(err);
start();
});
}
start();爬取结果如下:

如有更好的方案,欢迎交流。
附件列表
以上是关于基于nightmare的美团美食商家爬虫实践的主要内容,如果未能解决你的问题,请参考以下文章
基于pandas python的美团某商家的评论销售数据分析(可视化续)
《iVX 高仿美团APP制作移动端完整项目》04 美食页 标题搜索商家标题制作
《iVX 高仿美团APP制作移动端完整项目》05 美食页商家推荐内容分类推荐商家制作