XML的四种解析方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML的四种解析方式相关的知识,希望对你有一定的参考价值。
基础方法: DOM、SAX
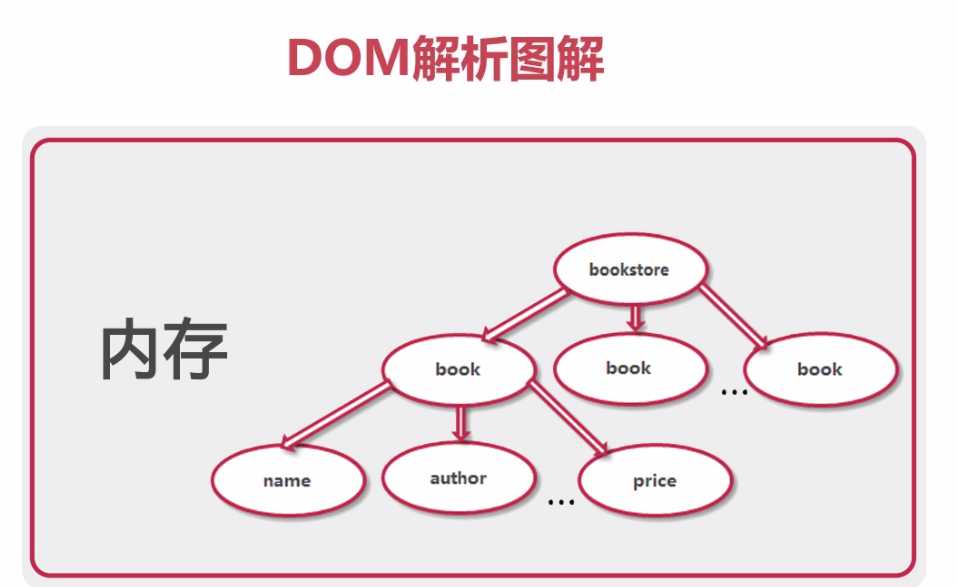
DOM:与平台无关的官方解析方式
SAX:基于事件驱动的解析方式
扩展方法:JDOM、DOM4J(在基础的方法上扩展的,只有Java能够使用的解析方式)
DOM: 一次性解析完毕!
import java.io.FileOutputStream; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; /** * 第六章 简答题1-4 * @author Xuas * */ public class Demo_DOM { Document doc = null; /** * 加载DOM树 */ public void loadDocument() throws Exception { //得到DOM解析器的工厂实例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); //从DOM工厂获得DOM解析器 DocumentBuilder db = dbf.newDocumentBuilder(); //解析XML文档,得到一个Document对象,即DOM树 doc = db.parse("src/com/chapter6/zy/学生信息.xml"); } /** * 显示信息 */ public void showInfo(){ //获取所有student节点集合 NodeList studentList = doc.getElementsByTagName("student"); System.out.println("*******一共有"+studentList.getLength()+"个学生*******"); //遍历每一个student节点 for(int i=0;i<studentList.getLength();i++){ System.out.println("第"+(i+1)+"名学生信息:"); /** * 不确定属性个数时: */ /*//获取第i个student节点 Node studentNode = studentList.item(i); //获取student节点所有属性集合 NamedNodeMap attrs = studentNode.getAttributes(); System.out.println("第"+(i+1)+"个学生共有"+attrs.getLength()+"个属性"); //遍历student的属性 for(int j=0;j<attrs.getLength();j++){ //通过item(index)获取student节点的某一个属性 Node attr = attrs.item(j); //获取属性名 System.out.print("属性名:"+attr.getNodeName()); //获取属性值 System.out.println("==>属性值:"+attr.getNodeValue()); }*/ /** * 确定student节点有且只有一个id属性: */ //将student节点进行强制类型转换,转换成Element类型 Element student = (Element)studentList.item(i); //通过getAttribute("id")方法获取属性值 String attrValue = student.getAttribute("id"); System.out.println("id属性:"+attrValue); //解析student节点的子节点 NodeList stuChildNodes = student.getChildNodes(); //遍历stuChildNodes获取每个节点名和节点值 System.out.println("第"+(i+1)+"个学生共有"+stuChildNodes.getLength()+"个子节点"); for(int k=0;k<stuChildNodes.getLength();k++){ //区分出text类型的node以及element类型的node if(stuChildNodes.item(k).getNodeType() == Node.ELEMENT_NODE){ //获取element类型节点的节点名 System.out.print(stuChildNodes.item(k).getNodeName()); //获取element类型节点的节点值(两种方式) /** * */ //System.out.println(":"+stuChildNodes.item(k).getFirstChild().getNodeValue()); System.out.println(":"+stuChildNodes.item(k).getTextContent()); } } System.out.println("***************************************************"); } } /** * 删除ID为1的成绩 */ public void delete() throws Exception{ NodeList stuList = doc.getElementsByTagName("student"); //找到删除的节点 for(int i=0;i<stuList.getLength();i++){ Element stuEle = (Element)stuList.item(i); //找到ID=1的student节点的成绩子节点 if(stuEle.getAttribute("id").equals("1")){ NodeList childNodes = stuEle.getChildNodes(); for(int j=0;j<childNodes.getLength();j++){ if(childNodes.item(j).getNodeName().equals("score")){ childNodes.item(j).getParentNode().removeChild(childNodes.item(j)); } } } } //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); // 设置编码格式 transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312"); StreamResult result = new StreamResult(new FileOutputStream("src/com/chapter6/zy/学生信息(删除ID为1).xml")); // 把DOM树转换为XML文件 transformer.transform(domSource, result); } /** * 修改ID为2的成绩为60 */ public void modify() throws Exception{ NodeList stuList = doc.getElementsByTagName("student"); //找到要修改的student节点 for(int i=0;i<stuList.getLength();i++){ Element stuEle = (Element)stuList.item(i); //找到ID为2的student节点 if(stuEle.getAttribute("id").equals("2")){ //遍历ID为2的student节点的子节点找到score节点 NodeList childNodes = stuEle.getChildNodes(); for(int j=0;j<childNodes.getLength();j++){ if(childNodes.item(j).getNodeName().equals("score")){ childNodes.item(j).setTextContent("60"); } } } } //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); // 设置编码格式 transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312"); StreamResult result = new StreamResult(new FileOutputStream("src/com/chapter6/zy/学生信息(修改ID为2成绩为60).xml")); // 把DOM树转换为XML文件 transformer.transform(domSource, result); } /** * 添加一个学生信息(ID为3) */ public void add() throws Exception { //创建student节点 Element stuEle = doc.createElement("student"); stuEle.setAttribute("id", "3"); //创建name节点 Element nameEle = doc.createElement("name"); nameEle.setTextContent("王五"); //创建course节点 Element courseEle = doc.createElement("course"); courseEle.setTextContent("英语"); //创建score节点 Element scoreEle = doc.createElement("score"); scoreEle.setTextContent("77"); //添加父子关系 stuEle.appendChild(nameEle); stuEle.appendChild(courseEle); stuEle.appendChild(scoreEle); Element scoresEle = (Element)doc.getElementsByTagName("scores").item(0); scoresEle.appendChild(stuEle); //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); //设置编码格式 transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312"); StreamResult result = new StreamResult(new FileOutputStream("src/com/chapter6/zy/学生信息(添加ID为3学生).xml")); //把DOM树转换为XML文件 transformer.transform(domSource, result); } /** * 测试方法 */ public static void main(String[] args) throws Exception{ Demo_DOM demo = new Demo_DOM(); demo.loadDocument(); //demo.delete(); demo.modify(); demo.add(); demo.showInfo(); } }
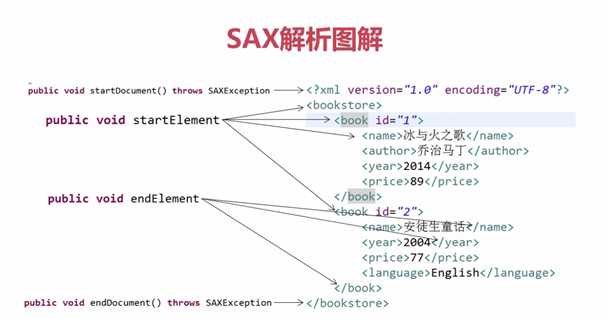
SAX:逐步解析(一个标签一个标签的解析!)
import java.util.ArrayList; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; import com.SAX方式解析XML.entity.Book; public class SAXParserHandler extends DefaultHandler { String value = null; Book book = null; private ArrayList<Book> bookList = new ArrayList<Book>(); public ArrayList<Book> getBookList() { return bookList; } int bookIndex = 0; /** * 用来遍历xml文件的开始标签 */ public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //调用DefaultHandler类的startElement方法 super.startElement(uri, localName, qName, attributes); //开始解析book元素的属性 if(qName.equals("book")){ //创建一个Book对象 book = new Book(); bookIndex++; //已知book元素下属性名称,根据属性名获取属性值 System.out.println("***********开始遍历第"+bookIndex+"本书的内容***********"); /*String value = attributes.getValue("id"); System.out.println("book的属性值是:"+value);*/ int num = attributes.getLength(); for(int i=0;i<num;i++){ System.out.print("book元素的第"+(i+1)+"属性名是:"+attributes.getQName(i)); System.out.println("==>属性值是:"+attributes.getValue(i)); if(attributes.getQName(i).equals("id")){ book.setId(attributes.getValue(i)); } } }else if(!qName.equals("book") && !qName.equals("bookstore")){ System.out.print("节点名是:"+qName+"==>"); } } /** * 用来遍历xml文件的结束标签 */ public void endElement(String uri, String localName, String qName) throws SAXException { //调用DefaultHandler类的endElement方法 super.endElement(uri, localName, qName); //判断是否针对一本书已经遍历结束 if(qName.equals("book")){ bookList.add(book); book = null; System.out.println("***********结束遍历第"+bookIndex+"本书的内容***********"); }else if(qName.equals("name")){ book.setName(value); }else if(qName.equals("author")){ book.setAuthor(value); }else if(qName.equals("year")){ book.setYear(value); }else if(qName.equals("price")){ book.setPrice(value); }else if(qName.equals("language")){ book.setLanguage(value); } } /** * 用来标识解析开始 */ public void startDocument() throws SAXException { super.startDocument(); System.out.println("SAX解析开始"); } /** * 用来标识解析结束 */ public void endDocument() throws SAXException { super.endDocument(); System.out.println("SAX解析结束"); } /** * */ public void characters(char[] ch, int start, int length) throws SAXException { super.characters(ch, start, length); value = new String(ch, start, length); if(!value.trim().equals("")){ System.out.println("节点值是:"+value); } } }
import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import com.SAX方式解析XML.entity.Book; import com.SAX方式解析XML.handler.SAXParserHandler; public class Demo { public static void main(String[] args) throws Exception{ //获取一个SAXParserFactory的实例 SAXParserFactory factory = SAXParserFactory.newInstance(); //通过factory获取SAXParser实例 SAXParser parser = factory.newSAXParser(); //创建SAXParserHandler对象 SAXParserHandler handler = new SAXParserHandler(); parser.parse("books.xml", handler); System.out.println("共有"+handler.getBookList().size()+"本书!"); for (Book book : handler.getBookList()) { System.out.println(book.getId()); System.out.println(book.getName()); System.out.println(book.getAuthor()); System.out.println(book.getYear()); System.out.println(book.getPrice()); System.out.println(book.getLanguage()); System.out.println("--------------finish---------------"); } } }
选择DOM还是SAX??
DOM---优点:
1.形成了树结构,直观好理解,代码更易编写!
2.解析过程中树结构保留在内存中,方便修改!
DOM---缺点:
当xml文件较大时,对内存耗费比较大,容易影响解析性能并造成内存溢出!(内存装不下DOM树了!)
SAX---优点:
1.采用事件驱动模式,对内存耗费比较小!
2.适用于只需要处理xml中数据的情况!
SAX---优点:
1.不易编码!
2.很难同时访问同一个xml中的多处不同数据!
JDOM与DOM、DOM4J
JDOM:
1.仅使用具体类而不使用接口!
2.API大量使用了Collections类!
import java.io.FileInputStream; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List; import org.jdom2.Attribute; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.input.SAXBuilder; import com.JDOM方式解析XML.entity.Book; public class Demo { private static ArrayList<Book> booksList = new ArrayList<Book>(); public static void main(String[] args) throws Exception{ // 进行对books.xml文件的解析 // 1.创建一个SAXBuilder的对象 SAXBuilder saxBuilder = new SAXBuilder(); // 2.创建一个输入流,将xml加载到输入流里来 InputStream in = new FileInputStream("src/res/books.xml"); //处理解析过程中的乱码问题 InputStreamReader isr = new InputStreamReader(in, "UTF-8"); // 3.通过saxBuilder的build()方法,将输入流加载到saxBilder中 Document doc = saxBuilder.build(in); // 4.通过document对象获取xml文件的根节点 Element rootEle = doc.getRootElement(); // 5.获取根节点下的子节点的List集合 List<Element> bookList = rootEle.getChildren(); // 继续进行解析 for (Element book : bookList) { Book bookEntity = new Book(); System.out.println("开始解析第"+(bookList.indexOf(book)+1)+"本书"); // 解析book的属性集合 List<Attribute> attrList = book.getAttributes(); // 知道节点下属性名称时,获取节点值 //book.getAttributeValue("id"); // 遍历attrList(针对不清楚book节点下属性的名字及数量) for (Attribute attr : attrList) { System.out.println("属性名:"+attr.getName()+"==>属性值:"+attr.getValue()); if(attr.getName().equals("id")){ bookEntity.setId(attr.getValue()); } } // 对book节点的子节点的节点名 节点值进行遍历 List<Element> bookChilds = book.getChildren(); for (Element child : bookChilds) { System.out.println("节点名:"+child.getName()+"==>节点值:"+child.getValue()); if(child.getName().equals("name")){ bookEntity.setName(child.getValue()); }else if(child.getName().equals("author")){ bookEntity.setAuthor(child.getValue()); }else if(child.getName().equals("year")){ bookEntity.setYear(child.getValue()); }else if(child.getName().equals("price")){ bookEntity.setPrice(child.getValue()); }else if(child.getName().equals("language")){ bookEntity.setLanguage(child.getValue()); } } System.out.println("结束解析第"+(bookList.indexOf(book)+1)+"本书"); booksList.add(bookEntity); bookEntity = null; /* * 测试是否存储到Book对象中 */ //System.out.println(booksList.size()); //System.out.println(booksList.get(0).getName()); } } }
DOM4J:(在性能上比JDOM高!)
1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能!
2.DOM4J使用接口和抽象基本类方法,是一个优秀的Java XML API!
3.具有性能优异、灵活性好、功能强大和极端易使用的特点!
4.是一个开放源代码的软件!
import java.io.File; import java.util.Iterator; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class Demo { public static void main(String[] args) throws Exception { // 解析books.xml文件 // 创建SAXReader的对象reader SAXReader reader = new SAXReader(); // 通过reader对象的read()方法加载xml文件,获取document对象 Document doc = reader.read(new File("books.xml")); // 通过document对象获取根节点bookstore Element bookStore = doc.getRootElement(); // 通过element对象的elementIterator()方法获取迭代器 Iterator bookStoreIt = bookStore.elementIterator(); // 遍历迭代器,获取根节点中的信息(book) while(bookStoreIt.hasNext()){ System.out.println("=========开始遍历某一本书========="); Element book = (Element)bookStoreIt.next(); List<Attribute> attrs = book.attributes(); for (Attribute attr : attrs) { System.out.println("属性名:"+attr.getName()+"==>属性值:"+attr.getValue()); } Iterator bookIt = book.elementIterator(); while(bookIt.hasNext()){ Element bookChild = (Element)bookIt.next(); System.out.println("节点名:"+bookChild.getName()+"==>节点值:"+bookChild.getStringValue()); } System.out.println("=========结束遍历某一本书========="); } } }
以上是关于XML的四种解析方式的主要内容,如果未能解决你的问题,请参考以下文章