机器学习技法 笔记六 Support Vector Regressssion
Posted 各种控恩恩恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习技法 笔记六 Support Vector Regressssion相关的知识,希望对你有一定的参考价值。
今天要说的是SVR
上一次提到了kernel logistic rgeression
1.kernel ridge regression
同时也提到了,对于任何的L2-regularized linear model,它的w都可以用资料的线性组合来表示
对于以前学的linear regression ,我们的error,是用的squared error,即差值的平方来达到regression
如果把这个regression配合上regularization的话,那么就是ridge regression。
还记得以前我们怎么求linear regression的吗?我们可以直接利用矩阵,一步求出解来。
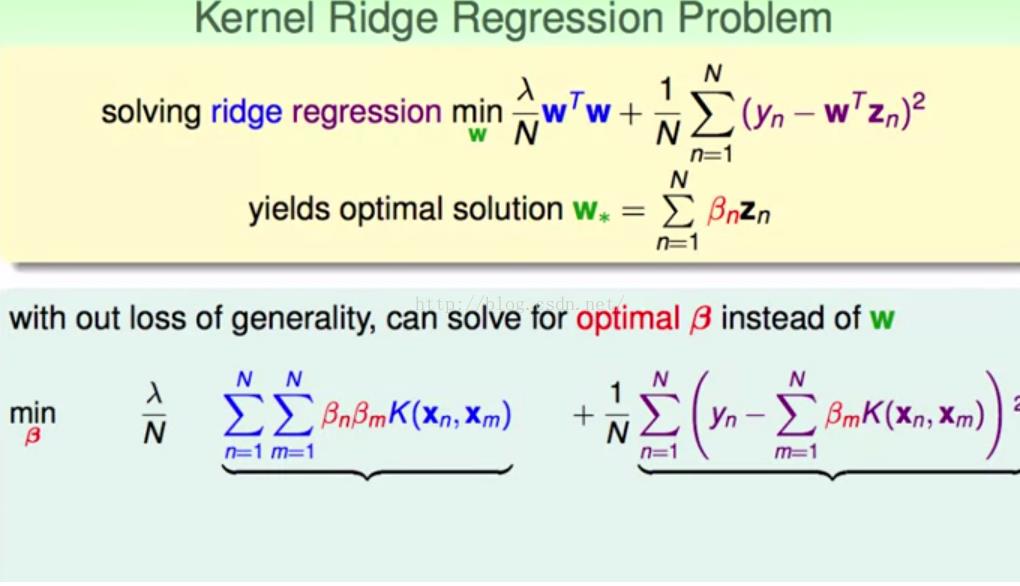
可以看到上半部分的式子就是ridge regression,同时由于我们知道w可以表示成一堆资料的线性组合,同时可以用kernel替换,所以变换可以得到下面部分的式子。
为了方便计算,我们写成矩阵的形式。

这个过程大家算一算就好了,也不复杂。
其实我们可以发现,这就是一个无条件的关于β的二次式,对他求导

求导以后,我们直接就可以解出β,因为K是半正定的,以前讲kernel有介绍的,所以对于γ>0,自然可以求出来了。
对于ridge regression 我们可以和linear regression 的效果对比一下,
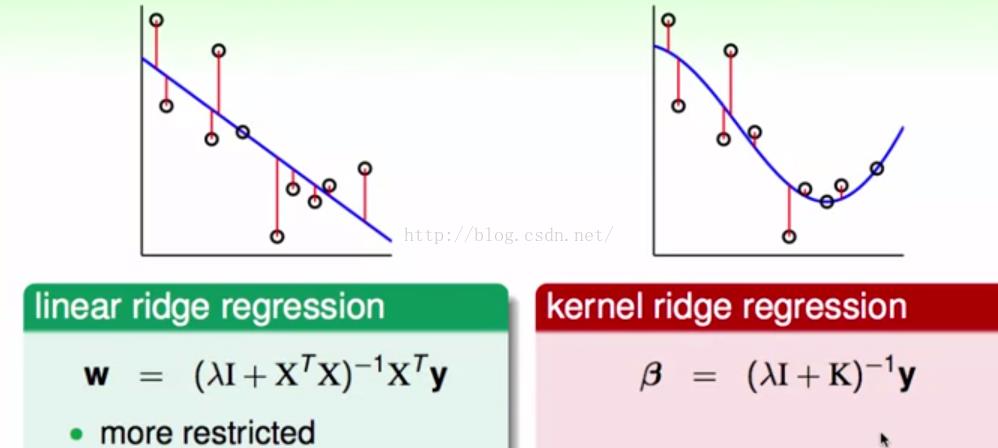
前者还是只能做线性,而后者加入kernel以后显然可以由非线性的区分了。
2.SVR primal
对于上面的ridge regression,我们叫LSSVM,也就是Least-Squares SVM。 SVM就是我们熟悉的SVM,而前者就是指用squares来衡量error。
当然ridge regression(即LSSVM)也可以用来做分类
我们比较一下soft-margin SVM和LSSVM

其实 看边界来说两者差别不大,但是我们可以看到方框框圈出来的点,前面已经说过,方框框圈出来的点是支持向量。
想想为什么,在讲soft-margin SVM的时候,里面的α大多是0,只有在α不是0的情况下,我们才有这个点是支持向量。
而在LSSVM中β基本是非0的,所以支持向量会很多。
支持向量多有什么问题呢?这会导致我们在predicttion 的时候运算量加大。
那么我们如何改变么?让支持向量变少一点。
考虑下图的模型

对于以前的regression问题,我们通常会考虑预测值和实际值差多少来决定扣多少分,现在,我们划分出一个中立区,对于预测值,如果预测出来的结果和y的差距小于等于ε
其实可以看上面图中的err表达就可以了,至于在中立区外面的,那么err就是差值减去ε。
把tube regression联系到SVM上,得到最下面的式子,但是我们知道我们以前解SVM问题,都是用的二次规划的问题,但是这里的max的数学性质并不是那么好。
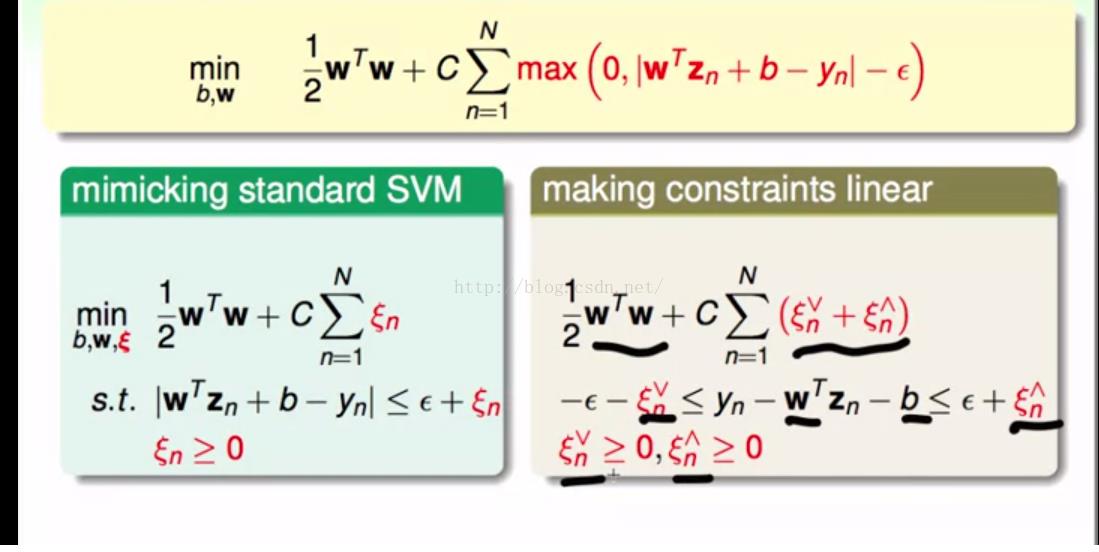
所以像以前解决soft-margin一样,我们引入一个变量,但是由于下面的限制有绝对值,拆开,得到右边的式子,所以最后的结果其实可以写成右边这样。而变量旁边的上下尖就分别代表了tube的上下界。
对于上面的式子,我们完全就可以使用拉格朗日乘子解决了,以前的SVM已经提过很多次,所以这次就直接截图了

左边的是soft-margin,右边的是svr
同时回到最初的问题,就是现在的模型,会不会很是有很多支持向量,其实我们可以在tube内部的点,肯定就不是支持向量了,因为α上和α下都为0,所以对于系数来说为0,所以并不是支持向量,只有在tube外面的才会是支持向量。
下面总结一下我们现在所学的model
显然对于第一排额第二排都是线性的,当然第二排肯定使用的人更多,效果更好。
第三排和第四排,当然更多人会选择第四排,因为前面已经说过,第三排的两个的β算出来很多都不是0,所以会导致计算了变大。
以上是关于机器学习技法 笔记六 Support Vector Regressssion的主要内容,如果未能解决你的问题,请参考以下文章
2.机器学习技法- Dual Support Vector Machine
机器学习技法:04 Soft-Margin Support Vector Machine
机器学习技法--Linear Support Vector Machine
机器学习技法--Kernel Support Vector Machine